今天小编给大家分享一下c++字符串匹配的知识点有哪些的相关知识点,内容详细,逻辑清晰,相信大部分人都还太了解这方面的知识,所以分享这篇文章给大家参考一下,希望大家阅读完这篇文章后有所收获,下面我们一起来了解一下吧。
字符串匹配
我们在字符串 A 中查找字符串 B,那字符串 A 就是主串,字符串 B 就是模式串。我们把主串的长度记作 n,模式串的长度记作 m。因为我们是在主串中查找模式串,所以 n>m。
单模式串匹配的算法:也就是一个串跟一个串进行匹配
BF 算法中的 BF 是 Brute Force 的缩写,中文叫作暴力匹配算法,也叫朴素匹配算法。我们在主串中,检查起始位置分别是 0、1、2…n-m 且长度为 m 的 n-m+1 个子串,看有没有跟模式串匹配的。BF 算法的时间复杂度很高,是 O(n*m)
实际的开发中,它却是一个比较常用的字符串匹配算法,绝大部分情况下,朴素的字符串匹配算法就够用了。
实际的软件开发中,大部分情况下,模式串和主串的长度都不会太长。
朴素字符串匹配算法思想简单,代码实现也非常简单。满足KISS(Keep it Simple and Stupid)设计原则
RK 算法的全称叫 Rabin-Karp 算法,是由它的两位发明者 Rabin 和 Karp 的名字来命名的。思路是这样的:我们通过哈希算法对主串中的 n-m+1 个子串分别求哈希值,然后逐个与模式串的哈希值比较大小。如果某个子串的哈希值与模式串相等,那就说明对应的子串和模式串匹配了(无哈希冲突)。如果有哈希冲突,再对比一下子串和模式串本身。
RK 算法的效率要比 BF 算法高,RK 算法整体的时间复杂度就是 O(n)。不过这样的效率取决于哈希算法的设计方法,如果存在冲突的情况下,时间复杂度可能会退化。极端情况下,哈希算法大量冲突,时间复杂度就退化为 O(n*m)。
要求:设计hash算法。找出两个子串 s[i-1] 和 s[i]关系(其实就是abcde, bad表示相同子串, a与e的关系)。
BM (Boyer-Moore)算法:它的性能是著名的KMP 算法的 3 到 4 倍。当遇到不匹配的字符时,找规律,将模式串往后多滑动几位。
BM 算法包含两部分,分别是坏字符规则(bad character rule)和好后缀规则(good suffix shift)。
坏字符规则:从模式串的末尾往前倒着匹配,当我们发现某个字符没法匹配的时候。我们把这个没有匹配的字符叫作坏字符(主串中的字符)
