今天给大家介绍一下.NET+PostgreSQL实践与避坑技巧是怎么样。文章的内容小编觉得不错,现在给大家分享一下,觉得有需要的朋友可以了解一下,希望对大家有所帮助,下面跟着小编的思路一起来阅读吧。
.NET+PostgreSQL(简称PG)这个组合我已经用了蛮长的一段时间,感觉还是挺不错的。不过大多数人说起.NET平台,还是会想起跟它“原汁原味”配套的Microsoft SQL Server(简称MSSQL),其实没有MSSQL也没有任何问题,甚至没有Windows Server都没问题,谁说用.NET就一定要上微软全家桶?这都什么年代了……
PG和MSSQL的具体比较我就不详细展开了,自行搜一下,这种比较分析文章很多。应该说两个RDBMS各有特色,MSSQL工具集庞大(大多我们都用不到或不会用),安装较为麻烦,PG比较小巧,但功能也不弱,我们要的它都有,性能方面我做过简单的增删查改的测试,两者看不出什么明显差别,MSSQL貌似最近才提供了Linux版,而PG天生跨平台,MSSQL的授权费似乎不低(没深究),PG开源免费,对比较抠的客户来说,是不太愿意另外花钱买一套MSSQL的,PG就是非常不错的选择。
PG应该选择什么版本?Linux还是Windows?当然是首选Linux,但开发环境无所谓,你在你自己的工作电脑上安装一个Windows版也是没问题的,有人说两者性能差距较大,Linux明显要好于Windows,但我有做过测试,这个并没有被证实如此,然而,我还是推荐Linux,一来安装简便,二来配置简单(命令行界面用起来感觉比较一致),三来方便写一些脚本来实现数据库定时备份之类的。其实你并不需要担心安装了PG后电脑会变慢,我完全感觉不出来,它是个安静的乖萌宠,你不叫它,它就静静坐在那里,我的Windows电脑上也安装了一个PG,我经常用它来做一些脚本测试或试验。另外,现在也能在Windows下直接安装Linux版本的PG了,WSL了解下?
PG有很多的版本,现在的最新版是10.4,它前面的版本是9.6.x,嗯?有点奇怪不是?10.4只有“两段”,而9.6.x有三段,其实之前一直是三段,9表示大版本,6表示中版本,后面是小版本,小版本只有小的功能改进,不会对数据格式造成任何影响,就是说,你的PG从9.6.1升级到9.6.9,你直接升了把旧程序替换掉就是,保证没有任何问题。但如果你之前的版本是9.5.3,要升级到9.6.9,那就不行了,因为中间版本变了,你需要用一个迁移工具去把你的旧的数据格式转为新的方可,那对10.4这个版本而言,哪个是大版本,哪个是中版本,哪个是小版本?这里我感觉有点不连贯,PG在从9升级到10的时候,似乎丢掉了“大版本”,10虽然是9的后继,但它应该算一个中版本,所以,10.1升级到10.4是不用转换数据的,直接升级程序即可。那PG的下一个中版本是什么?没错,是11,再下一个应该就是12了。软件这个东西,如果你没什么历史包袱,我觉得直接选择最新的,比如选择10.4,将来升级10.5,10.6的时候也简单。
说点额外的,PG10是去年(2017)正式推出的,距离现在都不到一年,刚出来的时候我就想,这个“重大升级”(想想看iPhone X,Mac OS X,10这个数字是很特别不是?)能不能带来性能上的大提升呢?我试了一下,结论是:没有。确实它的升级文档上也没提及到性能有什么明显提升,它主要增加了对表分区的原生支持,表分区,就是你的表中的数据的数量很多很多的时候,通过表分区来提高读写速度,至于表要多大才推荐分区呢?PG的官方文档说是:如果表的尺寸赶上了你主机的内存的时候,可以考虑表分区……所以,对于那些只有区区几千万行或几百万行数据的表,你确定要分区吗?
