这篇文章给大家介绍One Hot编码指的是什么,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
当你在玩ML模型的时候,你会在任何地方遇到这个“One hot encoding”的术语。
当你在玩ML模型的时候,你会在任何地方遇到这个“One hot encoding”术语。你可以看到一个one hot编码器的sklearn文档,其中说“使用one-hot也就是one-of- k模式编码分类整数特征”。不是很清楚,对吧?或者至少不适合我。让我们看看one hot编码到底是什么。
One hot编码方法是将分类变量转换成一种形式,这种形式可以提供给ML算法,以便更好地进行预测。
假设数据集如下:
╔════════════╦═════════════════╦════════╗
║ CompanyName Categoricalvalue ║ Price ║
╠════════════╬═════════════════╣════════║
║ VW ╬ 1 ║ 20000 ║
║ Acura ╬ 2 ║ 10011 ║
║ Honda ╬ 3 ║ 50000 ║
║ Honda ╬ 3 ║ 10000 ║
╚════════════╩═════════════════╩════════╝分类值表示数据集中条目的数值。例如:如果数据集中有另一家公司,它的分类值应该是4。随着惟一条目数量的增加,分类值也相应地增加。
上表只是一种表示。实际上,分类值从0开始一直到N-1个类别。
你可能已经知道,可以使用sklearn的LabelEncoder完成分类值分配。
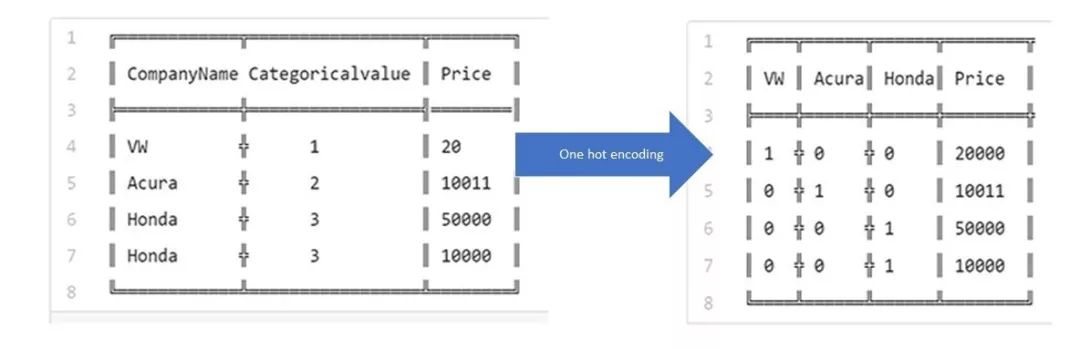
现在让我们回到one hot编码:假设我们按照sklearn文档中给出的说明来进行one hot编码,然后进行一些清理,最后得到以下结果:
╔════╦══════╦══════╦════════╦
║ VW ║ Acura║ Honda║ Price ║
╠════╬══════╬══════╬════════╬
║ 1 ╬ 0 ╬ 0 ║ 20000 ║
║ 0 ╬ 1 ╬ 0 ║ 10011 ║
║ 0 ╬ 0 ╬ 1 ║ 50000 ║
║ 0 ╬ 0 ╬ 1 ║ 10000 ║
╚════╩══════╩══════╩════════╝在我们进一步讨论之前,你能想到一个原因吗?为什么仅仅使用标签编码给模型训练是不够的?为什么需要one hot编码?
标签编码的问题是,它假定类别值越高,类别越好。“等等,什么! ?”
让我解释一下:这种组织形式的前提是基于类比的值,VW > Acura > Honda。假设你的模型内部计算平均值,那么我们得到,1+3 = 4/2 =2。这意味着:VW 和Honda的平均水平是 Acura。这绝对是个灾难。这个模型的预测会有很多误差。
这就是为什么我们使用one hot编码器来执行类别的“二值化”,并将其作为一个特征来训练模型。
另一个例子:假设你有一个“flower”特征,它可以接受“daffodil”、“lily”和“rose”的值。一个one hot编码将“flower”特征转换为三个特征,“is_daffodil”、“is_lily”和“is_rose”,它们都是二进制的。
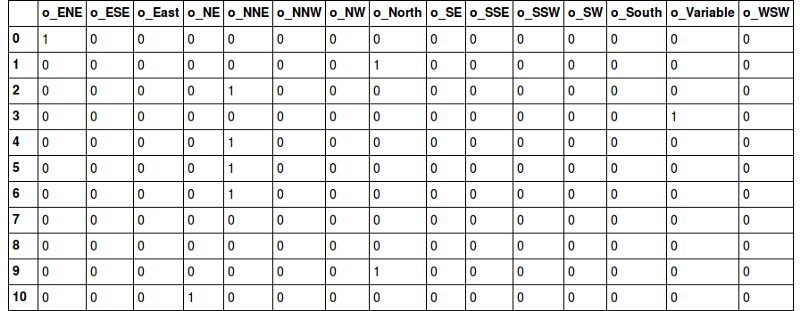
见下图:
关于One Hot编码指的是什么就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