当发生不匹配的时候,我们把坏字符对应的模式串中的字符下标记作 si。如果坏字符在模式串中存在,我们把这个坏字符在模式串中(最靠后的一个)的下标记作 xi。如果不存在,我们把 xi 记作 -1。那模式串往后移动的位数就等于 si-xi。(注意,我这里说的下标,都是字符在模式串的下标)。
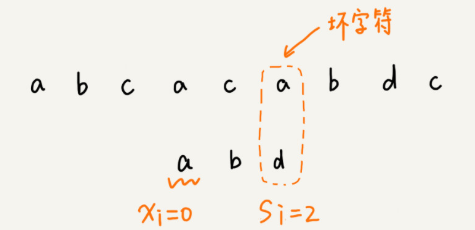
需要bc数组,记录模式串所有字符位置。
缺点:单纯使用坏字符规则还是不够的。因为根据 si-xi 计算出来的移动位数,有可能是负数,比如主串是 aaaaaaaaaaaaaaaa,模式串是 baaa。
好后缀规则:
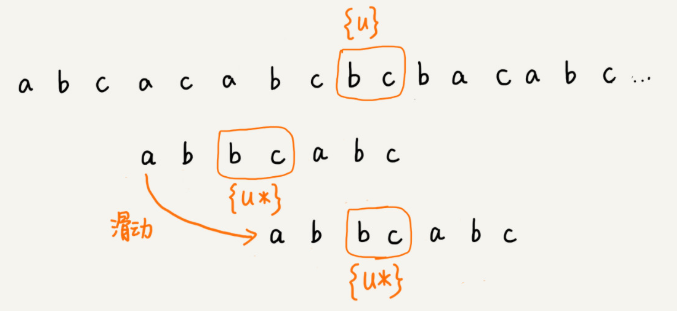
当好后缀{u}在模式串中查找,如果找到了另一个跟{u}相匹配的子串{u*},那我们就将模式串滑动到子串{u*}与主串中{u}对齐的位置。
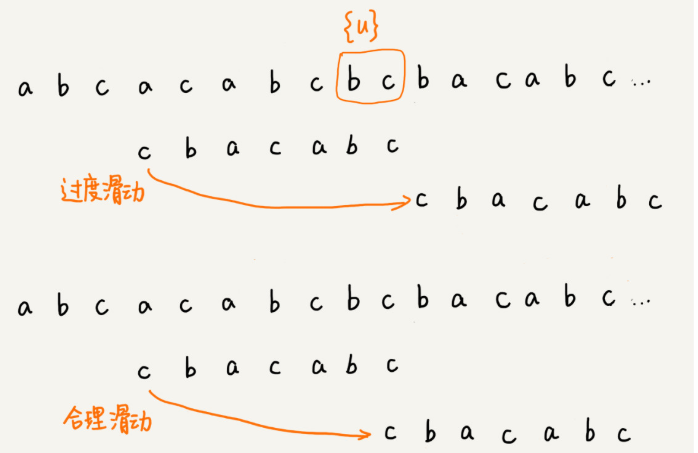
当好后缀{u}在模式串中查找,不存在另一个跟{u}相匹配的子串{u*},不能过度滑动到主串中{u}的后面。而是,从好后缀的后缀子串中,找一个最长的并且能跟模式串的前缀子串匹配的,假设是{v},然后将模式串滑动到如图所示的位置。
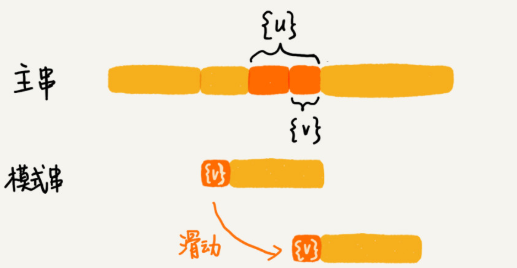
abc 的后缀子串就包括 c, bc。 abc 的前缀子串有 a,ab。
算法实现:
坏字符规则实现
利用散列表存储模式串每个字符位置下标,相同字符,记录最后出现下标
起始下标i,模式串从后往前匹配,遇到坏字符。找到坏字符对应模式串中的下标是si, 找到坏字符在模式串中最后出现位置xi (利用散列表,key=字符,value=下标,没有计为-1),
计算滑动i = i + (j - bc[(int)a[i+j]]);
好后缀规则实现(坏字符不在模式串m中最后一个位置)
预处理模式串,用数组存。每个数组元素记录另一个可匹配后缀子串的位置。如下图suffix[1],表示长度为1的子串,最后匹配的子串下标为2.
除了 suffix 数组之外,我们还需要另外一个 boolean 类型的 prefix 数组,来记录模式串的后缀子串是否能匹配模式串的前缀子串。

如何来计算并填充这两个数组的值?