要用.NET使用PG,就得用nuget引入Npgsql这个包,这是它的官方网站:http://www.npgsql.org/,完全开源,它其实就是针对PG数据库的ADO.NET引擎(ADO.NET Data Provider)。这里是它的帮助手册:http://www.npgsql.org/doc/index.html
这里边并没有太多难点,你所需要做的,就是安装好你的PG数据库(Windows版/Linux版都行,没有什么影响),然后创建一个.NET项目(我推荐使用.NET Core),引入Npgsql,然后照着说明手册上的简单例子入一下门即可。
本文当然不会具体带你如何开始使用SELECT语句,下面主要讲述在使用过程中,我们所克服的一些困难或踩过的坑。
MSSQL中用得最多的的文本类型是NVARCHAR,这是一个带长度限制的文本类型,对应地,PG中有VARCHAR,这样用没问题,但PG中的文本类型其实跟MSSQL中的文本类型是有点区别的,PG的文本基本上可以认为不限长度,VARCHAR及TEXT对PG内部来说,并没有什么差别,只是在写入的时候,VARCHAR会检查一下长度,所以性能上来看,VARCHAR并不比TEXT要快,较真的话可能还会慢点,因为它要检查长度嘛,所以你在设计数据库的时候可以无脑地将所有文本类型设置为TEXT(或后面提到的CITEXT),长度检查工作放在业务系统中去做即可。
绝大多数时候,我们都是希望大小写不敏感的,大小写敏感反倒会带来很多困惑,查询不出,或者系统中存在同名的用户,一个叫John另一个叫john,MSSQL可以在创建库的时候指定大小写不敏感,而PG似乎没有这样的功能,它需要借助一个额外的组件,叫CITEXT,CI的意思就是Case Insensitive。要使用CITEXT组件,你需要安装postgresql10-contrib包(假设你安装的是PG10,如果不是的话你去找对应的包),再使用以下命令创建CITEXT类型:
CREATE EXTENSION IF NOT EXISTS CITEXT WITH SCHEMA public;
注:一个database只需要执行一次这个命令即可
如果你使用的是psql客户端连上去使用PG的话,这时候已经OK了,你会发现CITEXT的字段已经是大小写不敏感了,但如果你用的是Npgsql用代码去访问PG的话,CITEXT似乎没生效,其实原因是这样的,CITEXT并不是PG的原生类型,你在用查询语句的时候,需要在参数后面加上“::CITEXT”显式地告诉PG,你的参数是CITEXT类型,例子如下:
SELECT * FROM test_table WHERE test_name=@TextName::CITEXT AND category=@Category::CITEXT
嗯,我承认是有点麻烦,但习惯就好,我现在还不知道有什么更佳方法。
这个异常的呈现内容大致如此:
System.NotSupportedException: The field 'application_id' has a type currently unknown to Npgsql (OID 41000). You can retrieve it as a string by marking it as unknown, please see the FAQ. 在 Npgsql.NpgsqlDataReader.GetValue(Int32 ordinal) 在 Npgsql.NpgsqlDataReader.get_Item(Int32 ordinal) ……
这个错误对我们而言,曾经像个幽灵似的,时不时出现,出现的时候重启一下服务程序就好了,不再出现,然后过几个星期或者几个月又出现,有时候一天出现多次也不是没有可能。最后是到github上面求助才最终搞懂了原因。链接:https://github.com/npgsql/npgsql/issues/1635
简单地说,PG对各种数据类型,是有一个内部的ID值的(叫oid),Npgsql在第一次连接数据库的时候,会获取到这些oid值并缓存起来,对于PG的内部类型,如INT什么的,这些oid值是固定的,但对于CITEXT似乎不是这样,因为CITEXT这个类型是我门自己用CREATE EXTENSION命令创建的(请参考本文前面内容),创建的时候确定其oid。我们在还原数据库的时候,也相当于重新创建了CITEXT类型,这样会导致CITEXT的oid发生变化,但Npgsql并不知道,所以就出现了这个异常。我们在开发过程中常常需要做还原数据库的动作,所以导致了这个问题的发生。
解决方法1,当数据库还原了之后,调用NpgsqlConnection.ReloadTypes(),刷新各类型oid,但这个很难,因为还原数据库都是手动操作,做完之后打开网页,在上面点一下通知程序吗?
解决方法2,重启一下程序。这个其实跟解决方法1差不多,只不过不需要写什么额外代码,考虑到还原数据库这个动作其实也不是太频繁,只是在开发环境中做,所以重启就重启吧,我们现在就干,规定还原数据库后自己重启下服务程序。(写个脚本干这个事情很简单)
这个问题我同样到github上求助了,链接:https://github.com/npgsql/npgsql/issues/1838
这个问题比前面的问题可能更严重,因为我很可能捕捉不到异常(就是说有时候可以捕捉到,有时候不行),程序直接崩溃了,对于一个.NET程序来说,这是很不应该的事情,即便我没单独写try-catch,程序的最外层异常处理器应该也能捕捉到相关的Exception并log对不?但偏不,没有log,也捕捉不到。所以至今我怀疑这是一个.NET的bug,可能跟Npgsql并没有关系。
问题的原因如github上所描述,是找到了,但却无法从根本上修正,这个问题其实是个简单的“事务超时”问题。
