在整个spark任务的编写、提交、执行分三个部分:
① 编写程序和提交任务到集群中
②sparkContext的初始化
③触发action算子中的runJob方法,执行任务
①编程spark程序的代码
②打成jar包到集群中运行
③使用spark-submit命令提交任务
在提交任务时,需要指定 --class 程序的入口(有main方法的类),
1) spark-submit --class xxx
2) ${SPARK_HOME}/bin/spark-class org.apache.spark.deploy.SparkSubmit $@
3) org.apache.spark.launcher.Main
submit(appArgs, uninitLog)
doRunMain()
runMain(childArgs, childClasspath, sparkConf, childMainClass, args.verbose)
childMainClass:…./.WordCount (自己编写的代码的主类)
mainClass = Utils.classForName(childMainClass)
val app: SparkApplication = if() {} else {new JavaMainApplication(mainClass)}
app.start(childArgs.toArray, sparkConf) // 通过反射调用mainClass执行
// 到此为止,相当于调用了我们的自己编写的任务类的main方法执行了。!!!
val mainMethod = klass.getMethod("main", new ArrayString.getClass)
mainMethod.invoke(null, args)
④开始执行自己编写的代码
当自己编写的程序运行到:new SparkContext()时,就开始了精妙而细致的sparkContext的初始化。
sparkContext的相关介绍:sparkContext是用户通往spark集群的唯一入口,可以用来在spark集群中创建RDD、累加器和广播变量。sparkContext也是整个spark应用程序的一个至关重要的对象,是整个应用程序运行调度的核心(不是资源调度的核心)。在初始化sparkContext时,同时的会初始化DAGScheduler、TaskScheduler和SchedulerBackend,这些至关重要的对象。
sparkContext的构建过程: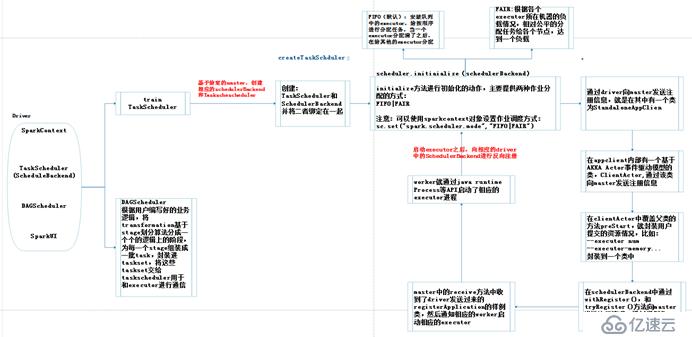
初始化 TaskScheduler
初始化 SchedulerBackend
初始化 DAGScheduler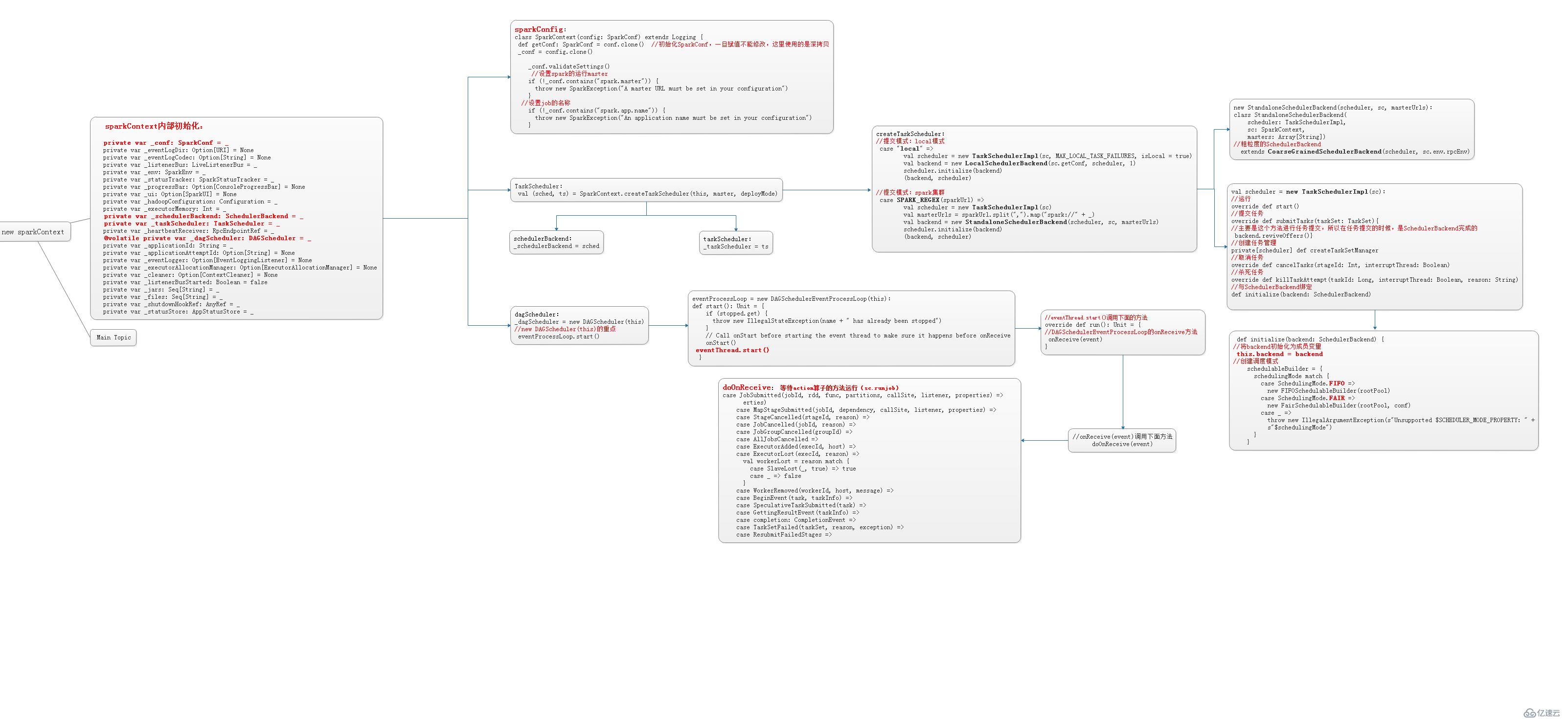
driver向master注册申请资源。
Worker负责启动executor。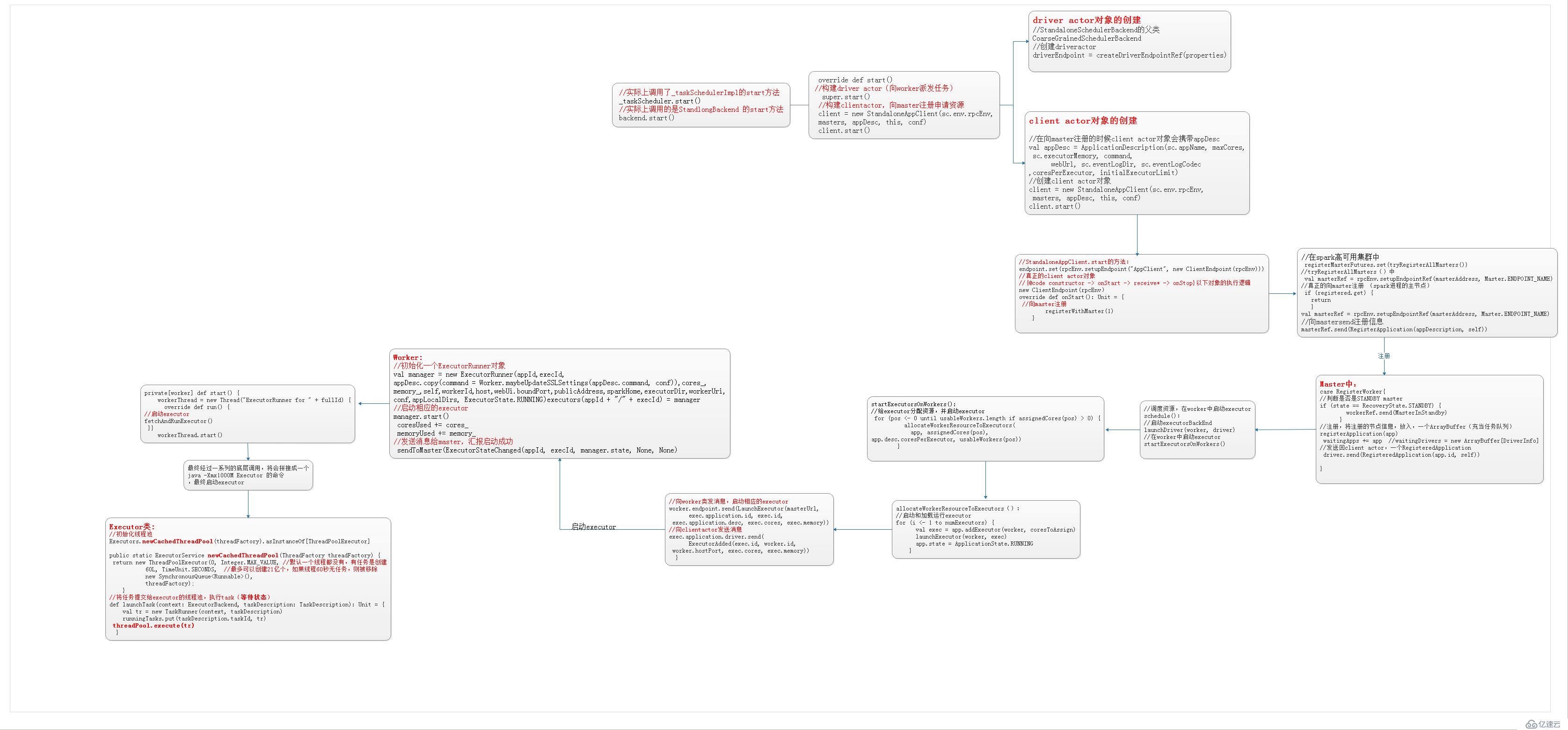

亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