拿下标从 0 到 i 的子串(i 可以是 0 到 m-2)与整个模式串,求公共后缀子串。如果公共后缀子串的长度是 k,那我们就记录 suffix[k]=j(j 表示公共后缀子串的起始下标)。如果 j 等于 0,也就是说,公共后缀子串也是模式串的前缀子串,我们就记录 prefix[k]=true。
private void generateGS(char[] b, int m, int[] suffix, boolean[] prefix) {
// 初始化
for (int i = 0; i < m; ++i) {
suffix[i] = -1;
prefix[i] = false;
}
// abcde的好后缀是bcde,所以要减去一
// 前缀串b[0,m-2]与后缀串b[1,m-1]求公共后缀子串,以b[m-1] 为比较
// 比如cab 与b 求后缀子串
for (int i = 0; i < m - 1; i++) {
int j = i;
int k = 0;
while (j >= 0 && b[j] == b[m - 1 - k]) {
++k;
suffix[k] = j;
--j;
}
if (j == -1) {
prefix[k] = true;
}
}
}
abc 的后缀子串就包括 c, bc。后缀子串必须有最后一个值。 abc 的前缀子串有 a,ab。前缀子串必须有第一个值
求前缀子串与后缀子串的公共后缀子串,并记录前缀子串是否可完全匹配。
通过好后缀长度k,判断,是否存在另一匹配后缀。suffix[k]!=-1, 滑动j-x+1位。
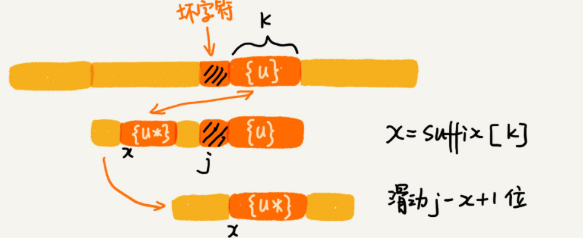
好后缀{u}, 不在模式串中存在时。就需要找,后缀子串中是否有匹配的前缀子串。j为坏字符下标,循环找(r<=m-1)好后缀的后缀子串为b[r,m-1],r=j+2(是因为求好后缀的后缀子串) ,长度 k=m-r,判断是否匹配前缀串,如果prefix[k]=true,滑动r位。
如果两条规则都没有找到可以匹配好后缀及其后缀子串的子串,我们就将整个模式串后移 m 位。
平均的情况时间复杂度O(n/m),空间复杂度bc[], prefix[],suffix[] O(m+bc.length)
因为好后缀和坏字符规则是独立的,如果我们运行的环境对内存要求苛刻,可以只使用好后缀规则,不使用坏字符规则,这样就可以避免 bc 数组过多的内存消耗。不过,单纯使用好后缀规则的 BM 算法效率就会下降一些了。
实际上,我前面讲的 BM 算法是个初级版本。为了让你能更容易理解,有些复杂的优化我没有讲。基于我目前讲的这个版本,在极端情况下,预处理计算 suffix 数组、prefix 数组的性能会比较差。比如模式串是 aaaaaaa 这种包含很多重复的字符的模式串,预处理的时间复杂度就是 O(m^2)。当然,大部分情况下,时间复杂度不会这么差。关于如何优化这种极端情况下的时间复杂度退化,如果感兴趣,你可以自己研究一下。
实际上,BM 算法的时间复杂度分析起来是非常复杂,这篇论文“A new proof of the linearity of the Boyer-Moore string searching algorithm”证明了在最坏情况下,BM 算法的比较次数上限是 5n。这篇论文“Tight bounds on the complexity of the Boyer-Moore string matching algorithm”证明了在最坏情况下,BM 算法的比较次数上限是 3n。你可以自己阅读看看。
KMP 算法基本原理
KMP 算法是根据三位作者(D.E.Knuth,J.H.Morris 和 V.R.Pratt)的名字来命名的,算法的全称是 Knuth Morris Pratt 算法,简称为 KMP 算法。
在模式串和主串匹配的过程中,把不能匹配的那个字符仍然叫作坏字符,把已经匹配的那段字符串叫作好前缀。从前往后匹配
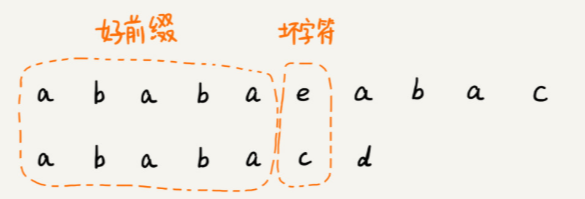
KMP 算法就是在试图寻找一种规律:在模式串和主串匹配的过程中,当遇到坏字符后,对于已经比对过的好前缀,能否找到一种规律,将模式串一次性滑动很多位?
