最近不少网友向我咨询如何学习大数据技术?大数据怎么入门?怎么做大数据分析?数据科学需要学习那些技术?大数据的应用前景等等问题。由于大数据技术涉及内容太庞杂,大数据应用领域广泛,而且各领域和方向采用的关键技术差异性也会较大,难以三言两语说清楚,本文从数据科学和大数据关键技术体系角度,来说说大数据的核心技术什么,到底要怎么学习它,以及怎么避免大数据学习的误区,以供参考。
1.大数据应用的目标是普适智能
要学好大数据,首先要明确大数据应用的目标,我曾经讲过大数据就好比万金油,像百度几年前提的框计算,这个框什么都能往里装。为什么会这样,因为大数据这个框太大,其终极目标是利用一系列信息技术实现海量数据条件下的人类深度洞察和决策智能化,最终走向普适的人机智能融合!这不仅是传统信息化管理的扩展延伸,也是人类社会发展管理智能化的核心技术驱动力。通过大数据应用,面向过去,发现数据规律,归纳已知;面向未来,挖掘数据趋势,预测未知。从而提高人们对事物的理解和决策处置能力,最终实现社会的普适智能。不管是商业智能,机器智能,人工智能,还是智能客服,智能问答,智能推荐,智慧医疗、智慧交通等相关技术和系统,其本质都是朝着这一目标在演进。随着云计算平台和大数据技术的高速发展,获得大数据基础设施建设相关技术和支持越来越容易。同时,移动互联网和物联网技术所具备的全面数据采集能力,客观上促进了大数据的积累和爆发。总之大数据就是个大框,什么都能往里装,大数据源的采集如果用传感器的话离不开物联网、大数据源的采集用智能手机的话离不开移动互联网,大数据海量数据存储要高扩展就离不开云计算,大数据计算分析采用传统的机器学习、数据挖掘技术会比较慢,需要做并行计算和分布式计算扩展,大数据要自动特征工程离不开深度学习、大数据要互动展示离不开可视化,而面向特定领域和多模态数据的大数据分析技术更是十分广泛,金融大数据、交通大数据、医疗大数据、安全大数据、电信大数据、电商大数据、社交大数据,文本大数据、图像大数据、视频大数据…诸如此类等等范围太广,所以首先我们要搞清楚大数据应用的核心目标,这个明确之后,才利于结合不同行业特点把握住共性关键技术,从而有针对性的学习。
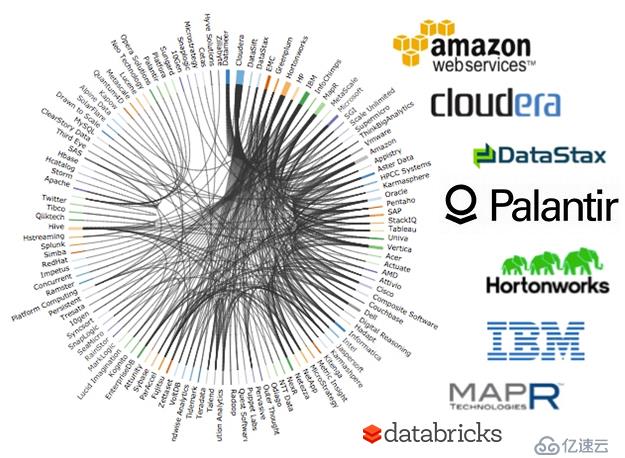
图1 国外大数据企业关系图,传统信息技术企业也在向智能化发展,与新兴大数据企业互为竞争和支持。
2.从大数据版图看数据科学及其关键技术体系
明确大数据应用目标之后,我们再看看数据科学(Data Science),数据科学可以理解为一个跨多学科领域的,从数据中获取知识的科学方法,技术和系统集合,其目标是从数据中提取出有价值的信息,它结合了诸多领域中的理论和技术,包括应用数学,统计,模式识别,机器学习,人工智能,深度学习,数据可视化,数据挖掘,数据仓库,以及高性能计算等。图灵奖得主Jim Gray把数据科学喻为科学的“第四范式”(经验、理论、计算和数据驱动),并断言因为信息技术的影响和数据的泛滥增长,未来不管什么领域的科学问题都将由数据所驱动。
