ChIP-Atlas中基于公共数据如何进行分析挖掘,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
ChIP-Atlas收集整理了SRA数据库中的大量chip_seq数据,并基于这些原始数据进行了后续分析,将分析结果整理成在线服务并发布,方便检索与查询/
构建的流程如下
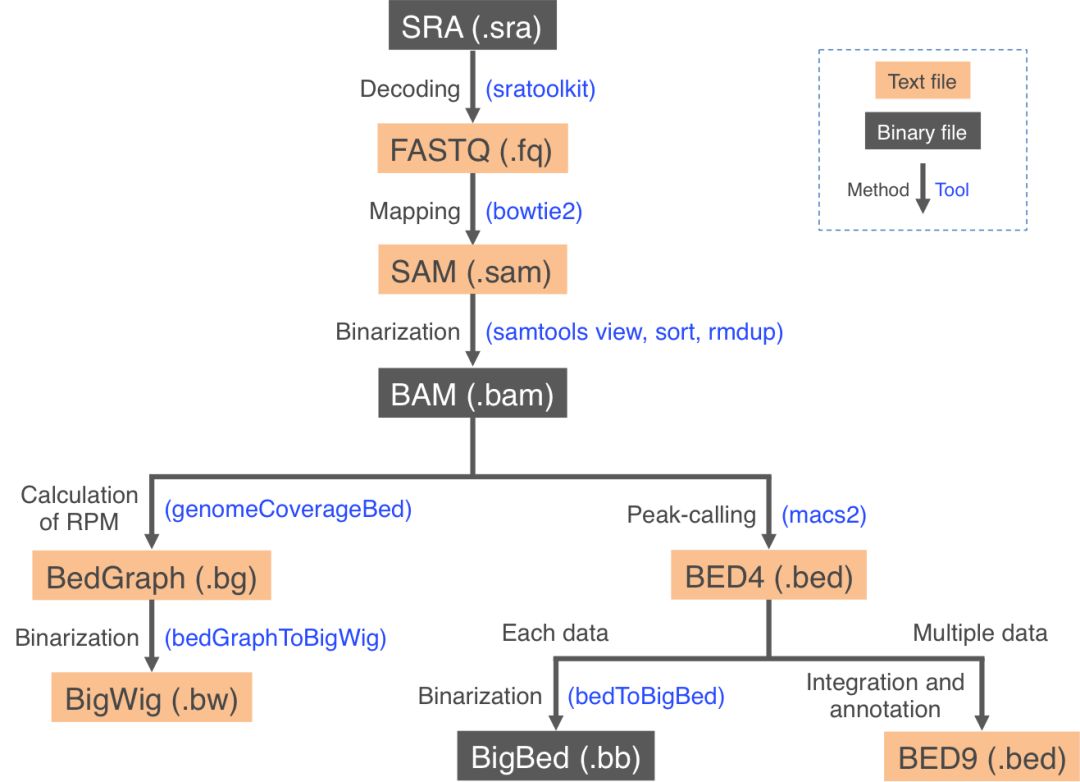
下载SRA原始数据,采用sratoolkit转换成fastq, 然后用bowtie2比对参考基因组,用macs2进行peak calling。官网提供了以下几个功能
浏览不同物种,不同细胞类型,不同抗体的peak结果,检索框示意如下
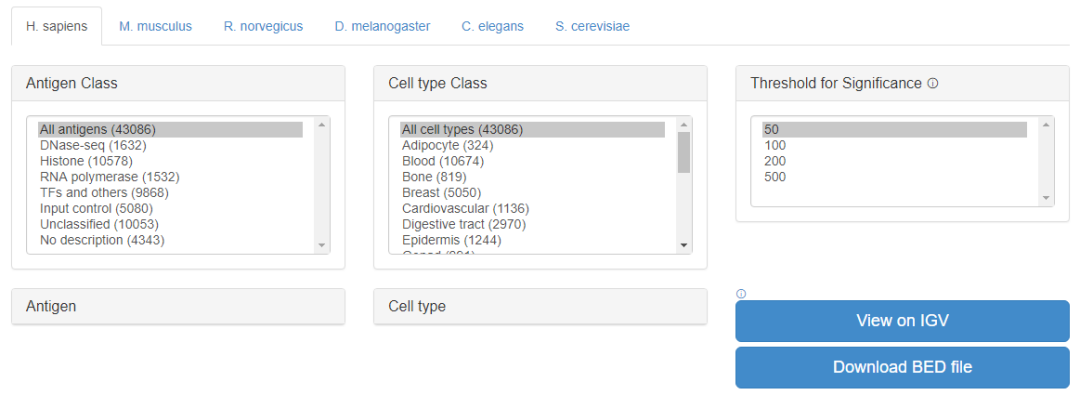
可以下载BED格式的结果。
定义TSS上下游的区间作为靶基因的筛选范围,如果peak与某个基因的TSS两侧范围存在交集,则认为该基因是候选的靶基因之一。搜索框如下所示
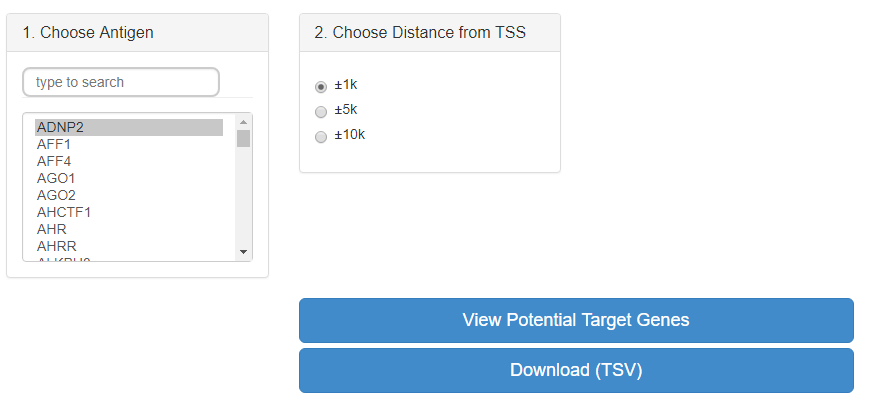
检索结果如下