思路:遇到坏字符,找好前缀的最长匹配前缀子串(好前缀的后缀子串与好前缀的前缀子串匹配)最后下标加1等于j,开始j与i 匹配。如果没有最长匹配前缀子串,j = 0, j 和i 继续比较, i 继续++。
查找好前缀的后缀子串中,最长匹配的那个好前缀的前缀子串{v},长度是 k .我们把模式串一次性往后滑动 j-k 位,相当于,每次遇到坏字符的时候,我们就把 j 更新为 k,i 不变,然后继续比较。

为了表述起来方便,我把好前缀的所有后缀子串中,最长的可匹配前缀子串的那个后缀子串,叫作最长可匹配后缀子串;对应的前缀子串,叫作最长可匹配前缀子串
最长可匹配后缀子串和最长可匹配前缀子串是相同的,只是位置不一样,如下图

如何求好前缀的最长可匹配前缀最后字符下标呢?
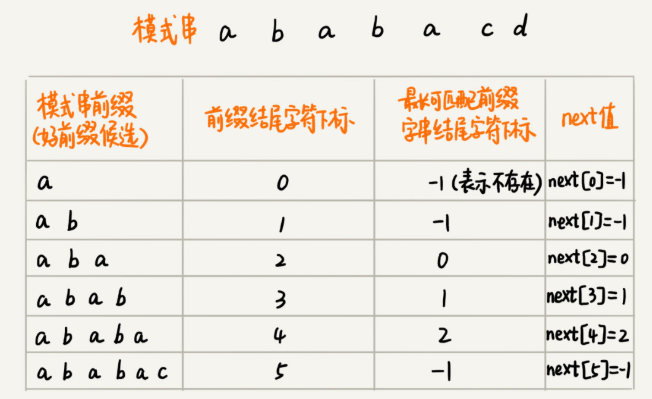
找到模式串的所有好前缀,与自身比较(求最长可匹配前缀,[前缀后缀相匹配]),求得next数组,数组的下标是每个好前缀结尾字符下标,数组的值是这个好前缀的最长可以匹配前缀子串的结尾字符下标。两个下标
next算法思路:
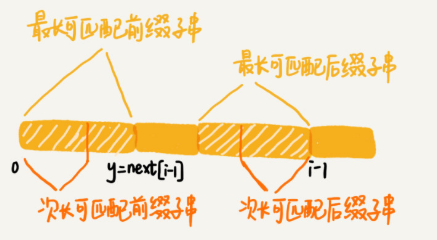
可以利用next[i-1] 求next[i].
考察完所有的 b[0, i-1] 的可匹配后缀子串 b[y, i-1], 如果它对应的前缀子串的下一个字符等于 b[i],那这个 b[y, i] 就是 b[0, i] 的最长可匹配后缀子串。
以ababacd为例,char数组为arr,当i=5, arr[i] = 'c' , 此时k = 2 , arr[k+1]!=arr[i] 不匹配, 找arr[0,i-1] 中次长可匹配子串最后下标位置。可以通过在arr[0,i-1]中0到最长可以匹配前缀子串的结尾字符下标next[k]找, 找最长可匹配前缀下标,再判断。
// b 表示模式串,m 表示模式串的长度 ababacd
private int[] getNexts(char[] b, int m) {
int[] next = new int[m];
next[0] = -1; // 好前缀为一个字符,省去操作,记为-1
int k = -1;
for (int i = 1; i < m; ++i) {
while (k != -1 && b[k + 1] != b[i]) {
k = next[k]; // 巧妙
}
// 好前缀, 前缀字符和后缀字符
// aa next[1]=0
// aba next[2] = 0 | abab next[3] = 1 | ababa next[4]=2
if (b[k + 1] == b[i]) {
++k;
}
// i 为好前缀结尾下标字符
// next[i] 表示最长可以匹配前缀子串的结尾字符下标
next[i] = k;
}
return next;
}
{ 上面理解了,这里就不必看了
利用已经计算出来的 next 值,我们是否可以快速推导出 next[i] 的值呢?
