R (http://www.r-project.org) 系统是用于统计分析和图形化的计算机语言及分析工具,为了保证性能,其核心计算模块是用C、C++和Fortran编写的。同时为了便于使用,它提供了一种脚本语言,即R语言。R语言和贝尔实验室开发的S语言类似。R支持一系列分析技术,包括统计检验、预测建模、数据可视化等等。在CRAN(http://cran.r-project.org) 上可以找到众多开源的扩展包。
R软件的首选界面是命令行界面,通过编写脚本来调用分析功能。如果缺乏编程技能,也可使用图形界面,比如使用RCommander(http://socserv.mcmaster.ca/jfox/Misc/Rcmdr/)或Rattle(http://rattle.togaware.com)。[2]
另外,由于R系统是本文研究的重点,所以会花费较大篇幅对其各种特性、优势及不足进行较为细致的分析。
如前所述,R系统是一种脚本语言,它主要以命令方式提供了对各种数据的处理和统计分析过程,主要能力或功能描述如下:
1.数据导入和导出:可以从文件中获取数据,将处理结果存放到数据文件中;如HousePrice <- read.table("houses.data");data(Puromycin, package="datasets");attach(“faithful”)
2.向量数据处理能力:它可以处理向量数据(包括数值、逻辑和字符串),也可以按一定规则生成向量数据;支持向量运算(+、-、*、/、幂运算);
n向量赋值:x <- c(10.4, 5.6, 3.1, 6.4, 21.7);y <- c(x, 0, x)
n向量运算:1/x;v <- 2*x + y + 1;sum((x-mean(x))^2)/(length(x)-1)
n向量生成:z <- 0:9;s4 <- seq(length=51,from=-5, by=.2)
3.复杂数据处理能力:支持矩阵、支持列表数据类型(元素不同)、数据帧(类似矩阵,但元素类型可不同);
因子(集合):
state <- c("tas", "sa", "qld","nsw", "nsw", "nt", "wa","wa","qld", "vic", "nsw","vic", "qld", "qld", "sa","tas","sa", "nt", "wa","vic", "qld", "nsw", "nsw","wa","sa", "act", "nsw","vic", "vic", "act");statef<- factor(state)
n数组或矩阵:dim(z) <- c(3,5,100);x <- array(1:20, dim=c(4,5))
n列表:Lst <- list(name="Fred", wife="Mary",no.children=3,child.ages=c(4,7,9))
n数据帧:accountants <- data.frame(home=statef, loot=incomes, shot=incomef)
4.支持函数:包括系统内置函数和用户定义函数;自定义函数举例如下:
twosam <- function(y1, y2) {
n1 <- length(y1); n2 <- length(y2)
yb1 <- mean(y1); yb2 <- mean(y2)
s1 <- var(y1); s2 <- var(y2)
s <- ((n1-1)*s1 + (n2-1)*s2)/(n1+n2-2)
tst <- (yb1 - yb2)/sqrt(s*(1/n1 + 1/n2))
tst
}
5.概率分布:支持多种概率分布模型,如下:
nBeta:贝塔分布
nBinomial:二项分布
nCauchy:柯西分布
nchi-squared:卡方分布
nexponential:指数分布
nF:F分布
nGamma:伽马分布
nGeometric:几何分布
nHypergeometric:超集合分布
nlog-normal:对数正态分布
nlogistic:对数分布
nnegativebinomial:负二项分布
nnormal:正态分布
nPoisson:泊松分布
nsignedrank:符号秩次分布
nStudent:学生氏分布
nUniform:单一分布
nWeibull:Weibull分布
nWilcoxon:威尔考克斯分布
以下为分布的举例:
n正态分布:
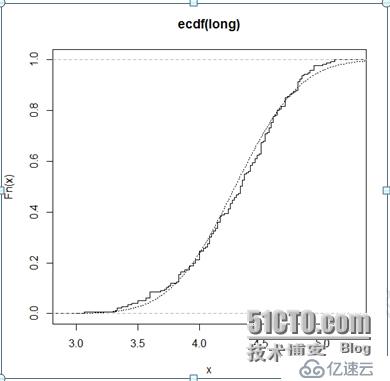
attach(faithful)
long <-eruptions[eruptions > 3]
plot(ecdf(long),do.points=FALSE, verticals=TRUE)
x <- seq(3, 5.4,0.01)
lines(x, pnorm(x, mean=mean(long),sd=sqrt(var(long))), lty=3)
上述命令生成的图如下:
n指数分布:
x <- seq(1, 5, 0.01)
plot(pexp(x,3))
生成的统计图如下:

6.支持条件语句和循环语句
条件语句:if (expr_1) expr_2 else expr_3
循环语句:
xc <- split(x, ind)
yc <- split(y, ind)
for (i in 1:length(yc)) {
plot(xc`i`, yc`i`)
abline(lsfit(xc`i`, yc`i`))
}
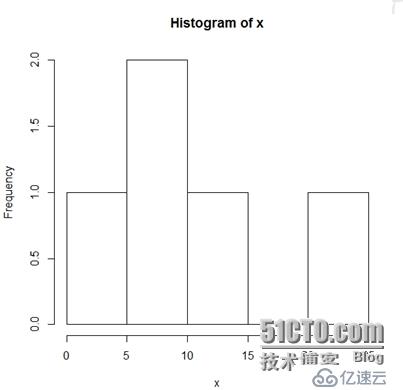
7.支持多种图型化的数据表达方式,举例如下(直方图):
x <- c(10.4, 5.6, 3.1, 6.4, 21.7)
hist(x)
R系统具有如下优势:
1.因其为单行命令模式,所以对于一般有开发经验的用户,简便易学,容易上手;
2.数据类型支持丰富;
3.支持的概率分布模型较全面,一般能满足日常使用;而且支持通用的假设检验方法;
4.支持流程控制和自定义函数。
但R系统也有如下缺点:
1.虽然简便易学,和纯粹基于图型的挖掘工具相较,使用起来仍不够直观、方便;
2.对使用人员而言,仍有一定的要求;
3.一般只能从文件中获取数据,无法和数据库系统相结合。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