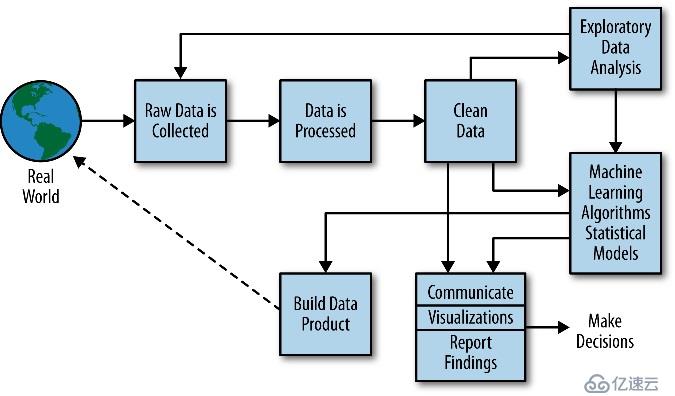
图2 典型的数据科学过程:包括原始数据采集,数据预处理和清洗,数据探索式分析,数据计算建模,数据可视化和报表,数据产品和决策支持等。
传统信息化技术多是在结构化和小规模数据上进行计算处理,大数据时代呢,数据变大了,数据多源异构了,需要智能预测和分析支持了,所以核心技术离不开机器学习、数据挖掘、人工智能等,另外还需考虑海量数据的分布式存储管理和机器学习算法并行处理,所以数据的大规模增长客观上促进了DT(Data Technology)技术生态的繁荣与发展,包括大数据采集、数据预处理、分布式存储、NOSQL数据库、多模式计算(批处理、在线处理、实时流处理、内存处理)、多模态计算(图像、文本、视频、音频)、数据仓库、数据挖掘、机器学习、人工智能、深度学习、并行计算、可视化等各种技术范畴和不同的层面。可见DT这种新技术泛型生态下的大数据版图十分庞杂,当然也有泡沫的成分存在,这个版图也会时刻处于变化之中,就像PC时代的应用程序,互联网上的网站,移动互联网的APP,大数据时代的技术和产品也正处于优胜劣汰的过程。下面我们来看2017版的大数据版图:
欢迎加入大数据交流群:658558542 一起吹水交流学习
图3 国外和国内中关村大数据产业版图(包括数据、技术、应用、企业等)
上述大数据版图基本涵盖了国外大数据相关技术和产业链(国内中关村版的大数据技术和企业还是太少,多是传统信息技术企业在凑数),从大数据源,开源技术框架,大数据基础设施建设,大数据核心的计算挖掘分析,大数据行业应用等方面进行了相关技术、产品和企业的展示。大数据产业链从数据源〉开源技术〉基础设施〉分析计算〉行业应用到产品落地,每个链条环节和下辖的细分内容都涉及大量数据分析技术。不管是学习技术还是开发产品,分析和理解这个大数据产业版图都十分必要。版图细节不做赘述,我们重点从学习的角度来看DT(Data technology)技术泛型下包括那些核心技术,各技术领域之间是什么样的逻辑关系,这是学习大数据首先要搞清楚的问题:
(1)机器学习(machine learning):首先我们说说机器学习,为什么先说它,因为机器学习是大数据处理承上启下的关键技术,机器学习往上是深度学习、人工智能,机器学习往下是数据挖掘和统计学习。