电商大数据项目-推荐系统实战(一)环境搭建以及日志,人口,商品分析
https://blog.51cto.com/6989066/2325073
电商大数据项目-推荐系统实战之推荐算法
https://blog.51cto.com/6989066/2326209
电商大数据项目-推荐系统实战之实时分析以及离线分析
https://blog.51cto.com/6989066/2326214
开源项目,请勿用于任何商业用途。
源代码地址:https://github.com/asdud/Bigdata_project
本项目是基于Spark MLLib的大数据电商推荐系统项目,使用了scala语言和java语言。基于python语言的推荐系统项目会另外写一篇博客。在阅读本博客以前,需要有以下基础:
1.linux的基本命令
2.至少有高中及以上的数学基础。
3.至少有java se基础,会scala语言和Java EE更佳(Jave EE非必需,但是可以帮助你更快理解项目的架构)。
4.有github账户,并且至少知道git clone,fork,branch的概念。
5.有网络基础,至少知道服务器端和客户端的区别。
6.有大数据基础,最好会Hadoop,HDFS,MapReduce,Sqoop,HBase,Hive,Spark,Storm。
7.有mysql数据库基础,至少会最基本的增删改查。
你要是大神,估计看这篇博客也没有任何用处,至少给点意见和建议呗!
PC配置要求
1.CPU:主流CPU即可
2.内存RAM:至少8G,推荐16G及以上,32G不浪费。
3.硬盘:由于VM对I/O流读取速度要求高,推荐使用256G及以上固态硬盘(SATA3即可.NVME更好),系统盘需要60-100G,其余的专门划一个盘用于安装虚拟机。或者采用傲腾内存+机械硬盘的方案。
关于傲腾内存的介绍和装机方法
https://product.pconline.com.cn/itbk/diy/memory/1806/11365945.html
4.GPU显卡;无要求。但是如果你想学习深度学习框架的话,可考虑1060 6g甚至是2080TI。
5.网速:CentOS 8GB多,HDP接近7个G,CDH几个包加起来2.5G。自己算算需要下载多长时间,或者考虑用U盘从别人那里拷贝?
你也可以考虑用阿里云,腾讯云等云主机。
步骤一:
搭建CentOS+HDP的环境,或者CentOS+CDH的环境,这些都是开源的,不用担心版权问题,企业上一般也是用这两种方案。
在这里我采用的是CentOS+HDP的方案
大数据之搭建HDP环境,以三个节点为例(上——部署主节点以及服务)
https://blog.51cto.com/6989066/2173573
大数据之搭建HDP环境,以三个节点为例(下——扩展节点,删除节点,以及部署其他服务)
https://blog.51cto.com/6989066/2175476
也可以采用CentOS+CDH的方案
搭建CDH实验环境,以三个节点为例的安装配置
https://blog.51cto.com/6989066/2296064
开发工具:Eclipse oxygen版本或者IDEA
代码实现部分
1.数据:用户查询日志来源
搜狗实验室
.https://www.sogou.com/labs/resource/q.php
我选的迷你版
介绍:
搜索引擎查询日志库设计为包括约1个月(2008年6月)Sogou搜索引擎部分网页查询需求及用户点击情况的网页查询日志数据集合。为进行中文搜索引擎用户行为分析的研究者提供基准研究语料
格式说明:
数据格式为
访问时间\t用户ID\t[查询词]\t该URL在返回结果中的排名\t用户点击的顺序号\t用户点击的URL
其中,用户ID是根据用户使用浏览器访问搜索引擎时的Cookie信息自动赋值,即同一次使用浏览器输入的不同查询对应同一个用户ID
2.首先新建一个Maven工程MyMapReduceProject,然后更新pom.xml文件
pom文件地址
https://github.com/asdud/Bigdata_project/blob/master/MyMapReduceProject/pom.xml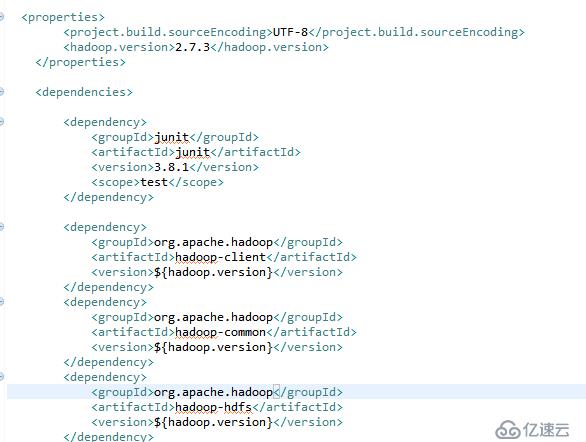
这个时候就会自动下载对应的依赖的jar包
