今年,实时流计算技术开始步入主流,各大厂都在不遗余力地试用新的流计算框架,实时流计算引擎和 API 诸如 Spark Streaming、Kafka Streaming、Beam 和 Flink 持续火爆。阿里巴巴自 2015 年开始改进 Flink,并创建了内部分支 Blink,目前服务于阿里集团内部搜索、推荐、广告和蚂蚁等大量核心实时业务。12 月 20 日,由阿里巴巴承办的 Flink Forward China 峰会在北京国家会议中心召开,来自阿里、华为、腾讯、美团点评、滴滴、字节跳动等公司的技术专家与参会者分享了各公司基于 Flink 的应用和实践经验。在大会的主题演讲上,阿里巴巴集团副总裁周靖人宣布,阿里巴巴内部 Flink 版本 Blink 将于 2019 年 1 月正式开源!阿里希望通过 Blink 开源进一步加深与 Flink 社区的联动,并推动国内更多中小型企业使用 Flink。
会上,我对阿里巴巴计算平台事业部研究员蒋晓伟(花名量仔)进行了独家专访,他与我们分享了关于下一代实时流计算引擎的看法,并针对 Blink 的重要新特性、开源后 Blink 与 Flink 之间的关系、Blink 后续规划等问题进行了解答。
阿里巴巴与 Flink
随着人工智能时代的降临和数据量的爆发,在典型的大数据业务场景下,数据业务最通用的做法是:选用批处理的技术处理全量数据,采用流式计算处理实时增量数据。在许多业务场景之下,用户的业务逻辑在批处理和流处理之中往往是相同的。但是,用户用于批处理和流处理的两套计算引擎是不同的。
因此,用户通常需要写两套代码。毫无疑问,这带来了一些额外的负担和成本。阿里巴巴的商品数据处理就经常需要面对增量和全量两套不同的业务流程问题,所以阿里巴巴就在想:能不能有一套统一的大数据引擎技术,用户只需要根据自己的业务逻辑开发一套代码。这样在各种不同的场景下,不管是全量数据还是增量数据,亦或者实时处理,一套方案即可全部支持,这就是阿里巴巴选择 Flink 的背景和初衷。
彼时的 Flink 不管是规模还是稳定性尚未经历实践,成熟度有待商榷。阿里巴巴实时计算团队决定在阿里内部建立一个 Flink 分支 Blink,并对 Flink 进行大量的修改和完善,让其适应阿里巴巴这种超大规模的业务场景。简单地说,Blink 就是阿里巴巴开发的基于开源 Flink 的阿里巴巴内部版本。
阿里巴巴基于 Flink 搭建的平台于 2016 年正式上线,并从阿里巴巴的搜索和推荐这两大场景开始实现。目前阿里巴巴所有的业务,包括阿里巴巴所有子公司都采用了基于 Flink 搭建的实时计算平台。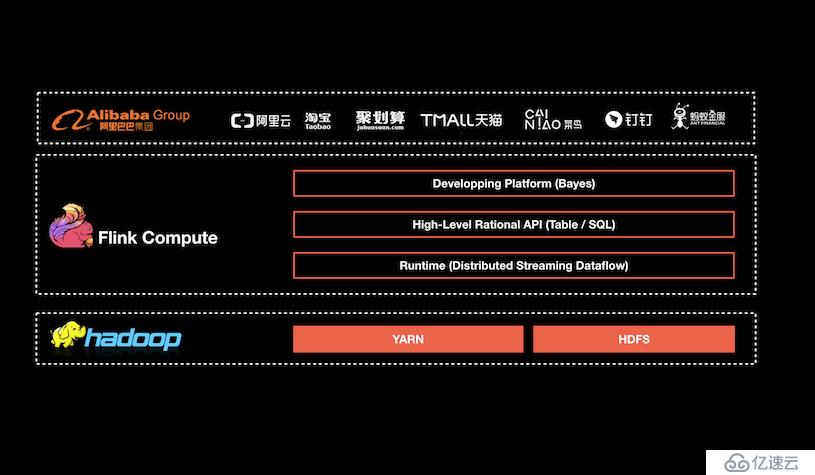
目前,这套基于 Flink 搭建的实时计算平台不仅服务于阿里巴巴集团内部,而且通过阿里云的云产品 API 向整个开发者生态提供基于 Flink 的云产品支持。
以下内容整理自 AI 前线对蒋晓伟的采访。
开源的时机
我:为什么选择现在将 Blink 开源?这其中有哪些考量?什么样的时机才是开源最合适的时机?