机器学习属于计算机和统计学交叉学科,核心目标是通过函数映射、数据训练、最优化求解、模型评估等一系列算法实现让计算机拥有对数据进行自动分类和预测的功能,机器学习领域包括很多种类的智能处理算法,分类、聚类、回归、相关分析等每类下面都有很多算法进行支撑,如SVM,神经网络,Logistic回归,决策树、EM、HMM、贝叶斯网络、随机森林、LDA等,无论是网络排名的十大算法还是二十大算法,都只能说是冰山一角,随着深度学习核心技术的突破性发展,机器学习算法得以高速扩张;总之大数据处理要智能化,机器学习是核心的核心,深度学习、数据挖掘、商业智能、人工智能,大数据等概念的核心技术就是机器学习,机器学习用于图像处理和识别就是机器视觉,机器学习用于模拟人类语言就是自然语言处理,机器视觉和自然语言处理也是支撑人工智能的核心技术,机器学习用于通用的数据分析就是数据挖掘。深度学习(deep learning)是机器学习里面现在比较火的一个子领域,属于原来人工神经网络算法的一系列变种,由于在大数据条件下图像,语音识别等领域的学习效果显著,有望成为人工智能取得突破的关键性技术,所以各大研究机构和IT巨头们都对其投入了极大的关注。
(2)数据挖掘(data mining),数据挖掘可以说是机器学习的一个超集,是一个较为宽泛的概念,类似于采矿,要从大量矿石里面挖出宝石,从海量数据里面挖掘有价值有规律的信息同理。数据挖掘核心技术来自于机器学习领域,如深度学习是机器学习中一类比较火的算法,当然也可以用于数据挖掘。还有传统的商业智能(BI)领域也包括数据挖掘,OLAP多维数据分析可以做挖掘分析,甚至Excel基本的统计分析也可以做挖掘。关键是你的技术能否真正挖掘出有用的信息,然后这些信息可以指导决策。数据挖掘的提法比机器学习要早,应用范围要广,数据挖掘和机器学习是大数据分析的核心技术,互为支撑,为大数据处理提供相关模型和算法,而模型和算法是大数据处理的关键,探索式交互式分析、可视化分析、数据的采集存储和管理等都较少用到学习模型。
(3)人工智能(artifical intelligence),AI和大数据是相互促进的关系,一方面,AI基础理论技术的发展为大数据机器学习和数据挖掘提供了更丰富的模型和算法,如近几年的深度学习一系列技术(强化学习、对抗学习等)和方法;另一方面,大数据为AI的发展提供了新的动力和燃料,数据规模大了之后,传统机器学习算法面临挑战,要做并行化、要加速要改进。AI的终极目标是机器智能化拟人化,机器能完成和人一样的工作,人脑仅凭几十瓦的功率,能够处理种种复杂的问题,怎样看都是很神奇的事情。虽然机器的计算能力比人类强很多,但人类的理解能力,感性的推断,记忆和幻想,心理学等方面的功能,机器是难以比肩的,所以机器要拟人化很难单从技术角度把人工智能讲清楚。人工智能与机器学习的关系,两者的相当一部分技术、算法都是重合的,深度学习在计算机视觉和×××走步等领域取得了巨大的成功,比如谷歌自动识别一只猫,谷歌的AlpaGo还击败了人类顶级的专业围棋手等。但深度学习在现阶段还不能实现类脑计算,最多达到仿生层面,情感,记忆,认知,经验等人类独有能力机器在短期难以达到。
