Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为。Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms, Machines, and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。
192.168.174.141 hd1 master
192.168.174.142 hd2 slave1
192.168.174.143 hd3 slave2useradd hadoop
passwd hadoop
New password:
Retype new password:
授权 root 权限,在root下面加一条hadoop的hadoop ALL=(ALL) ALL
#修改权限
chmod 777 /etc/sudoers
vim /etc/sudoers
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL
#恢复权限
chmod 440 /etc/sudoers
#进入到我的home目录,
su - hadoop
ssh-keygen -t rsa (连续按四个回车)
#执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
#将公钥拷贝到要免密登录的机器上
ssh-copy-id hd2
ssh-copy-id hd3
#在h2,h3,h4机器上新建apps目录用于存放hadoop和spark安装包
mkdir -p /home/hadoop/apps/hadoop
cd /home/hadoop/apps/hadoop
#在hd1机器上 下载hadoop2.7.7(hd2,hd3上等在hd1把hadoop的相关配置改完后scp发送过去)
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
tar -zxvf hadoop-2.7.7.tar.gz
#配置环境变量
sudo vim /etc/profile
#添加HADOOP_HOME
export HADOOP_HOME=/home/hadoop/apps/hadoop/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
#刷新环境变量
source /etc/profile
#查看hadoop版本
hadoop version
#配置Hadoop的JAVA_HOME
cd /home/hadoop/apps/hadoop/hadoop-2.7.7/etc/hadoop
vim hadoop-env.sh
#大概在25行,添加
export JAVA_HOME=/opt/soft/java/jdk1.8.0_73
#修改配置文件
1、修改core-site.xml
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hd1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/apps/hadoop/hadoop-2.7.7/tmp</value>