有些转录因子在行使功能时是通过蛋白复合体的形式来发挥作用,比如Pou5f1,Nanog, Sox2这三个转录因子,它们对应的peak区间在基因上的位置是非常的邻近的,Colocalization分析就是比较多个转录因子的chip数据,来识别潜在的蛋白复合体,检索框如下
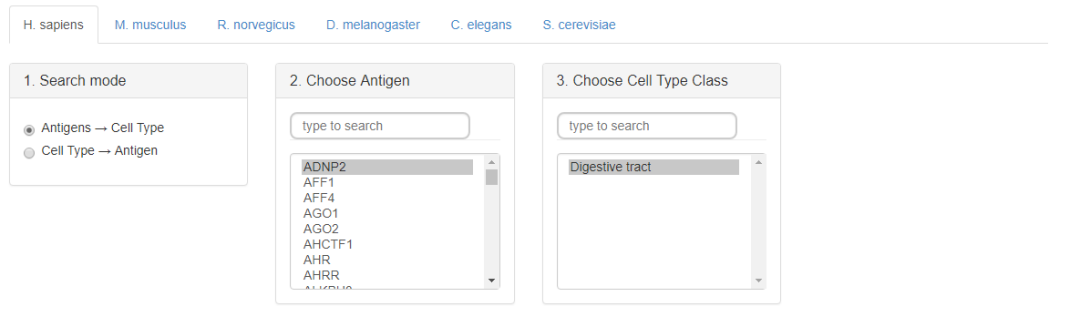
检索结果如下

和靶基因分析正好相反,靶基因是输入转录因子的名称,查询预测的靶基因,而这部分内容是输入基因名称或者基因组区域,查询可以结合的转录因子。检索框如下所示
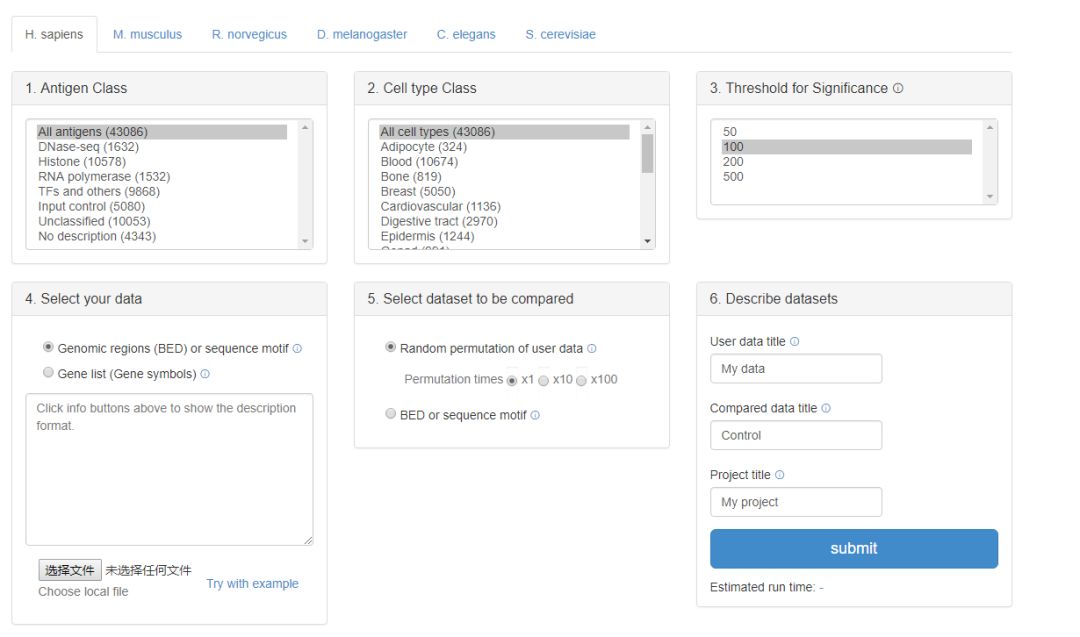
结果示意如下

通过ChIP-Atlas网站,可以方便的查询已有的chip_seq数据结果。
关于ChIP-Atlas中基于公共数据如何进行分析挖掘问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4580290/blog/4570674



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