蒋晓伟:在我看来,有几个因素:第一个因素是,这几年我们一直试图把阿里对 Flink 的改进推回社区,但社区有自己的步伐,很多时候可能无法把我们的变更及时推回去。对于社区来说,需要达成共识,才能更好地保证开源项目的质量,但同时就会导致推入的速度慢一些。经过这几年积累,我们这边和社区之间的差距已经变得比较大了。Blink 有一些很好的新功能,比如批处理功能,在社区版本是没有的。在过去这段时间里,我们不断听到有人问,Blink 什么时候能开源、是不是能开源这样的呼声。我们有两种方法,一种就是慢慢地推回去再给用户用。但我们认为这样等下去对社区不是最好的。我们还是希望尽快把我们的代码拿出来,尽量让大家都能用起来。所以最近这半年,我们一直都在准备把代码整理好去进行开源。
选择在这个时间点开源有几个好处:第一个好处是我们所开源的这些代码在阿里内部经过像双一十、双十二这样巨大流量的检验,让我们对它的质量有更大的信心,这是非常大的好处;第二个好处,Flink Forward 大会是第一次在中国举办,在这样一个场合开源表明了阿里对 Flink 社区坚定的支持,这是一个比较好的场合。主要是基于这些考虑。
选 Blink 还是 Flink?这不会是一个问题
我:开源的 Blink 版本会和阿里巴巴内部使用的 Blink 保持一致吗?
蒋晓伟:即将开源的是阿里巴巴双十二的上线版本,还会有一些小的改进。
我:Blink 开源后,两个开源项目之间的关系会是怎样的?未来 Flink 和 Blink 也会由不同的团队各自维护吗?
蒋晓伟:开源的意思是,我们愿意把 Blink 的代码贡献出来,但这两个项目是一个项目。有一件事情需要澄清一下,我们将公开 Blink 的所有代码,让大家都可以看到,但与此同时,我们会跟社区一起努力,通过讨论决定 Blink 以什么样的方式进入 Flink 是最合适的。因为 Flink 是一个社区的项目,我们需要经过社区的同意才能以分支的形式进入 Flink,或者作为变更 Merge 到项目中。我想强调一下,我们作为社区的一员需要跟社区讨论才能决定这件事情。
Blink 永远不会成为另外一个项目,如果后续进入 Apache 一定是成为 Flink 的一部分,我们没有任何兴趣另立旗帜,我们永远是 Flink 的一部分,也会坚定地支持 Flink。我们非常愿意把 Blink 的代码贡献给所有人,所以明年 1 月份我们会先将 Blink 的代码公开,但这期间我们也会和社区讨论,以什么样的形式进入 Flink 是最合适的、怎么贡献是社区最希望的方式。
我们希望,在 Blink 开源之后,和社区一起努力,把 Blink 好的地方逐步推回 Flink,成为 Flink 的一部分,希望最终 Flink 和 Blink 变成一个东西,阿里巴巴和整个社区一起来维护。而不是把它分成两个东西,给用户选择的困难,这不是我们想要的。
因此未来用户也不会面临已经部署了 Flink、是否要把 Flink 迁移到 Blink 的问题,企业选型时也不需要在 Flink 和 Blink 之间抉择,Blink 和 Flink 会是同一个项目。Blink 开源只有一个目的,就是希望 Flink 做得更好。
Blink 改进了什么?
我:能不能重点介绍一下即将开源的 Blink 版本有哪些比较重要的新技术特性?与 Flink 最新发布版本相比,阿里的 Blink 做了哪些方面的优化和改进?
