这期内容当中小编将会给大家带来有关如何避免Duplicate key在数据表插入中的应用,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
在一个数据表中插入数据,防止有重复的数据插入,一般DBA大多的做法是
唯一索引,主键,在重复的数据插入的过程中,就通过数据库的唯一约束或检查,将这些重复的数据拒之门外。
而很多场合下,这样的作法并不合适,因为你遇到的程序员他可能不大会处理在数据拒绝插入的后续处理,这是比较尴尬的问题。如何能让他用很简单的SQL语句,来将这个问题解决,这需要 DBA 做点什么。
在SQL SERVER 中一般的情况是这样使用的,(看下面的语句),通过在插入的过程中,进行判断,判断插入tbl_A 来自于 tbl_B的数据不应该和 tbl_A重复,也就是在插入的前边要来一次机遇标识键的过滤
INSERT tbl_A (col, col2) SELECT col, col2 FROM tbl_B WHERE NOT EXISTS (SELECT col FROM tbl_A A2 WHERE A2.col = tbl_B.col);
这样看着比较LOW 其实效率也一般。 所以微软推荐的方法是下面的
Merge 功能,这个功能的在我工作的十几年的经历中,是比较少的,因为大多数的场景在现在的应用开发中,CRUD 的操作已经能覆盖大部分数据库操作的功能,大部分的计算和判断的功能大多是在应用层来做的,通过程序来实践,数据库越来越多变得像一个容器被使用,数据库只要做好MVCC,ISOLATE的事情就OK 了, 所以MERGE 的功能比较少的被引用到数据库的使用中。
而何时要使用MERGE 功能,最近的一个项目的修改中,就遇到了,在原先的数据插入,使用了游标,这样的结果可想而知,一定是糟糕的,数据库使用游标本来就是下下的选择,如果一个程序员使用了游标,除非数据量很小,并且逻辑非常复杂,而且必须要用数据库 PROCEDURE 来做,否则游标应该被踢出数据库的语句层。
在修改后的存储过程中,已经没有了游标,这是一个可喜的事情,但不好的事情又发生了,程序的逻辑中,需要判断插入的数据是否已经在数据库中存在,如果存在,就不要插入,否则就插入。
当然要解决这个问题,其实方法很多,相应的每种方法的限制也不少。
1 唯一索引,联合唯一索引 (被回绝,顾问提供的存储过程是不会使用这样的方法来处理那些中断,错误,使用这样的方法还是要程序报错,目的没有达到) PASS
2 insert into ....... select ...... where not exist (select .... ) 这个就不说了,上面已经有这样的语句了
3 本次的重点,merge into 语句, 我们还拿上面的的语句改写成merge into 来实现。INSERT tbl_A (col, col2) SELECT col, col2 FROM tbl_B WHERE NOT EXISTS (SELECT col FROM tbl_A A2 WHERE A2.col = tbl_B.col);
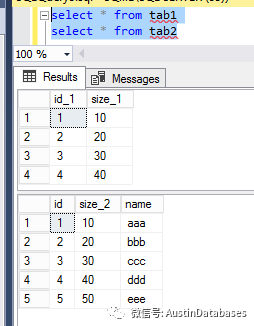
改写后,
merge into tab1 as tab1
using (select id,size_2 from tab2) as tab2 on tab1.id_1 = tab2.id
WHEN NOT MATCHED THEN
insert (size_1) values (size_2);
结果:在没有报错的情况下,将两个表重合的记录去除后,在将不同的结果插入。
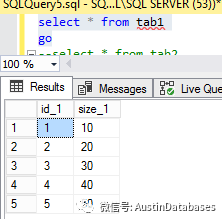
问题解决
在MYSQL 中,处理这样的事情比SQL SERVER的方法要多,主要有两种
1 REPLACE INTO
2 DUPLICATE KEY UPDATE
以上两种方法,在这样的情况下,使用 DUPLICATE KEY UPDATE 是比较合适的,具体Replace into
这里就不在介绍,这两个区别也是显而易见的,一个 匹配 DELETE ,在INSERT ,另一个是 匹配UPDATE
这是明显的两个方式的不同。
这里还是MYSQL的两个类似SQL SERVER 表
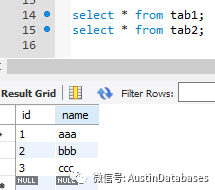
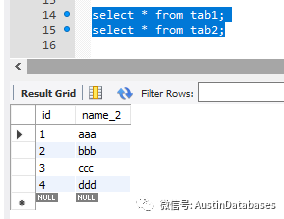
还是要将 tab2 的与 tab1 不同的数据插入到 tab1
insert into tab1 (id,name) select id,name_2 from tab2 on duplicate key update tab1.name= tab2.name_2;
以上的一条语句就可以完成这个工作,根据主键或者唯一索引,来判断重复的数据,并紧紧进行更新,否则就插入tab1中在tab2中不存在的数据。
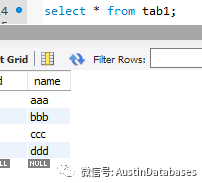
对比 SQL SERVER , MySQL在这项工作中显然是要方便的多。
——————————————————————————————