我们的程序在第一次启动的时候会初始化数据库的表,插入大量的初始化数据,由于我们公司的开发环境比较特殊,数据库延迟十分高,所以导致插入速度很慢,每条插入耗时可高达几十毫秒,(生产环境并没有这个问题)这样一万多条数据下来就导致了事务超时(事务超时默认时间是1分钟)。解决方法当然很明显了:初始化的时候,临时增加 TransactionScope的超时值,增加到10分钟,这样总归没问题了。
类似这种问题我们只能通过一些外部的workaround来预防,很难从根本上解决。
这又是一个有点棘手的事情,首先是这个中文翻译得很不好,这是一条数据库抛出来的出错信息,它的英文是“Prepared transactions are disabled”,其正确的中文翻译我觉得应该是:预处理事务已被禁用。唉,所以我说为什么要英文版,如果提示中文,想在网上找答案都会多些障碍。
对事务的使用,这里有个简单的例子:
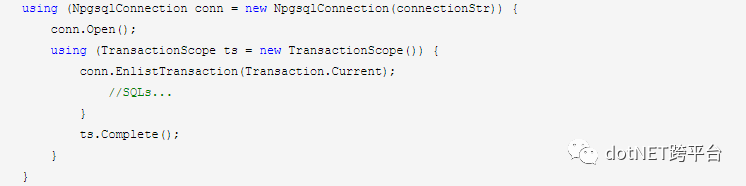
什么叫“预处理事务”?其实很简单,就是“事务包事务”,就是可以分步提交的事务,比如我先开启了一个事务A,在这个事务中我又开启了一个事务B,B提交,A再提交。PG对于预处理事务是默认关闭的,当然了,你可以打开它,编辑配置文件postgresql.conf,把max_prepared_transactions改为100(默认是0,0表示禁用),重启PG服务即可。
但你确定你真的用得到预处理事务吗?我看下来我们是用不到的,但为什么出现这个问题?——还是我们程序写得有问题,即便你从单个方法上看不出来事务包事务。以下两种场景可能会出现“预处理事务”:
1,我创建了一个方法A访问数据库,这个方法可能会被其它方法调用,所以它有个DbConnection类型的参数,表示调用者负责打开数据库连接传递过来,而A里面开启了事务,而调用者并不知情,也开启了事务,形成预处理事务
2,这种情况更隐晦些,数据库连接字符串,如:Host=192.168.1.101; Username=postgres; Password=123456; Database=testdb; Enlist=true,在后面有个叫Enlist的参数为true,这表示这个连接在打开的时候,会自动Enlist到当前执行上下文的Transaction中去,如果当前执行上下文中打开了事务(从代码上看包含在了using(TransactionScope)中),那这个数据库连接就自动Enlist上去了,再考虑这样的场景:A方法会自己打开数据库连接去查询点什么东西,B方法也会访问数据库,且B方法会使用事务,事务中调用了A方法,A方法打开数据库连接的时候发现当前执行上下文中存在Transaction,于是自动Enlist上去了,不经意间形成了预处理事务,且还是“分布式”的(A和B打开的可能是不同的数据库连接),这种情况应该并不是你所需要的
那我们应该怎么做?下面是我的做法:
1,max_prepared_transactions还是设置为0,关掉,因为我们真用不到,如果用得到,那就是我们代码写错了,所以一旦出现“禁用已准备好的事务”这个异常,就回去检查代码
2,把Enlist=true在数据库连接字符串中去掉,这么一来,每次使用事务都需要显式地调用 conn.EnlistTransaction(Transaction.Current),虽然对了一行代码,但语义更明确,也不用考虑到底是TransactionScope包DbConnection或反过来DbConnection包TransactionScope
3,规范化我们的数据库访问代码,明确哪些是需要事务哪些是不需要的,在各个方法的注释上注明
它对应的英文是:Cound not serialize access due to read/write dependencies among transactions,这个应该怎么理解呢?其实了解数据库事务隔离级别的人对这个应该不会陌生。.NET的TransactionScope默认使用的是事务隔离级别中的最高级别——Serializable(可序列化)。这个级别最大程度上确保了数据的一致性,但代价也挺高,一来速度较慢,二来很容易出现“事务间读/写依赖”,就是这个错误了,举个简单的例子:
A、B两个事务,同时访问test表中id为50的一条记录,A读出这条记录,接着B更新了这条记录并提交,根据可序列化的隔离级别的规则,A并不知道B更新了记录,A在B提交后尝试修改这条记录,这时候数据库就会让A事务失败,并抛出这个异常,因为让A修改成功的话,就会导致B之前的修改不经意间丢失了,可序列化隔离级别并不允许这种情况的发生。
所以,这是个“正常的错误”,按常规的业务逻辑来说,应该很少会出现,如果真的出现,且频繁出现,那需要考虑下是不是业务逻辑设计得不太合理,看看能不能从设计上避免这个问题,如果业务逻辑一定如此,那可以用下面的方法尝试一下:
1,将这种并行事务用客户端代码排个队,弄个线程安全队列,逐个执行,这样速度会慢点,但确保了每个事务都能成功
2,捕捉这个异常,然后自动重试,其实这也是数据库推荐的正统的做法
3,降低事务隔离级别,这个可能会出现问题,也可能不出现,这完全取决于你的业务,关于事务隔离级别,这是个蛮大的话题,我考虑适当时候再写一篇文章
4,对于极少出现的频次来说,可以不处理,仅仅需要捕捉这个异常类型,然后提示用户重试即可,很多网站貌似都这么干的
以上就是.NET+PostgreSQL实践与避坑技巧是怎么样的全部内容了,更多与.NET+PostgreSQL实践与避坑技巧是怎么样相关的内容可以搜索亿速云之前的文章或者浏览下面的文章进行学习哈!相信小编会给大家增添更多知识,希望大家能够支持一下亿速云!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





