这期内容当中小编将会给大家带来有关Pandas如何借助Python爬虫爬取HTML网页表格保存到Excel文件,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
如果一个HTML网页中有表格,怎样爬取下来?
Pandas的read_html可以很方便的解析URL地址或者HTML代码中的表格,直接转换成dataframe,用于后续的处理、分析、导出。
比如有这么一个案例,我自己经常使用网易有道词典查英文单词,经常将新单词加入到单词本,日积月累单词就越来越多,我想把这些单词都导出到excel,怎样可以集中复习甚至打印出来看。
可是网易有道词典没这个导出全部单词本的功能。
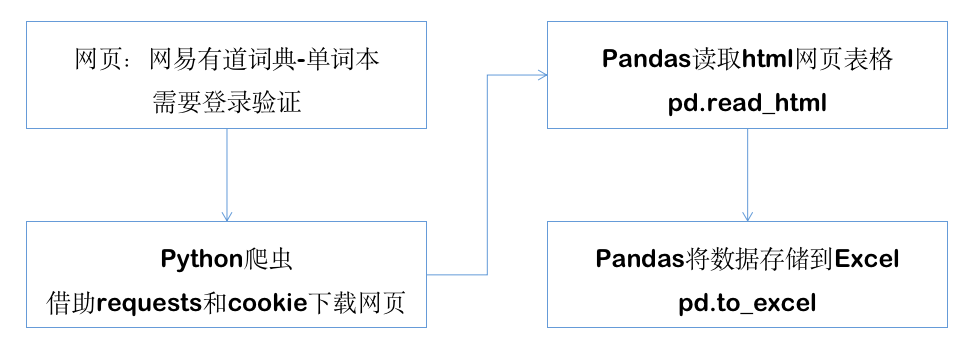
幸好,我在网易有道有道的PC版,发现了这样的单词本网页:

使用这样的技术组合,我可以很简单的爬取整个网页,并实现表格解析,输出到Excel文件:
Python爬虫,使用requests下载网页,其中的cookies参数能让我绕过登录验证;
Pandas的read_html能解析出来网页中的表格,然后使用to_excel能将结果保存成excel文件
流程是这样的:
而最终保存的excel,就是我要的所有单词列表:

Python爬虫+Pandas数据解析处理的绝佳搭档
上述就是小编为大家分享的Pandas如何借助Python爬虫爬取HTML网页表格保存到Excel文件了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