蒋晓伟:阿里巴巴实时计算团队不仅对 Flink 在性能和稳定性上做出了很多改进和优化,同时在核心架构和功能上也进行了大量创新和改进。过去两年多,有很多更新已经推回给社区了,包括 Flink 新的分布式架构等。
目前我们的 Blink 版本跟社区版本还有几点差异,第一个是稳定性方面,我们做了一些优化,在某些场景会比社区版本更加稳定,特别是在大规模场景。另外还有一个比较大的不一样是我们全新的 Flink SQL 技术栈,它在功能上,特别是在批处理的功能上比社区版本强大很多。它支持现在标准 SQL 几乎所有的语法和语义。另外,在性能上,无论是在流式 SQL 还是批 SQL,我们的版本在性能上都有很大的优势。特别是在批 SQL 的性能方面,当前 Blink 版本是社区版本性能的 10 倍以上,跟 Spark 相比,在 TPCDS 这样的场景 Blink 的性能也能达到 3 倍以上。如果用户对批处理或者对 SQL 有着比较强的需求,我们这个版本会用户可以得到很多好处。
Blink 在阿里内部的应用
我:请介绍一下 Blink 在阿里内部的使用情况。目前 Blink 在阿里的大数据架构中扮演什么样的角色?在阿里内部主要用于哪些业务和应用场景?
蒋晓伟:现在阿里的大数据平台上,所有的实时计算都已经在使用 Blink;同时,除了实时计算以外,在一些流批一体化的场景也会用 Blink 来做批处理;我们在机器学习场景也有一个探索,叫做 Alink,这个项目是对 Flink Machine Learning Library 的改进,其中实现了大量的算法,都是基于 Flink 做实时机器学习的算法,Alink 在很多场景已经被证明在规模上有很大的优势。同时,我们在图计算场景也有一些探索。
我:目前阿里内部有多少部门在使用 Blink?
蒋晓伟:前段时间我们刚刚做过统计,阿里的技术部门大约有 70% 都在使用 Blink。Blink 一直是在用户的反馈之中成长起来的,对于内部用户反馈的数据倾斜、资源使用率、易用性方面的问题,Blink 都做了针对性的改进。
现在 Blink 用的最多的场景主要还是实时计算方面,阿里还有一些业务现在相对比较新,还没有进入实时计算的领域,等这些业务进入实时计算领域时也会使用 Blink。
在批处理方面,阿里内部也有一个自研的批处理引擎叫做 MaxCompute,MaxCompute 也会拥抱 Flink 生态,在语法和语义上做和 Flink 兼容的工作。未来,整个阿里的计算体系和平台都会融入同一个生态。
后续规划
我:接下来阿里对于 Blink 还有哪些规划?包括技术改进、落地应用、更新维护、社区等几个方面。
蒋晓伟:从技术上说,今天我们公布了 Flink 在批处理上的成果,接下来,我们会对技术持续投入,我们希望每几个月就能看到技术上有一个比较大的亮点。下一波亮点应该是机器学习场景。要把机器学习支持好,有一系列的工作要做,包括引擎的功能、性能和易用性。这些工作我们已经在内部的讨论和进行之中,接下来几个月,大家应该会看到一些成果。我们也在和社区讨论一些事情。除了机器学习之外,我们在图计算方面也有一些探索,包括对增量迭代更好的支持。做完这些之后,可以认为 Flink 作为大数据的计算引擎已经比较完备了。
同时,我们也重点去做 Flink 的生态,包括 Flink 与其他系统之间的关系、易用性等。Flink 要真正做好,不仅需要它本身功能强大,还需要把整个生态做得非常强大。这部分我们甚至会跟一些 ISV 合作,看看是不是能够在 Flink 之上提供更好的解决方案,进一步降低用户的使用门槛。
在社区方面,我们希望能够把把 Blink 完全融入 Flink 社区,一起做 Flink 社区的运营,让 Flink 真正在中国、乃至全世界大规模地使用起来。
在应用方面,实时流计算其实有很多很有潜力的应用场景,但有一些可能大家不是非常熟悉,我们会对这些场景做一些推广。以实时机器学习为例,它往往能够给我们带来比一般的机器学习更大的效果提升。去年,实时强化学习给我们在搜索上带来了 20% 以上的提升。除此之外,在安全领域(比如实时的 Fraud Detection)、监控报警方面,还有 IoT 领域,实时流计算都有非常广泛的应用场景。这些 Flink 现在可能已经做了,但是大家还没有意识到,Flink 能够给大家带来这样的商业上的好处。
我:Blink 开源之后,后续阿里在这基础上做的变更和更新会以什么样的方式推回社区版本?
