这篇文章主要介绍“python爬虫方法实例分析”,在日常操作中,相信很多人在python爬虫方法实例分析问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”python爬虫方法实例分析”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
1、Requests库:使用原理和方法
2、BeautifulSoup库:使用原理和方法
3、Requests库和BeautifulSoup库组合应用:举例实践
Requests库
import requestsres=requests.get('http://bj.xiaozhu.com/')print(res)#返回结果为<Response [200]>,说明请求网址成功,若为404,400则请求网址失败print(res.text)输出如下图:

有时候爬虫需要加入请求头来伪装成浏览器,以便更好抓取数据,在开发者工具中点击Network并且选择name,然后查看headers下拉查看到:User-Agent
请求头的使用方法:
import requestsheaders={}res=requests.get('http://bj.xiaozhu.com/',headers=headers)print(res.text)Requests库错误和异常主要有以下4种:
1、Requests抛出一个ConnectionError异常,网络问题(如DNS查询失败、拒绝连接等)
2、Response.raise_for_status()抛出一个HTTPError异常,原因为HTTP请求返回了不成功的状态码(网页不存在,返回404错误)
3、Response抛出一个Timeout异常,原因为请求超时
4、Response抛出一个TooManyRedirects异常,原因为请求超过了设定的最大重定向次数
所有异常继承自:requests.exceptions.RequestException
为了避免异常:
import requestsheaders={}res=requests.get('http://bj.xiaozhu.com/',headers=headers)try: print(res.text)except ConnectionError: print('拒绝连接')BeautifulSoup库
BeautifulSoup库可以轻松解析Requests库请求的网页,并把网页源代码解析为Soup文档,以便过滤提取数据。
import requestsfrom bs4 import BeautifulSoupheaders={}res=requests.get('http://bj.xiaozhu.com/',headers=headers)soup=BeautifulSoup(res.text,'html.parser')print(soup.prettify())输出Soup文档按照标准缩进格式结构输出,为结构化的数据,为数据的过滤提取做好准备。
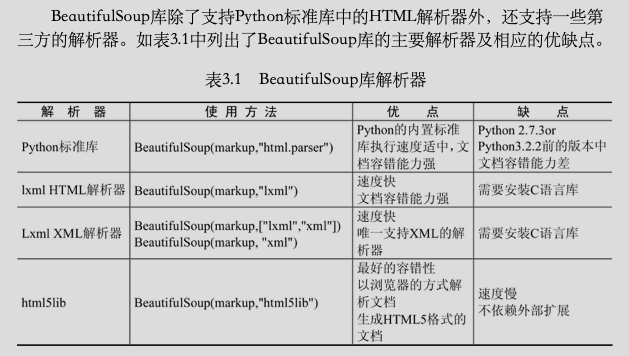
注意:BeautifulSoup库官方推荐使用lxml作为解析器,因为效率更高。
解析得到的Soup文档可以使用find()和find_all()方法及selector()方法定位需要的元素。
find_all(tag, attibutes, recursive, text, limit, keywords)
find(tag, attibutes, recursive, text, keywords)
备注:常用前两个参数
1、find_all()方法