如果 next[i-1]=k-1(最长可匹配前缀子串最后下标),也就是说,子串 b[0, k-1] 是 b[0, i-1] 的最长可匹配前缀子串。如果子串 b[0, k-1] 的下一个字符 b[k],与 b[0, i-1] 的下一个字符 b[i] 匹配,那子串 b[0, k] 就是 b[0, i] 的最长可匹配前缀子串。
如果 b[0, k-1] 的下一字符 b[k] 跟 b[0, i-1] 的下一个字符 b[i] 不相等呢?这个时候就不能简单地通过 next[i-1] 得到 next[i] 了。这个时候该怎么办呢?
我们假设 b[0, i] 的最长可匹配后缀子串是 b[r, i]。如果我们把最后一个字符去掉,那 b[r, i-1] 肯定是 b[0, i-1] 的可匹配后缀子串,但不一定是最长可匹配后缀子串,如abaabab。
既然 b[0, i-1] 最长可匹配后缀子串对应的前缀子串的下一个字符并不等于 b[i],那么我们就可以考察 b[0, i-1] 的次长可匹配后缀子串 b[x, i-1] 对应的可匹配前缀子串 b[0, i-1-x] 的下一个字符 b[i-x] 是否等于 b[i]。如果等于,那 b[x, i] 就是 b[0, i] 的最长可匹配后缀子串。
}
KMP 算法只需要一个额外的 next 数组,数组的大小跟模式串相同。所以空间复杂度是 O(m),m 表示模式串的长度。next 数组计算的时间复杂度是 O(m)。
所以,综合两部分的时间复杂度,KMP 算法的时间复杂度就是 O(m+n)。
多模式串匹配算法:也就是在一个串中同时查找多个串
利用:trie 树
ac自动机
AC 自动机算法,全称是 Aho-Corasick 算法。AC 自动机实际上就是在 Trie 树之上,加了类似 KMP 的 next 数组,只不过此处的 next 数组是构建在树上罢了。
AC 自动机的构建,包含两个操作:
将多个模式串构建成 Trie 树;
在 Trie 树上构建失败指针(相当于 KMP 中的失效函数 next 数组)。要构建每个节点的失败指针,需要一个队列。
Trie 树中的每一个节点都有一个失败指针。p 的失败指针就是从 root 走到紫色节点形成的字符串 abc,跟所有模式串前缀匹配的最长可匹配后缀子串,就是箭头指的 bc 模式串。
字符串 abc 的后缀子串有两个 bc,c,我们拿它们与其他模式串匹配,如果某个后缀子串可以匹配某个模式串的前缀,那我们就把这个后缀子串叫作可匹配后缀子串。
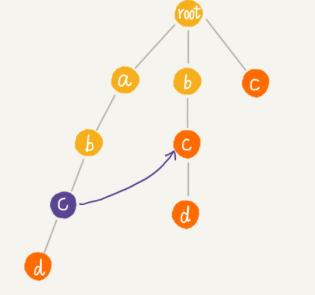 后缀子串(bc,c )跟模式串的前缀匹配
后缀子串(bc,c )跟模式串的前缀匹配
规律:如果我们把树中相同深度的节点放到同一层,那么某个节点的失败指针只有可能出现在它所在层的上一层。
我们可以像 KMP 算法那样,当我们要求某个节点的失败指针的时候,我们通过已经求得的、深度更小的那些节点的失败指针来推导。也就是说,我们可以逐层依次来求解每个节点的失败指针。所以,失败指针的构建过程,是一个按层遍历树的过程。
首先 root 的失败指针为 NULL,也就是指向自己。当我们已经求得某个节点 p 的失败指针之后,如何寻找它的子节点的失败指针呢?