蒋晓伟:我们理想的方式是,阿里内部的版本是社区的 Flink 版本加上一些定制化的插件,不需要对 Flink 本身做修改,而是对 Flink 做增加。比如跟阿里内部系统交互的部分跟社区是不适用的,就会保持在内部,我们希望这些修改不动 Flink 代码,而是用插件的方式加在 Flink 上面。最终的方式就是,对于所有公司都有用的修改会在 Flink 代码本身做修改,使所有使用 Flink 的公司都能从中获利,而对接阿里内部系统的部分就只在阿里内部使用。
下一代实时流计算引擎之争
我:先在很多人提到实时流计算引擎,都会拿 Spark 和 Flink 来做对比,您怎么看待下一代实时流计算引擎之争?未来实时流计算引擎最重要的发展方向是什么?
蒋晓伟:Spark 和 Flink 一开始 share 了同一个梦想,他们都希望能够用同一个技术把流处理和批处理统一起来,但他们走了完全不一样的两条路,前者是用以批处理的技术为根本,并尝试在批处理之上支持流计算;后者则认为流计算技术是最基本的,在流计算的基础之上支持批处理。正因为这种架构上的不同,今后二者在能做的事情上会有一些细微的区别。比如在低延迟场景,Spark 基于微批处理的方式需要同步会有额外开销,因此无法在延迟上做到极致。在大数据处理的低延迟场景,Flink 已经有非常大的优势。经过我们的探索, Flink 在批处理上也有了比较大的突破,这些突破都会反馈回社区。当然,对于用户来说,多一个选择永远是好的,不同的技术可能带来不同的优势,用户可以根据自己业务场景的需求进行选择。
未来,在大数据方向,机器学习正在逐渐从批处理、离线学习向实时处理、在线学习发展,而图计算领域同样的事情也在发生,比如实时反欺诈通常用图计算来做,而这些欺诈事件都是实时地、持续不断地发生,图计算也在变得实时化。
但是 Flink 除了大数据领域以外,在应用和微服务的场景也有其独特的优势。应用和微服务场景对延迟的要求非常苛刻,会达到百毫秒甚至十毫秒级别,这样的延迟只有 Flink 的架构才能做到。我认为应用和微服务其实是非常大的领域,甚至可能比大数据更大,这是非常激动人心的机会。上面这些都是我们希望能够拓宽的应用领域。
我:在技术方面,Spark 和 Flink 其实是各有千秋,但在生态和背后支持的公司上面,Flink 是偏弱的,那么后续在生态和企业支持这块,阿里会如何帮助 Flink?
蒋晓伟:这次阿里举办 Flink Forward China 就是想推广 Flink 生态的重要举动之一。除了 Flink Forward China 大会,我们还会不定期举办各种线下 Meetup,投入大量精力打造中文社区,包括将 Flink 的英文文档翻译成中文、打造 Flink 中文论坛等。在垂直领域,我们会去寻找一些合作伙伴,将 Flink 包装在一些解决方案中提供给用户使用。
我:关于开源项目的中立性问题。阿里现在在大力地推动 Flink 开源项目的应用和社区的发展,但业界其他公司(尤其是与阿里在其他业务上可能有竞争的公司)在考虑是否采用 Flink 的时候可能还是会对社区的中立性存在一些疑虑,对于这一点,阿里是怎么考虑的?
蒋晓伟:阿里本身会投入非常大的力量推动 Flink 社区的发展和壮大,但我们也非常希望有更多企业、更多人加入社区,和阿里一起推动社区发展,这次阿里承办 Flink Forward China 峰会就是想借此机会让更多公司参与进来。光阿里一家是无法把 Flink 生态做起来的。我希望大家能够看到我们在做的事情,然后消除这样的疑虑。我们会用自己的行动表明,我们是真的希望把 Flink 的社区做大,在这件事情上,我们并不会有私心。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