</property>
</configuration>
2、修改hdfs-site.xml
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hd1:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/apps/hadoop/hadoop-2.7.7/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/apps/hadoop/hadoop-2.7.7/tmp/dfs/data</value>
</property>
</configuration>
3、修改mapred-site.xml
#目录下没有这个文件,复制一份出来
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hd1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hd1:19888</value>
</property>
</configuration>
4、修改yarn-site.xml
vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hd1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://hd1:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
5、修改slaves文件内容,该文件指定哪些服务器节点是datanode节点,删除里面的localhost
cd /home/hadoop/apps/hadoop/hadoop-2.7.7/etc/hadoop
vim slaves
hd1
hd2
hd3
#以上所有配置文件已经配好的,在hd1上将配置好的hadoop-2.7.7目录复制到hd2,hd3相同目录
cd /home/hadoop/apps/hadoop
scp -r hadoop-2.7.7 hadoop@hd2:/home/hadoop/apps/hadoop/
scp -r hadoop-2.7.7 hadoop@hd3:/home/hadoop/apps/hadoop/
scp /etc/profile root@hd2:/etc/
并在hd2上执行:source /etc/profile
scp /etc/profile root@hd3:/etc/
并在hd3上执行:source /etc/profile
# 格式化集群操作
#格式化namenode和datanode并启动,(在hd1(master)上执行就可以了 不需要在(hd2,hd3)slave上执行)
hdfs namenode -format
#关闭所有机器防火墙
service iptables stop
#启动hadoop集群