(4)其它大数据处理基础技术,如图4,大数据基础技术包括计算机科学相关如编程、云计算、分布式计算、系统架构设计等方向,还有机器学习的理论基础包括如算法、数据结构、概率论、代数、矩阵分析、统计学习、特征工程等方面;商业分析与理解如领域知识管理、产品设计、可视化等技术;数据管理如数据采集、数据预处理、数据库、数据仓库、信息检索、多维分析、分布式存储等技术。这些理论与技术是为大数据的基础管理、机器学习和应用决策等多个方面服务的。欢迎加入大数据交流群:658558542 一起吹水交流学习

欢迎加入大数据交流群:658558542 一起吹水交流学习
图4 数据科学的技术维度
上图是数据科学的5个技术维度,基本涵盖了数据科学的关键支撑技术体系,从数据管理、计算机科学基础理论技术、数据分析、商业理解决策与设计几个方面进行了数据科学相关技术的梳理,其中计算机科学基础理论方法与数据分析两个板块的学习内容是最多的,也是最重要的。现阶段的大数据产品和服务多是在数据管理版块,分析板块和业务决策板块的对接是数据科学和大数据产业后续发展的关键突破点。
另外图中的Art&Design版块只列了交通沟通和可视化,其实还不够,这个艺术(Art)还说明了数据科学与传统信息化技术的本质不同,数据科学的核心能力是根据问题提出设想,再把设想转化为学习模型,这种能力是要讲艺术的,没有这样的设计艺术,计算机要智能化不是那么容易。为什么上升为艺术了?因为经验告诉我们,把现实问题转化为模型没有标准答案,可选的模型不只一种,技术路线多样,评价指标也有多个维度,甚至优化方法也有很多种,机器学习的本质就是在处理这门艺术,给定原始数据、限制条件和问题描述,没有标准答案,每种方案的选择就是一种设想假设,需要具备利用精确的测试和实验方法来验证和证伪这些假设的能力,从这个层面讲,未来所有科学问题以及商业、政府管理决策问题都将是数据科学问题,而机器学习是数据科学的核心。
3.大数据盲人摸象:如何构建完整的知识结构和分析能力
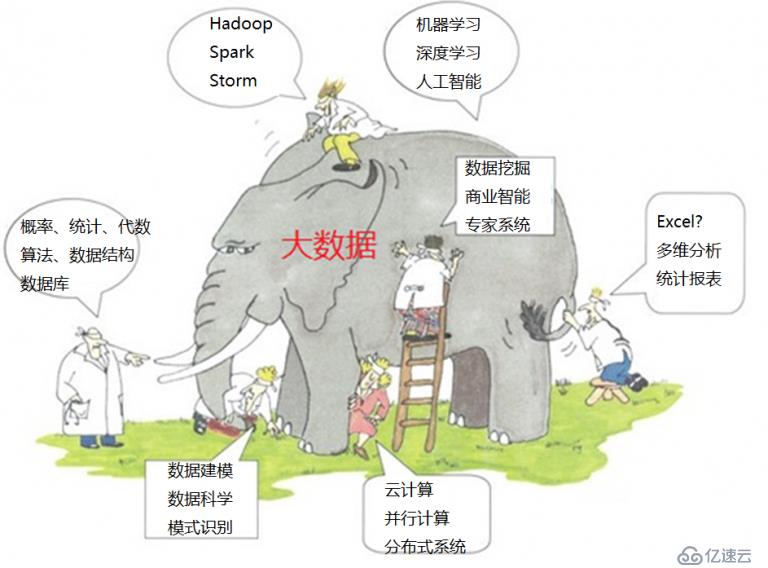
从数字化、信息化、网络化到未来的智能化时代,移动互联网、物联网、云计算、大数据、人工智能等前沿信息技术领域,逐个火了一遍。也代表了信息技术发展的大趋势,什么是大数据,大数据的技术范畴及其逻辑关系,估计很多人都是根据自己所熟悉的领域在盲人摸象(如图5)。其实我这里讲的盲人摸象并不是贬义,毕竟一个领域的学习到精通就是从盲人摸象式开始的。大数据、数据科学都是很虚的一个概念,分析目标和采用技术都包罗万象,就好比写程序,分前端和后端,分B/S和C/S,分嵌入式、企业应用和APP等,开发语言更是有数十种,不同方向所需要的技术也是大不相同。
