MYSQL8 P_S 及新版在MGR 中的变化有哪些,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
随着MYSQL 8 越来越成熟,未来MYSQL 将会开始替换 MYSQL 5.7X成为新的MYSQL 数据库在市面上的主力。
而MYSQL 8 在 P_S (performance_schema)中的一些变化,以及如何更好的monitor MGR 这是一个值得去学习的地方。
在MYSQL 8 后P_S 引入了 XCOM, GCS两个信息,这主要是要增加MGR的可观测性和管理性。
1 在thread中引入了部分Xcom GCS 信息,

这四个线程主要启动的作用
Gcs_ext_logger_impl::m_consumer 处理有关任何触发点后的日志信息记录线程
Gcs_xcom_engine::m_engine_thread 处理GCS 中的事件线程
Gcs_xcom_control::m_xcom_thread 负责xcom的运行线程
Gcs_xcom_control::m_suspicions_processing_thread 处理意外情况驱逐节点的线程
2 在等待事件表中也可以查看关于这两方面的等待信息
首先我们需要打开相关的等待时间的记录开关
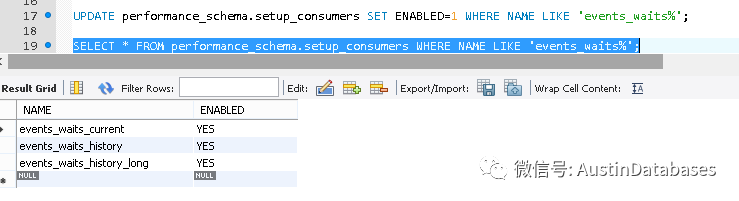
在打开后,我们可以通过查看相关的等待记录,或历史等待记录,来了解MGR 在使用过程中有哪些问题细节。具体哪些等待事件对应哪些问题,可以通过查看官方文档来解决。
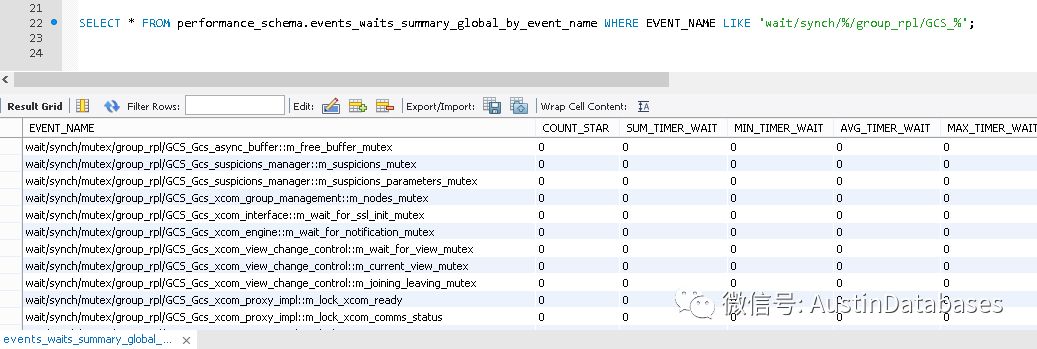
并且在 Replication_group_member_stats
中在MYSQL 8 添加了一些字段
1 COUNT_TRANSACTIONS_REMOTE_IN_APPLIER_QUEUE
从接收组中的事务在等待队列
2 COUNT_TRANSACTIONS_REMOTE_APPLIED
成员已经从应用组中应用的事务
3 COUNT_TRANSACTION_LOCAL_PROPOSED
群组中协同的事务数量
4 COUNT_TRANSACTION_LOCAL_ROLLEDBACK
群组中进行rollback的事务数量、
并且最近从爱可生发布的文章,中提到了Large Messages Fragmentation Layer for Group Replication,这是对于MGR中被人提到的大事务造成的MGR 主机离线的问题的一个解决方法,通过对事务打散后在重新组装的方式来进行大事务的集群化的处理。
除此之外MYSQL 8.016 还在,同时 XCom’s message cache 不在是绑定一个静态的数字,而是开始进行动态的设定根据消息的大小开始变化。
而最新的8.016版本支持 Auto-rejoin for Group Replication,未来新版本中被踢出的MYSQL 很可能可以自动重新加入,不在依赖手工进行加载。
发展的速度太快,一步跟不上,步步跟不上。
看完上述内容,你们掌握MYSQL8 P_S 及新版在MGR 中的变化有哪些的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