#依次执行两个命令
#启动hdfs
start-dfs.sh
#再启动
start-yarn.sh
#直接用一个命令也可以
start_all.sh
#验证是否启动成功,缺少以下任一进程都表示出错
#在hd1,hd2,hd3分别使用jps命令,可以看到
#hd1中显示
56310 NameNode
56423 DataNode
56809 ResourceManager
56921 NodeManager
56634 SecondaryNameNode
# hd2中显示
16455 NodeManager
16348 DataNode
#hd3显示
13716 DataNode
13823 NodeManager
#查看集群web页面
hdfs页面:http://hd1:50070/ 或者http://192.168.174.141:50070/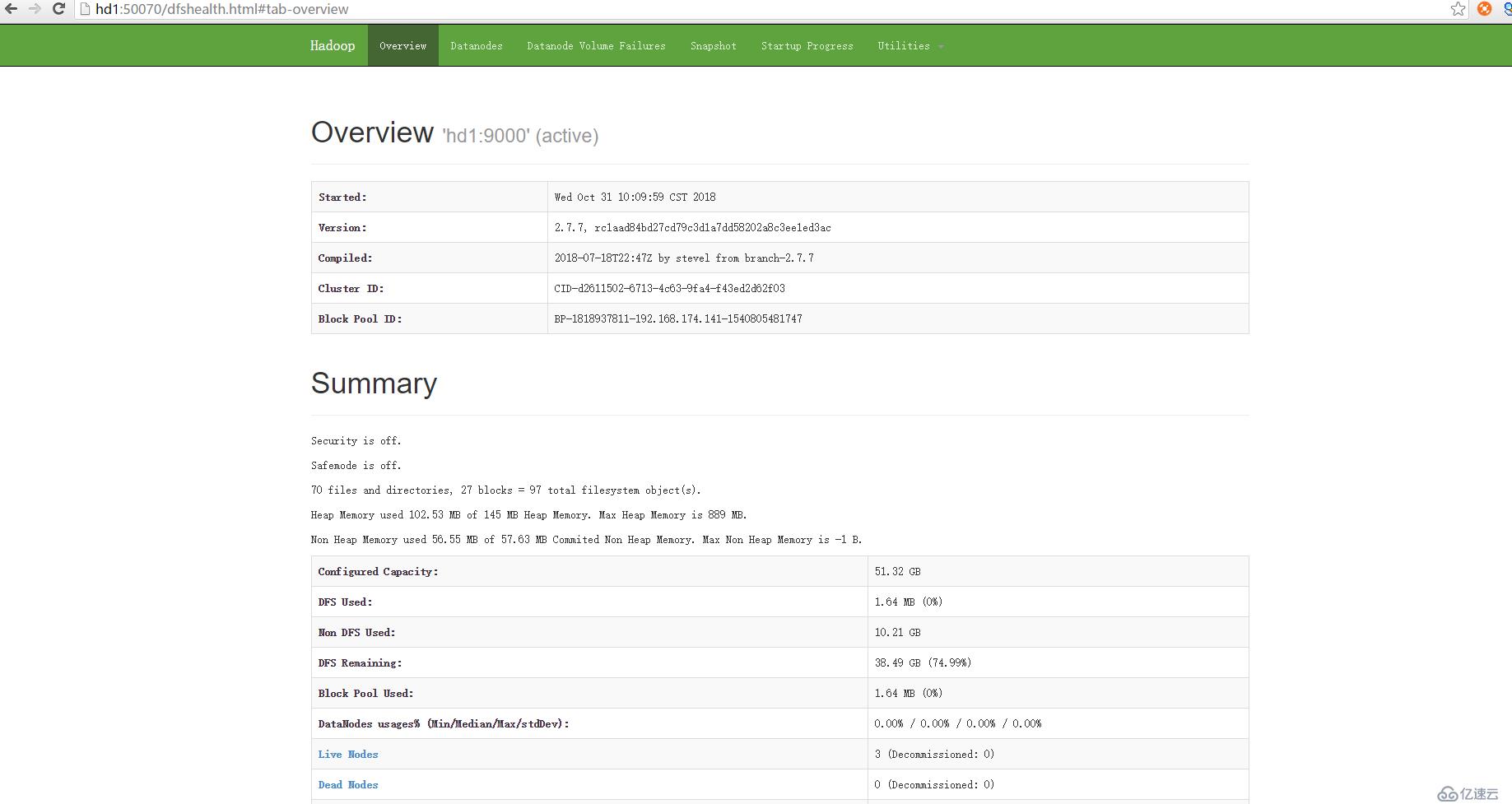
yarn页面:http://hd1:8088/ 或者http://192.168.174.141:8088/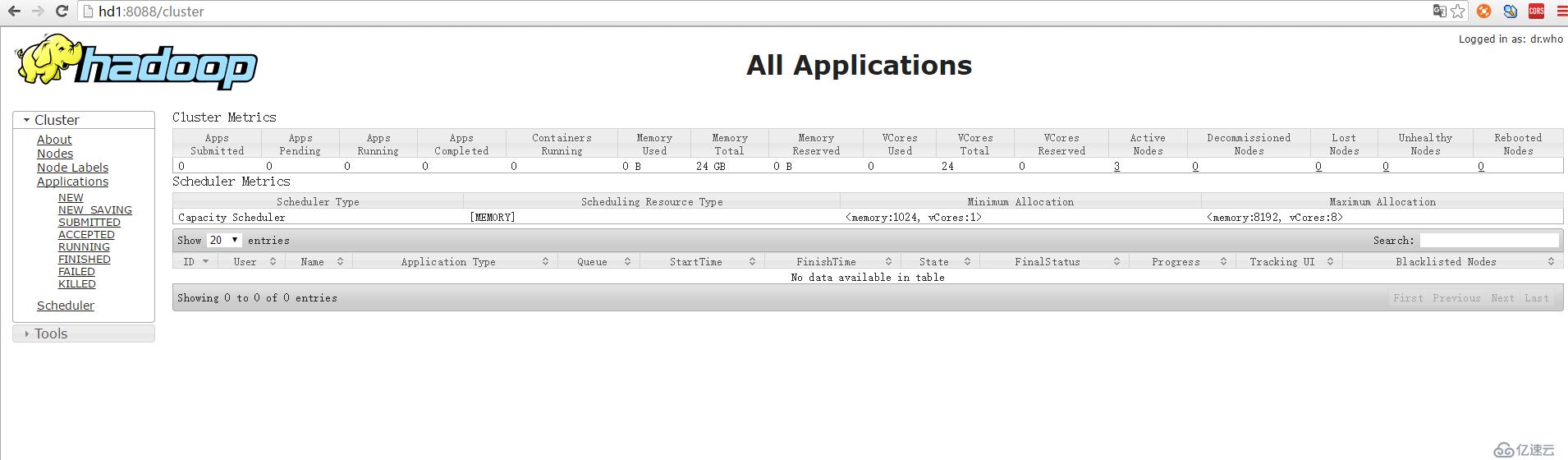
#停止集群命令:stop_dfs.sh和stop_yarn.sh或者stop_all.sh以上Hadoop的集群搭建过程已大功告成!
依赖环境:Scala
Spark是使用Scala编写的,用Scala编写Spark任务可以像操作本地集合对象一样操作分布式数据集RDD
安装Scalla和安装jdk如出一辙的操作,我这里给出scala的下载地址:https://downloads.lightbend.com/scala/2.11.7/scala-2.11.7.tgz
#安装完scala可以查看版本
scala -version
#这里重点介绍Spark的安装,相比于hadoop的安装要简单一些,而且步骤类似,话不多说,开始!
#在hd1机器用hadoop用户先创建spark的目录
cd /home/hadoop/apps
mkdir spark
cd spark
#下载spark安装包
wget https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.2.2/spark-2.2.2-bin-hadoop2.7.tgz
#解压
tar -zxvf /spark-2.2.2-bin-hadoop2.7.tgz
#重命名
mv spark-2.2.2-bin-hadoop2.7 spark-2.2.2
#修改环境变量
vim /etc/profile
export SPARK_HOME=/home/hadoop/apps/spark/spark-2.2.2
export PATH=$PATH:$SPARK_HOME/bin
#重新加载环境
source /etc/profile
#修改配置文件
cd /home/hadoop/apps/spark/spark-2.2.2/conf
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