欢迎加入大数据交流群:658558542 一起吹水交流学习
图5 大数据盲人摸象
所以怎么从点到面,构建大数据领域完整的知识结构和分析能力至关重要,某方面的技术和语言只是工具而已。大数据知识结构,就是既有精深的大数据基础理论知识,又有广博的知识面和应用全局观,具有大数据产业发展所需要的最合理、最优化、最关键的核心技术与知识体系。通过合理的知识结构和科学的大数据思维方法,提高大数据分析实战技能。这个目标很大,但还是可以达到的,首先要搞清楚大数据产业链的情况,接下来要明确大数据技术栈也就是相关技术体系,最后定下学习目标和应用方向,是面对什么行业的数据,是关注存储还是机器学习,数据规模是什么量级,数据类型是文本、图像、网页还是商业数据库?每个方向所用技术有较大差异,需要找准学习的兴趣点和切入点。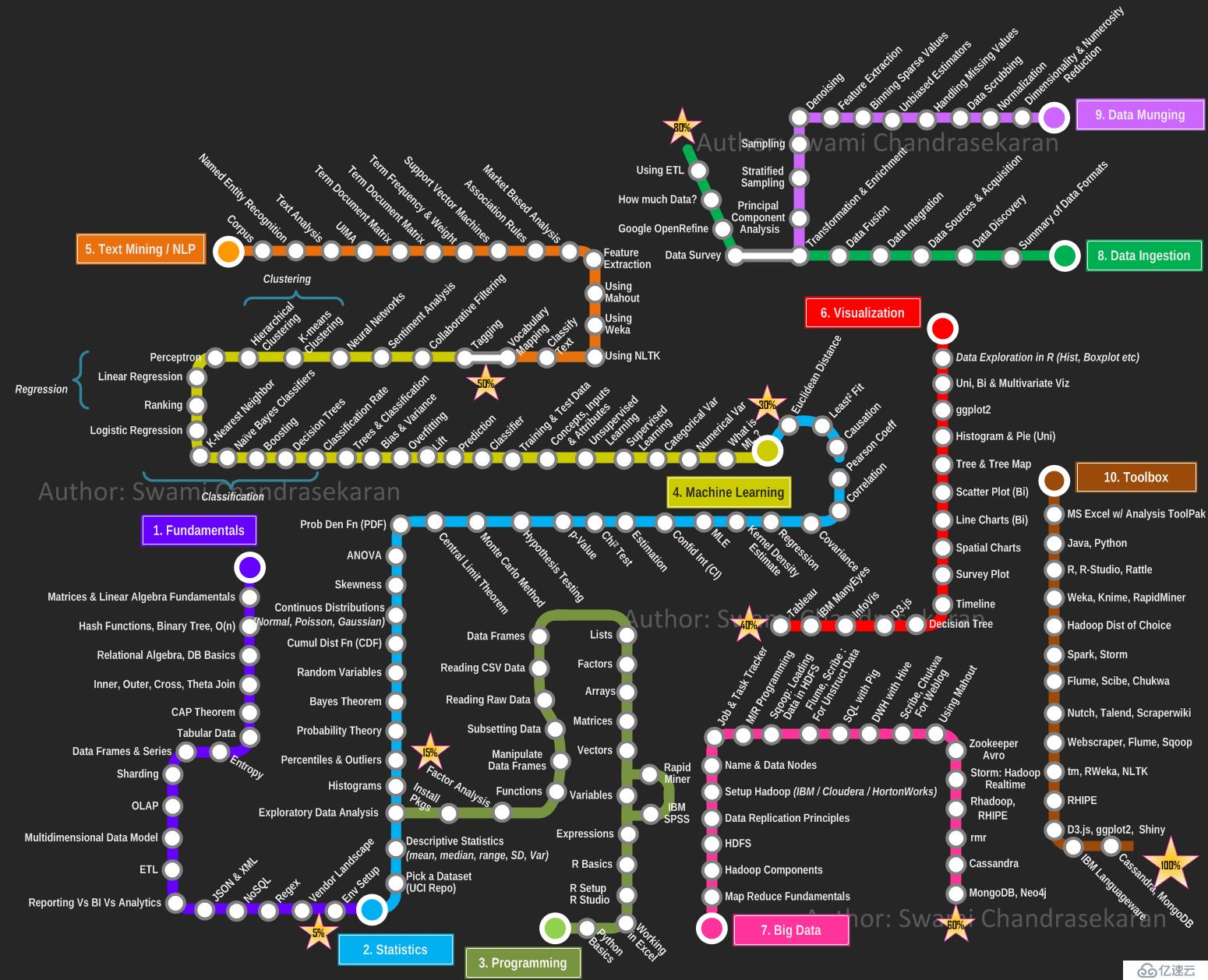
图6 大数据技术栈与学习路线参考图
上面这个大数据技术栈和学习路线图,可以说是一个大数据学习的总纲,专业性很强,值得初学者深入研究和理解,对我在前面提到的数据科学技术体系来讲,是更丰富的补充。比如基础学习部分包括线性代数、关系代数、数据库基础、CAP理论、OLAP、多维数据模型、数据预处理ETL等都分析得很到位。总之大数据学习不能像炒菜一样,等到把所有材料准备好了才下锅(因为这个领域技术体系庞杂应用目标广泛,就算学个十年二十年也难以掌握其大部分核心理论技术),而是结合自己的兴趣或工作需求,找一个点猛扎进去,掌握这个点的相关技术,深入理解其分析的流程、应用和评价等环节,搞透彻一个点之后,再以点带面,举一反三,逐步覆盖大数据各个领域,从而构建完整的知识结构和技术能力体系,这才是大数据学习的最佳路径。
4.大数据要怎么学:数据科学特点与大数据学习误区
(1)大数据学习要业务驱动,不要技术驱动:数据科学的核心能力是解决问题。
大数据的核心目标是数据驱动的智能化,要解决具体的问题,不管是科学研究问题,还是商业决策问题,抑或是政府管理问题。所以学习之前要明确问题,理解问题,所谓问题导向、目标导向,这个明确之后再研究和选择合适的技术加以应用,这样才有针对性,言必hadoop,spark的大数据分析是不严谨的。不同的业务领域需要不同方向理论、技术和工具的支持。如文本、网页要自然语言建模,随时间变化数据流需要序列建模,图像音频和视频多是时空混合建模;大数据处理如采集需要爬虫、倒入导出和预处理等支持,存储需要分布式云存储、云计算资源管理等支持,计算需要分类、预测、描述等模型支持,应用需要可视化、知识库、决策评价等支持。所以是业务决定技术,而不是根据技术来考虑业务,这是大数据学习要避免的第一个误区。