2、find()方法

3、selector()方法
soup.selector(div.item>a>h2)#括号内容通过Chrome复制得到
(1)鼠标定位到想要提取的数据位置,右击,在弹出的快捷菜单中选择”检查“命令
(2)在网页源代码中右击所选元素
(3)在弹出的快捷菜单中选择Copy selector.
import requestsfrom bs4 import BeautifulSoupheaders={) Chrome/73.0.3683.86 Safari/537.36'}res=requests.get('http://bj.xiaozhu.com/',headers=headers)res.encoding = 'utf-8'soup=BeautifulSoup(res.text,'html.parser')#price=soup.select('#page_list > ul > li:nth-child(1) > div.result_btm_con.lodgeunitname > div:nth-child(1) > span > i')#price=soup.select('#page_list > ul > li:nth-of-type(1) > div.result_btm_con.lodgeunitname > div:nth-of-type(1) > span > i')prices=soup.select('#page_list > ul > li > div.result_btm_con.lodgeunitname > div > span > i')print(prices)for price in prices: print (price) #获取单条html信息 print (price.get_text()) #获取中间文字信息Requests库和BeautifulSoup库组合应用:举例实践
实践案例1:爬取北京地区短租房信息
1、爬虫思路分析
(1)本节爬取小猪短租网北京地区短租房10页信息。通过手动浏览,确认前4页网址如下:
http://bj.xiaozhu.com/
http://bj.xiaozhu.com/search-duanzufang-p2-0/
http://bj.xiaozhu.com/search-duanzufang-p3-0/
http://bj.xiaozhu.com/search-duanzufang-p4-0/
把第一页网址改为:
http://bj.xiaozhu.com/search-duanzufang-p1-0/后也能正常浏览,因此只需要更改p后面的数字就可以了,以此来构造10页网址
(2)本次爬虫在详细页面中进行,因此先需爬取进入详细页面的网址链接,进而爬取数据
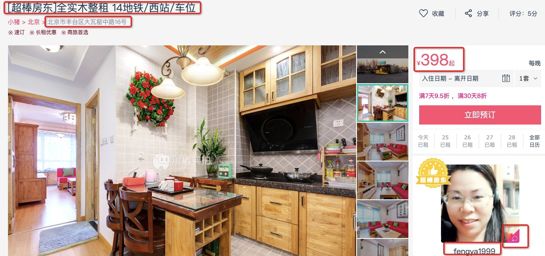
(3)需要爬取的信息有:标题、地址、价格、房东名称、房东性别和房东头像的链接
from bs4 import BeautifulSoupimport pandas as pdimport requestsimport timeimport lxml#加入请求头headers={}#定义判断用户性别的函数def judgment_sex(class_name): if class_name ==['member_icol']: return '女' else: return '男'#定义获取详细页URL的函数def get_links(url): wb_data=requests.get(url,headers=headers) #print(wb_data) soup=BeautifulSoup(wb_data.text,'lxml') #print(soup) links=soup.select('#page_list > ul > li > a') #links为url列表 #page_list > ul > li:nth-child(1) > a for link in links: href=link.get("href") get_info(href) #循环出的url,依次调用get_info()函数#定义获取网页信息的函数def get_info(url): wb_data=requests.get(url,headers=headers) soup=BeautifulSoup(wb_data.text,'lxml') #tittles=soup.select('div.pho_info>h5') #tittles=soup.select('#page_list > ul > li> div.result_btm_con.lodgeunitname > div.result_intro > a > span') tittles = soup.select('div.pho_info > h5') addresses = soup.select('span.pr5') prices = soup.select('#pricePart > div.day_l > span') imgs = soup.select('#floatRightBox > div.js_box.clearfix > div.member_pic > a > img') names = soup.select('#floatRightBox > div.js_box.clearfix > div.w_240 > h7 > a') sexs = soup.select('#floatRightBox > div.js_box.clearfix > div.member_pic > div') for tittle,address,price,img,name,sex in zip(tittles,addresses,prices,imgs,names,sexs): data={ 'tittle':tittle.get_text().strip(), 'address':address.get_text().strip(), 'price':price.get_text(), 'img':img.get("src"), 'name':name.get_text(), 'sex':judgment_sex(sex.get("class")) } #print(data)#获取信息并通过字典的信息打印 #print(pd.DataFrame([data]).head())if __name__ == '__main__': urls=['http://bj.xiaozhu.com/search-duanzufang-p{}-0/'.format(number) for number in range(1,2)] for single_url in urls: print(single_url) get_links(single_url) time.sleep(2)到此,关于“python爬虫方法实例分析”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4607696/blog/4483062



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



