Spark Streaming初步使用以及工作原理是什么,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
1.什么是流?
Streaming:是一种数据传送技术,它把客户机收到的数据变成一个稳定连续的
流,源源不断地送出,使用户听到的声音或看到的图象十分平稳,而且用户在
整个文件送完之前就可以开始在屏幕上浏览文件。
2.常见的流式计算框架
Apache Storm
Spark Streaming
Apache Samza
上述三种实时计算系统都是开源的分布式系统,具有低延迟、可扩展和容错性
诸多优点,它们的共同特色在于:允许你在运行数据流代码时,将任务分配到
一系列具有容错能力的计算机上并行运行。此外,它们都提供了简单的API来
简化底层实现的复杂程度。
对于上面的三种流使计算框架的比较可以参考这篇文章流式大数据处理的三种框架:Storm,Spark和Samza
1.Spark Streaming介绍
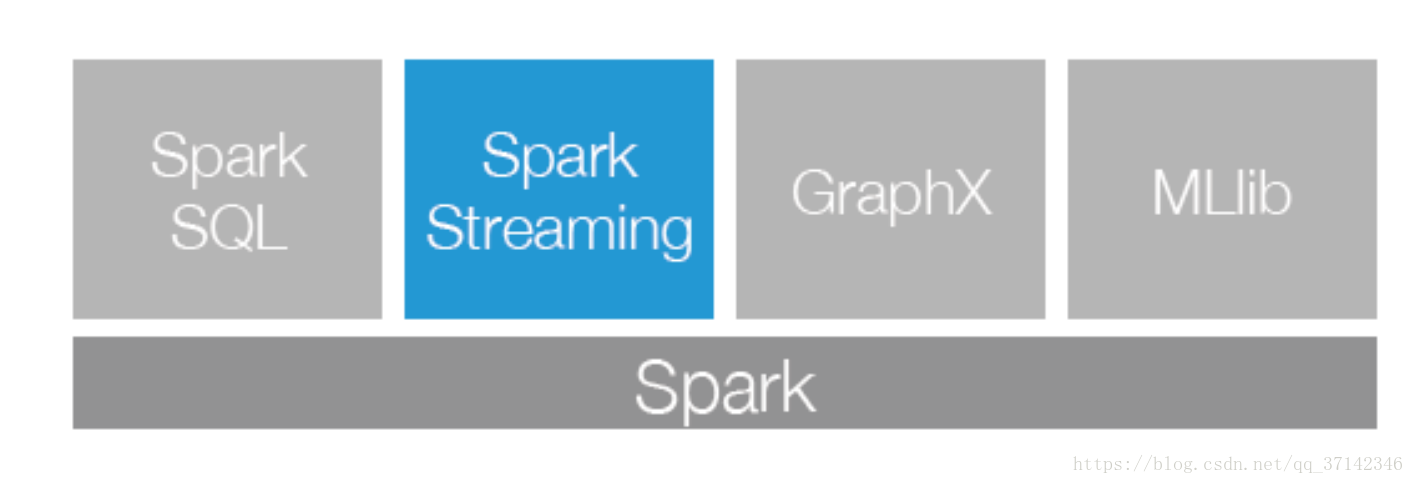
Spark Streaming是Spark生态系统当中一个重要的框架,它建立在Spark Core之上,下面这幅图也可以看出Sparking Streaming在Spark生态系统中地位。
官方对于Spark Streaming的解释如下:
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams. Data can be ingested from many sources like Kafka, Flume, Twitter, ZeroMQ, Kinesis or TCP sockets can be processed using complex algorithms expressed with high-level functions like map, reduce, join and window. Finally, processed data can be pushed out to filesystems, databases, and live dashboards. In fact, you can apply Spark’s machine learning and graph processing algorithms on data streams.