我们假设节点 p 的失败指针指向节点 q,我们看节点 p 的子节点 pc 对应的字符,是否也可以在节点 q 的子节点中找到。如果找到了节点 q 的一个子节点 qc,对应的字符跟节点 pc 对应的字符相同,则将节点 pc 的失败指针指向节点 qc。
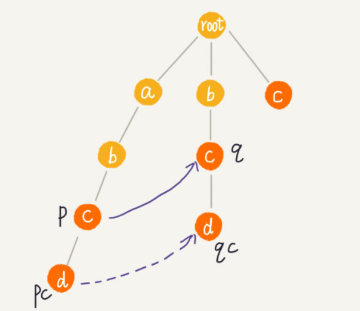
如果节点 q 中没有子节点的字符等于节点 pc 包含的字符,则令 q=q->fail(fail 表示失败指针,这里有没有很像 KMP 算法里求 next 的过程?),继续上面的查找,直到 q 是 root 为止,如果还没有找到相同字符的子节点,就让节点 pc 的失败指针指向 root。
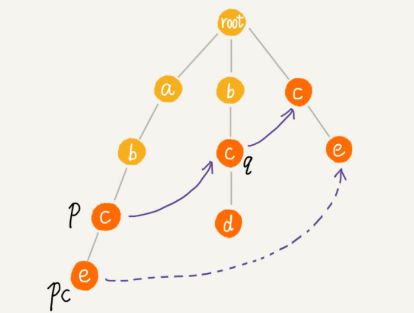
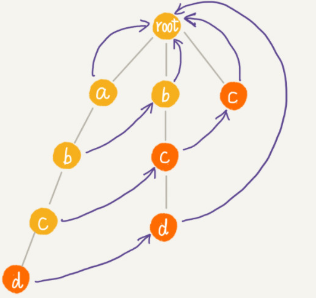
如何在 AC 自动机上匹配主串?
主串遍历,在root每一个分支匹配,当某个分支匹配了一部分如a->b->c,下一个d没匹配到,就用失败指针c = c ->fail (失败指针指向的位置,前面都是匹配的。),再接着匹配。
AC 自动机实现的敏感词过滤系统,是否比单模式串匹配方法更高效呢?
首先,我们需要将敏感词构建成 AC 自动机,包括构建 Trie 树以及构建失败指针。Trie 树构建的时间复杂度是 O(m*len),其中 len 表示敏感词的平均长度,m 表示敏感词的个数。那构建失败指针的时间复杂度是多少呢?
假设 Trie 树中总的节点个数是 k,每个节点构建失败指针的时候,(你可以看下代码)最耗时的环节是 while 循环中的 q=q->fail,每运行一次这个语句,q 指向节点的深度都会减少 1,而树的高度最高也不会超过 len,所以每个节点构建失败指针的时间复杂度是 O(len)。整个失败指针的构建过程就是 O(k*len)。
用 AC 自动机做匹配的时间复杂度是多少?
跟刚刚构建失败指针的分析类似,for 循环依次遍历主串中的每个字符,for 循环内部最耗时的部分也是 while 循环,而这一部分的时间复杂度也是 O(len),所以总的匹配的时间复杂度就是 O(n*len)。因为敏感词并不会很长,而且这个时间复杂度只是一个非常宽泛的上限,实际情况下,可能近似于 O(n),所以 AC 自动机做敏感词过滤,性能非常高。
以上就是“c++字符串匹配的知识点有哪些”这篇文章的所有内容,感谢各位的阅读!相信大家阅读完这篇文章都有很大的收获,小编每天都会为大家更新不同的知识,如果还想学习更多的知识,请关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/lidb/blog/4556596



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