(2)大数据学习要善用开源,不要重复造轮子:数据科学的技术基因在于开源。
IT前沿领域的开源化已成不可逆转的趋势,Android开源让智能手机平民化,让我们跨入了移动互联网时代,智能硬件开源将带领跨入物联网时代,以Hadoop和Spark为代表的大数据开源生态加速了去IOE(IBM、ORACLE、EMC)进程,倒逼传统IT巨头拥抱开源,谷歌和OpenAI联盟的深度学习开源(以Tensorflow,Torch,Caffe等为代表)正在加速人工智能技术的发展。数据科学的标配语言R和Python更是因开源而生,因开源而繁荣,诺基亚因没把握开源大势而衰落。为什么要开源,这得益于IT发展的工业化和构件化,各大领域的基础技术栈和工具库已经很成熟,下一阶段就是怎么快速组合、快速搭积木、快速产出的问题,不管是linux,anroid还是tensorflow,其基础构件库基本就是利用已有开源库,结合新的技术方法实现,组合构建而成,很少在重复造轮子。另外,开源这种众包开发模式,是一种集体智慧编程的体现,一个公司无法积聚全球工程师的开发智力,而一个GitHub上的明星开源项目可以,所以要善用开源和集体智慧编程,而不要重复造轮子,这是大数据学习要避免的第二个误区。
(3)大数据学习要以点带面,不要贪大求全:数据科学要把握好碎片化与系统性。
根据前文的大数据技术体系分析,我们可以看到大数据技术的深度和广度都是传统信息技术难以比拟的。我们的精力很有限,短时间内很难掌握多个领域的大数据理论和技术,数据科学要把握好碎片化和系统性的关系。何为碎片化,这个碎片化包括业务层面和技术层面,大数据不只是谷歌,亚马逊,BAT等互联网企业,每一个行业、企业里面都有它去关注数据的痕迹:一条生产线上的实时传感器数据,车辆身上的传感数据,高铁设备的运行状态数据,交通部门的监控数据,医疗机构的病例数据,政府部门的海量数据等等,大数据的业务场景和分析目标是碎片化的,而且相互之间分析目标的差异很大;另外,技术层面来讲,大数据技术就是万金油,一切服务于数据分析和决策的技术都属于这个范畴,其技术体系也是碎片化的。那怎么把握系统性呢,不同领域的大数据应用有其共性关键技术,其系统技术架构也有相通的地方,如系统的高度可扩展性,能进行横向数据大规模扩张,纵向业务大规模扩展,高容错性和多源异构环境的支持,对原有系统的兼容和集成等等,每个大数据系统都应该考虑上述问题。如何把握大数据的碎片化学习和系统性设计,离不开前面提出的两点误区,建议从应用切入、以点带面,先从一个实际的应用领域需求出发,搞定一个一个技术点,有一定功底之后,再举一反三横向扩展逐步理解其系统性技术。
(4)大数据学习要勇于实践,不要纸上谈兵:数据科学还是数据工程?