Spark Streaming有以下特点:
高可扩展性,可以运行在上百台机器上(Scales to hundreds of nodes)
低延迟,可以在秒级别上对数据进行处理(Achieves low latency)
高可容错性(Efficiently recover from failures)
能够集成并行计算程序,比如Spark Core(Integrates with batch and interactive processing)
2.Spark Streaming工作原理
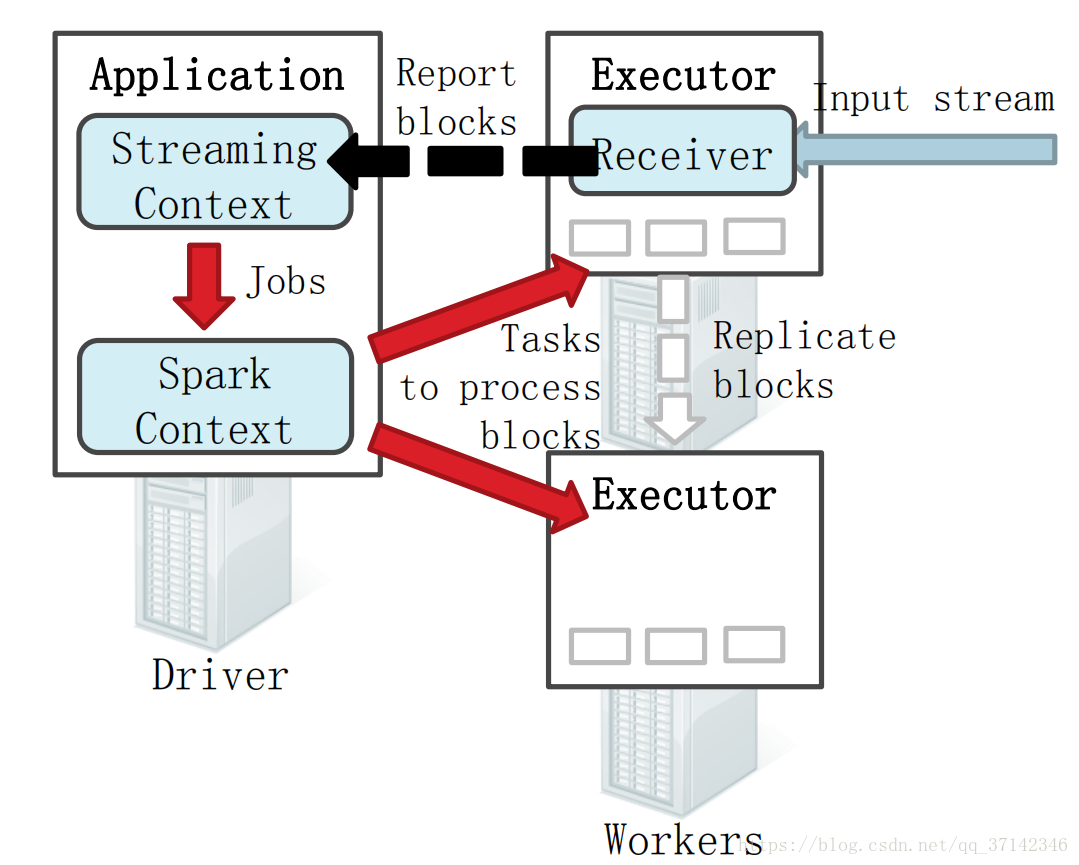
对于Spark Core它的核心就是RDD,对于Spark Streaming来说,它的核心是DStream,DStream类似于RDD,它实质上一系列的RDD的集合,DStream可以按照秒数将数据流进行批量的划分。首先从接收到流数据之后,将其划分为多个batch,然后提交给Spark集群进行计算,最后将结果批量输出到HDFS或者数据库以及前端页面展示等等。可以参考下面这幅图来帮助理解:
我们都知道Spark Core在初始化时会生成一个SparkContext对象来对数据进行后续的处理,相对应的Spark Streaming会创建一个Streaming Context,它的底层是SparkContext,也就是说它会将任务提交给SparkContext来执行,这也很好的解释了DStream是一系列的RDD。当启动Spark Streaming应用的时候,首先会在一个节点的Executor上启动一个Receiver接受者,然后当从数据源写入数据的时候会被Receiver接收,接收到数据之后Receiver会将数据Split成很多个block,然后备份到各个节点(Replicate Blocks 容灾恢复),然后Receiver向StreamingContext进行块报告,说明数据在那几个节点的Executor上,接着在一定间隔时间内StreamingContext会将数据处理为RDD并且交给SparkContext划分到各个节点进行并行计算。
3.Spark Streaming Demo
介绍完Spark Streaming的基本原理之后,下面来看看如何运行Spark Streaming,官方给出了一个例子,从Socket源端监控收集数据运行wordcount的案例,案例很简单,这里不再说明,读者可参考官方文档【http://spark.apache.org/docs/1.3.0/streaming-programming-guide.html】
对于Spark Streaming的编程模型有两种方式
第一种:通过SparkConf来创建SparkStreaming
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
val conf=new SparkConf().setAppName("SparkStreamingDemo").setMaster("master")
val scc=new StreamingContext(conf,Seconds(1)) //每个1秒钟检测一次数据1
2
3
4
5
第二种:通过SparkContext来创建,也就是在Spark-Shell命令行运行:
import org.apache.spark.streaming._
val scc=new StreamingContext(sc,Seconds(1))1
2
当然,我们也可以收集来自HDFS文件系统中数据,查阅Spark的源码,可以发现如下方法:
这个方法会监控指定HDFS文件目录下的数据,不过忽略以“.”开头的文件,也就是不会收集以“.”开头的文件进行数据的处理。
下面介绍一下如何从HDFS文件系统上监控数据运行wordcount案例统计单词数并且将结果打印出来的案例:
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
val ssc = new StreamingContext(sc, Seconds(5))
// read data
val lines = ssc.textFileStream("hdfs://hadoop-senior.shinelon.com:8020/user/shinelon/spark/streaming/")
// process
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
上面程序会每个5秒钟检测一下HDFS文件系统下的hdfs://hadoop-senior.shinelon.com:8020/user/shinelon/spark/streaming/目录是否有新的数据,如果有就进行统计,然后将结果打印在控制台。运行上面代码有两种方式,可以运行Spark-shell客户端后将上述命令一条条粘贴到命令行执行,显然这样很麻烦;第二种就是将上面的程序写入到一个脚本文件中加载到Spark-shell命令行中执行,这里采用第二种方式:
在一个目录下创建SparkStreamingDemo.scala文件,内容如上面的代码所示。然后启动Spark-shell客户端。
$ bin/spark-shell --master local[2]1
然后加载Spark Streaming应用:
scala>:load /opt/cdh-5.3.6/spark-1.3.0-bin-2.5.0-cdh6.3.6/SparkStreamingDemo.scala1
然后上传数据到上述HDFS文件目录下:
$ bin/hdfs dfs -put /opt/datas/wc.input /user/shinelon/spark/streaming/input71
该文件内容如下所示:
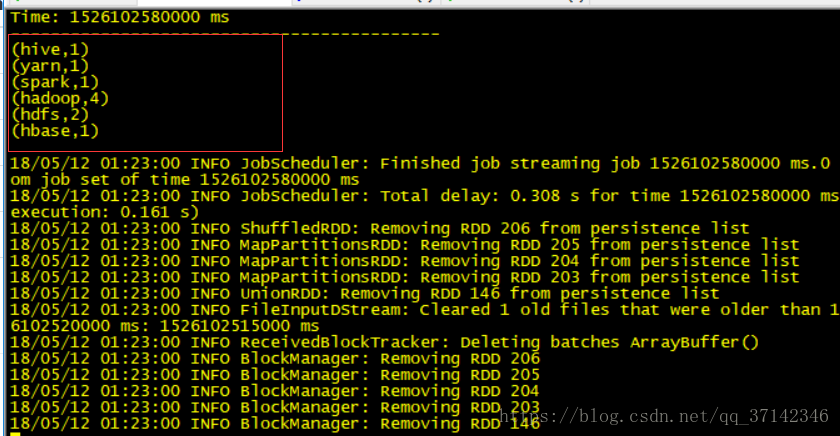
hadoop hive hadoop hbase hadoop yarn hadoop hdfs hdfs spark
1
2
3
4
5
运行结果如下所示:
通常对于一个Spark Streaming的应用程序的编写分下面几步:
定义一个输入流源,比如获取socket端的数据,HDFS,kafka中数据等等
定义一系列的处理转换操作,比如上面的map,reduce操作等等,Spark Streaming也有类似于SparkCore的transformation操作
启动程序收集数据(start())
等待程序停止(遇到错误终止或者手动停止awaitTermination())
手动终止应用程序(stop())
可以使用saveAsTextFiles()方法将结果输出到HDFS文件系统上,读者可以自行试验将结果存入HDFS文件系统中。
最后,介绍一下Spark Streaming应用程序开发的几种常见方式:
Spark Shell Code:开发、测试(上面提到过,将代码一条条粘贴到命令行执行,这种方式只适用于测试)
Spark Shell Load Scripts:开发、测试(编写scala脚本到spark-shell中执行)
IDE Develop App:开发、测试、打包JAR(生产环境),spark-submit提交应用程序
看完上述内容,你们掌握Spark Streaming初步使用以及工作原理是什么的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4579082/blog/4555858



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务