(一)案例1:搜狗日志查询分析
查询搜索结果排名第1点,击次序排在第2的数据
使用MapReduce进行分析处理
https://github.com/asdud/Bigdata_project/blob/master/MyMapReduceProject/src/main/java/day0629/sogou/SogouLogMain.java
https://github.com/asdud/Bigdata_project/blob/master/MyMapReduceProject/src/main/java/day0629/sogou/SogouLogMapper.java
使用Spark进行分析和处理
首先使用Ambari,添加Spark2的服务;由于依赖其他的服务,比如Hive等等,需要在启动Ambari Server的时候,指定MySQL的JDBC驱动。
登录spark-shell,需要用下面的方式:
spark-shell --master yarn-client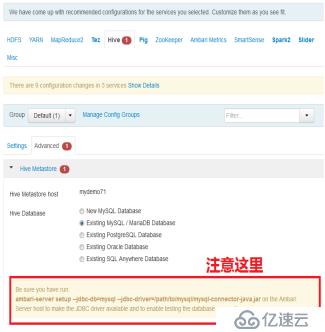
ambari-server setup --jdbc-db=mysql --jdbc-driver=/usr/share/java/mysql-connector-java.jar
jdbc-driver地址与你安装mysql-connector-java.jar目录对应。
(二)案例2:人口分析案例
本案例假设我们需要对某个省的人口 (1 亿) 性别还有身高进行统计,需要计算出男女人数,男性中的最高和最低身高,以及女性中的最高和最低身高。本案例中用到的源文件有以下格式, 三列分别是 ID,性别,身高 (cm)。
使用Scala程序生成测试数据(大概1.3G)
https://github.com/asdud/Bigdata_project/blob/master/MySparkProject/src/main/java/day0629/PeopleInfo/PeopleInfoFileGenerator.scala
注意:可以将数据量减小一下,这样处理的时候会短一些。示例中是1亿条记录,可以改为1万条记录。
并将生成的数据放到HDFS上:
hdfs dfs -put sample_people_info.txt /myproject/data
案例分析(使用MapReduce)
https://github.com/asdud/Bigdata_project/tree/master/MyMapReduceProject/src/main/java/day0629/peopleinfo
(三)案例3:电商订单销售数据分析
(四)Spark的累加器和广播变量
由于spark是分布式的计算,所以使得每个task间不存在共享的变量,而为了实现共享变量spark实现了两种类型 - 累加器与广播变量。
1.累加器(accumulator)是Spark中提供的一种分布式的变量机制,其原理类似于mapreduce,即分布式的改变,然后聚合这些改变。累加器的一个常见用途是在调试时对作业执行过程中的事件进行计数。
示例:
val accum = sc.accumulator(10, "My Accumulator")
sc.parallelize(Array(1,2,3,4)).foreach(x => accum+=x)
println(accum.value)
最终结果:20
2.广播变量允许程序员将一个只读的变量缓存在每台机器上,而不用在任务之间传递变量。广播变量可被用于有效地给每个节点一个大输入数据集的副本。Spark还尝试使用高效地广播算法来分发变量,进而减少通信的开销。
示例:将用户信息存入广播变量。
case class UserInfo(userID:Int,userName:String,userAge:Int)
val broadcastVar = sc.broadcast(UserInfo(100,"Tom",23))
broadcastVar.value
四、各区域热门商品
(一)模块介绍
电商网站运营中,需要对每个区域用户关心的商品进行统计分析,支持用户决策。
用途:
分析各区域对产品的不同需求,进行差异化研究,例如北京用户喜欢手机,上海用户喜欢汽车。
指导商品折扣,推广策略
(二)需求分析
(1)如何定义用户关心的商品?