ORACLE 在处理这样数据的方式和SQL SERVER 类似,
merge into tab1 using tab2 on (tab1.id=tab2.id) when not matched then insert (id,name) values (tab2.id,tab2.name_2);
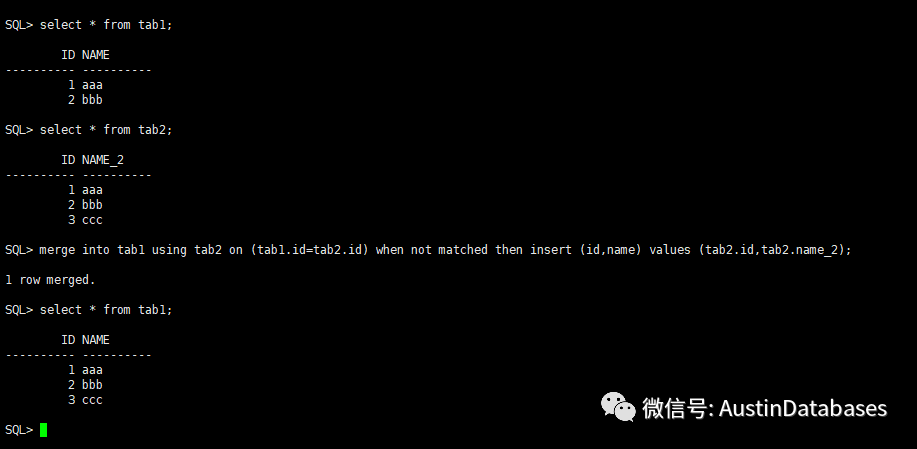
_____________________________________________________________

Postgresql 简述: Postgresql 的确是数据库界的黑马,无论是MYSQL的
duplicate key update ,还是 ORACLE SQL SERVER 支持的 MERGE INTO 语法均在数据库中支持(11版本)
——————————————————————————————————总结:
相比MYSQL ,SQL SERVER 和ORACLE 在处理重复值上比较麻烦,虽然SQL SERVER 和ORACLE 在处理的路数上近似一致,但也有不同点,PostgreSQL 的确是后来者居上,三种数据库支持的方式均在最新版的数据库中支持

1 ORACLE 胜出,在MATCH 下的语句还是可以添加 where 条件,这样操作会更灵活,SQL SERVER 不可以

2 SQL SERVER 胜出, SQL SERVER 可以在判断中,将目标表未操作的数据删除,但ORACLE 不可以

3 MYSQL 在使用中针对去重记录,是最简便最快速的,但功能简单,如果要进行ORACLE 或者 SQL SERVER 复杂的功能,则没有现成的语句完成。

4 PostgreSQL,胜出,三种数据库支持的方法均都支持,缺点,需要更新的 11版本的PostgreSQL.
上述就是小编为大家分享的如何避免Duplicate key在数据表插入中的应用了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4582201/blog/4582924



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