大数据只有和特定领域的应用结合起来才能产生价值,数据科学还是数据工程是大数据学习要明确的关键问题,搞学术发paper数据科学OK,但要大数据应用落地,如果把数据科学成果转化为数据工程进行落地应用,难度很大,这也是很多企业质疑数据科学价值的原因。且不说这种转化需要一个过程,从业人员自身也是需要审视思考的。工业界包括政府管理机构如何引入研究智力,数据分析如何转化和价值变现?数据科学研究人员和企业大数据系统开发工程人员都得想想这些关键问题。目前数据工程要解决的关键问题主线是数据(Data)>知识(Knowledge)>服务(Service),数据采集和管理,挖掘分析获取知识,知识规律进行决策支持和应用转化为持续服务。解决好这三个问题,才算大数据应用落地,那么从学习角度讲,DWS就是大数据学习要解决问题的总目标,特别要注重数据科学的实践应用能力,而且实践要重于理论。从模型,特征,误差,实验,测试到应用,每一步都要考虑是否能解决现实问题,模型是否具备可解释性,要勇于尝试和迭代,模型和软件包本身不是万能的,大数据应用要注重鲁棒性和实效性,温室模型是没有用的,训练集和测试集就OK了吗?大数据如何走出实验室和工程化落地,一是不能闭门造车,模型收敛了就想当然万事大吉了;二是要走出实验室充分与业界实际决策问题对接;三是关联关系和因果关系都不能少,不能描述因果关系的模型无助于解决现实问题;四是注重模型的迭代和产品化,持续升级和优化,解决新数据增量学习和模型动态调整的问题。所以,大数据学习一定要清楚我是在做数据科学还是数据工程,各需要哪些方面的技术能力,现在处于哪一个阶段等,不然为了技术而技术,是难以学好和用好大数据的。欢迎加入大数据交流群:658558542 一起吹水交流学习
(5)大数据学习的三个阶段:不同阶段的技术路线各有侧重,把握主要矛盾。
在大数据应用实施过程中,由于技术和成本考虑,不可能短时间内解决所有问题,大数据应用本身有其规律和特点,比如分析目标一定是要跟数据规模匹配,分析技术的采用取决于数据结构和数据源条件,数据集成一定要覆盖比较全面的业务背景,关键环节数据不能有缺失等等。大数据学习可以根据应用目标分三个阶段:
1)大数据基础设施建设阶段:这个阶段的重点是把大数据存起来,管起来,能用起来,同时要考虑大数据平台和原有业务系统的互通联合问题。一句话,做好全局数据集成解决数据孤岛问题!要完成大数据基础设施系统建设开发,需要明确数据采集、存储和分析各层核心组件的选型和使用,搭建稳定的大数据集群,或选择私有云方案的服务集群,与生产系统并线运行,使待分析的历史数据和实时数据得以采集并源源不断流入大数据系统。这个阶段的关键技术学习包括采集爬虫、数据接口、分布式存储、数据预处理ETL、数据集成、数据库和数据仓库管理、云计算和资源调度管理等等内容。
2)大数据描述性分析阶段:此阶段主要定位于离线或在线对数据进行基本描述统计和探索式可视化分析,对管理起来的大数据能进行海量存储条件下的交互式查询、汇总、统计和可视化,如果建设了BI系统的,还需整合传统BI技术进行OLAP、KPI、Report、Chart、Dashboard等分析和初步的描述型数据挖掘分析。这个基础分析阶段是对数据集成质量的检验,也是对海量数据条件下的分布式存储管理技术应用稳定性的测试,同时要能替代或集成传统BI的各类报表。这个阶段的关键技术学习包括可视化、探索式交互式分析、多维分析、各类基本报表和图表的查询设计等等。
3)大数据高级预测分析和生产部署阶段:在初步描述分析结果合理,符合预期目标,数据分布式管理和描述型分析稳定成熟的条件下,可结合进一步智能化分析需求,采用如深度学习等适用海量数据处理的机器学习模型,进行高级预测性挖掘分析。并通过逐步迭代优化挖掘模型和数据质量,形成稳定可靠和性能可扩展的智能预测模型,并在企业相关业务服务中进行分析结果的决策支持,进行验证、部署、评估和反馈。这个阶段的关键技术包括机器学习建模、决策支持、可视化、模型部署和运维等。