通过用户对商品的点击量来衡量商品热度
复杂模型:通过用户点击+购买以及搜藏等综合数据对商品进行评价
商品热门程度得分模型 = 点击次数2+购买次数5+搜藏次数*3
其中2,5,3为得分权重
(2)如何获取区域
通过用户点击日志,订单可以获取地域
① 日志数据,来源与日志系统,flume ,t+1也可以每30分钟
② 订单来源于数据库,sqoop,t+1也可以每30分钟
数据库一定是读写分离
sqoop从读的数据库导数据,所以会造成数据与真实业务库有一定的延时
(3)深度思考:如何去除爬虫水军
(三)技术方案
数据采集逻辑(ETL)
电商日志一般存储在日志服务器,需要通过Flume拉取到HDFS上
数据的清洗逻辑
使用MapReduce进行数据清洗
使用Spark进行清洗
各区域热门商品的分析计算
使用Hive进行数据的分析和处理
使用Spark SQL进行数据的分析和处理
思考:能否采用MapReduce进行数据的分析和处理
(四)实验数据及说明
表Product(产品信息表)
列名 描述 数据类型 空/非空 约束条件
product_id 商品号 varchar(18) Not null
product_name 商品名称 varchar(20) Not null
marque 商品型号 varchar(10) Not null
barcode 仓库条码 varchar Not null
price 商品价格 double Not null
brand_id 商品品牌 varchar(8) Not null
market_price 市场价格 double Not null
stock 库存 int Not null
status 状态 int Not null
补充说明 Status:下架-1,上架0,预售(1)
表Area_info(地区信息表)
列名 描述 数据类型 空/非空 约束条件
area_id 地区编号 varchar(18) Not null
area_name 地区名称 varchar(20) Not null
补充说明
表order_info(订单信息表)
列名 描述 数据类型 空/非空 约束条件
order_id 订单ID varchar(18) Not null
order_date 订单日期 varchar(20) Not null
user_id 用户ID varchar(20)
product_id 商品ID varchar(20)
补充说明
表user_click_log(用户点击信息表)
列名 描述 数据类型 空/非空 约束条件
user_id 用户ID varchar(18) Not null
user_ip 用户IP varchar(20) Not null
url 用户点击URL varchar(200)
click_time 用户点击时间 varchar(40)
action_type 动作名称 varchar(40)
area_id 地区ID varchar(40)
补充说明 action_type:1收藏,2加入购物车,3点击
表area_hot_product(区域热门商品表):最终结果表
列名 描述 数据类型 空/非空 约束条件
area_id 地区ID varchar(18) Not null
area_name 地区名称 varchar(20) Not null
product_id 商品ID varchar(200)
product_name 商品名称 varchar(40)
pv 访问量 BIGINT
补充说明
(五)技术实现
① 使用Flume采集用户点击日志
通常使用shell脚本执行日志采集
复杂情况,使用可视化的ETL工具,来进行Flume Agent控制
下面是配置文件,注意HDFS的端口号。
② 数据的清洗
需要将用户点击日志里面对于商品的点击识别出来
过滤不满足6个字段的数据
过滤URL为空的数据,即:过滤出包含http开头的日志记录
实现方式一:使用MapReduce程序进行数据的清洗
实现方式二:使用Spark程序进行数据的清洗
注意:如果不希望在Spark执行中,打印过多的日志,可以使用下面的语句:
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
③ 各区域热门商品热度统计:基于Hive和Spark SQL
方式一:使用Hive进行统计
方式二:使用Spark SQL进行统计
在Spark SQL中执行的SQL:
select a.area_id,a.area_name,p.product_id,product_name,count(c.product_id) from area a,product p,clicklog c where a.area_id=c.area_id and p.product_id=c.product_id group by a.area_id,a.area_name,p.product_id,p.product_name;
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