在上述几个阶段的技术学习过程中,需要注意几个关键问题:一是重视可视化和业务决策,大数据分析结果是为决策服务,而大数据决策的表现形式,可视化技术的优劣起决定性作用;二是问问自己,Hadoop、Spark等是必须的吗?要从整个大数据技术栈来考虑技术选型和技术路线的确定;三是建模问题处于核心地位,模型的选择和评估至关重要,在课堂和实验室中,多数模型的评估是静态的,少有考虑其运行速度、实时性及增量处理,因此多使用复杂的臃肿模型,其特征变量往往及其复杂。而Kaggle竞赛中的各种Boost方法,XGBDT、随机森林等模型,在数据挖掘和机器学习教材中却少有提及,所以要充分参考业界实战经验不能尽信书;四是开发语言的选择,基础框架系统Java是必须掌握的,应用级的机器学习和数据分析库Python是必须掌握的,而要深入各种框架和学习库的底层,C++是必须掌握的;五是模型的产品化,需要将实际数据通过管道设计转换为输入特征传递给模型,如何最小化模型在线上和线下的表现差距,这些都是要解决关键的问题。
(6)其它补充:Kaggle,众包与培训。众包是一种基于互联网的创新生产组织形式,企业利用网络将工作分配出去,通过让更合适的人群参与其中来发现创意和解决问题,如维基百科,还有IT资源社区GitHub,都是典型的众包平台。众包+开源极大推动了IT产业的快速发展,当然Kaggle作为数据科学领域顶级的众包平台,其影响力远不止于此(所以刚刚被谷歌收购)。企业和研究者可在Kaggle上发布数据,数据分析人员可在其上进行竞赛以产生最好的模型。这一众包模式本质就是集体智慧编程的体现,即有众多策略可以用于解决几乎所有预测建模问题,而分析人员不可能一开始就能找到最佳方案,Kaggle的目标就是通过众包的形式来解决这一难题,进而使数据科学成为一场集体智慧运动。所以说要学好大数据,严重推荐去Kaggle冲冲浪,很好的历练平台。至于大数据培训嘛,基础理论和技术还不甚了解的情况下可以去培训学习,有基础之后还得靠自己多练多解决实际问题。欢迎加入大数据交流群:658558542 一起吹水交流学习
5.结论与展望
做个小结,大数据不是银弹(Silver Bullet),大数据的兴起只是说明了一种现象,随着科技的高速发展,数据在人类生活和决策中所占的比重越来越大。面对如此广度和深度的大数据技术栈和工具集,如何学习和掌握好大数据分析这种技能,犹如盲人摸象,冷暖自知。不过技术的学习和应用也是相通的,条条大路通罗马,关键是要找准切入点,理论与实践结合,有全局观,工程化思维,对复杂系统设计开发与关键技术体系的主要矛盾要有所把握。熟悉大数据基础理论与算法、应用切入、以点带面、举一反三、横向扩展,从而构建完整的大数据知识结构和核心技术能力,这样的学习效果就会好很多。
另外,技术发展也遵循量变到质变规律,人工智能+物联网+大数据+云计算是四位一体发展的(时间有先后,但技术实质性突破都在最近几年),未来智能时代的基础设施、核心架构将基于这四个层面,这种社会演化趋势也很明显:农业时代〉工业时代〉互联网时代〉智能化时代。在这个四位一体智能技术链条里面,物联网重在数据采集,云计算重在基础设施,大数据技术处于核心地位,人工智能则是发展目标,所以学习大数据技术还需要对这四个方面加以综合研究和理解。
为了帮助大家让学习变得轻松、高效,给大家免费分享一大批资料,帮助大家在成为大数据工程师,乃至架构师的路上披荆斩棘。在这里给大家推荐一个大数据学习交流圈:658558542 欢迎大家进×××流讨论,学习交流,共同进步。
当真正开始学习的时候难免不知道从哪入手,导致效率低下影响继续学习的信心。
但最重要的是不知道哪些技术需要重点掌握,学习时频繁踩坑,最终浪费大量时间,所以有有效资源还是很有必要的。
最后祝福所有遇到瓶疾且不知道怎么办的大数据程序员们,祝福大家在往后的工作与面试中一切顺利。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