#这里介绍两个spark的部署模式,一种是standalone模式,一种是spark on yarn模式,任选一种配置即可
#1、standalone模式
export JAVA_HOME=/opt/soft/java/jdk1.8.0_73
#Spark主节点的IP
export SPARK_MASTER_IP=hd1
#Spark主节点的端口号
export SPARK_MASTER_PORT=7077
#2、spark on yarn配置
export JAVA_HOME=/opt/soft/java/jdk1.8.0_73
export HADOOP_CONF_DIR=/home/hadoop/apps/hadoop/hadoop-2.7.7/etc/hadoop/
#修改slaves文件
cd /home/hadoop/apps/spark/spark-2.2.2/conf
vim slaves
hd2
hd3
#复制hd1中的spark到hd2和hd3机器中
cd /home/hadoop/apps/spark
scp -r spark-2.2.2/ hadoop@hd2:/home/hadoop/apps/spark
scp -r spark-2.2.2/ hadoop@hd3:/home/hadoop/apps/spark
#配置环境变量:分别修改hd2,hd3环境变量或者直接将hd1上的/etc/profile文件复制到hd2和hd3上。
vim /etc/profile
export SPARK_HOME=/home/hadoop/apps/spark/spark-2.2.2
export PATH=$PATH:$SPARK_HOME/bin
source /etc/profile
#至此,Spark集群配置完毕,启动Spark集群。
#启动spark集群前要先启动hadoop集群。
#Spark集群启动
cd /home/hadoop/apps/spark/spark-2.2.2/sbin
./start-all.sh
#测试Spark集群是否正常启动
#在hd1,hd2,hd3分别执行jps,
在hd1中显示:Master
63124 Jps
56310 NameNode
56423 DataNode
63064 Master
56809 ResourceManager
56921 NodeManager
56634 SecondaryNameNode
在hd2、hd3中显示:Worker
18148 Jps
16455 NodeManager
16348 DataNode
18079 Worker
#测试spark-shell和页面
cd /home/hadoop/apps/spark/spark-2.2.2/bin
./spark-shell
#访问页面地址:
http://hd1:8080/ 或者:http://192.168.174.141:8080/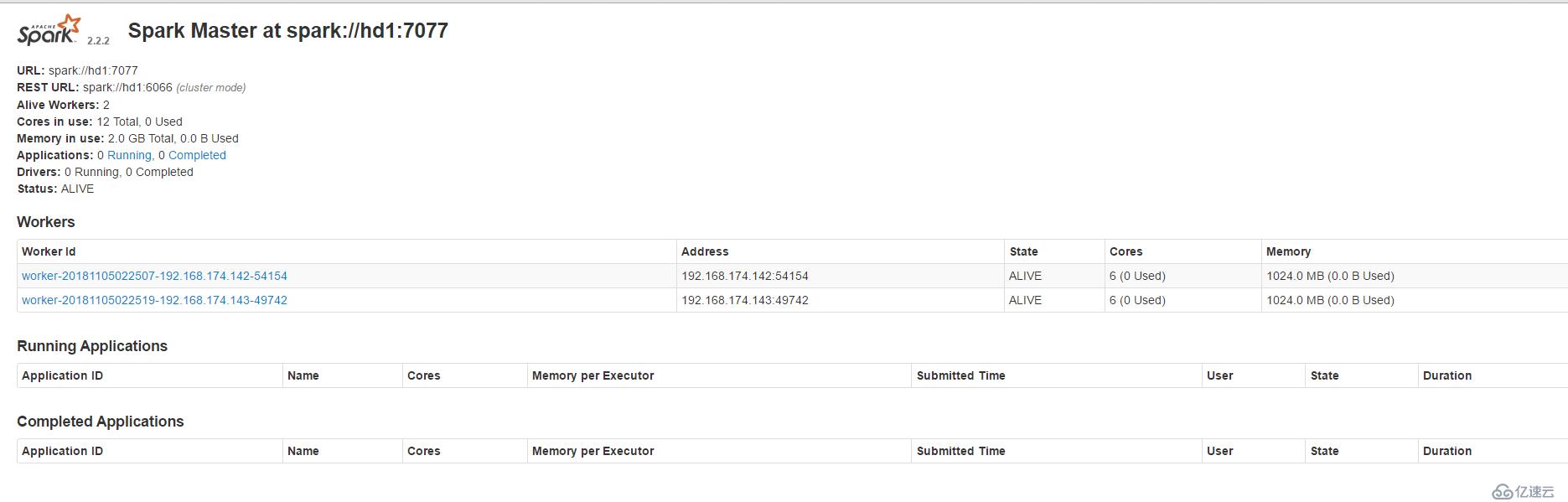
http://hd1:4040/jobs/ 或者 http://192.168.174.141:4040/jobs/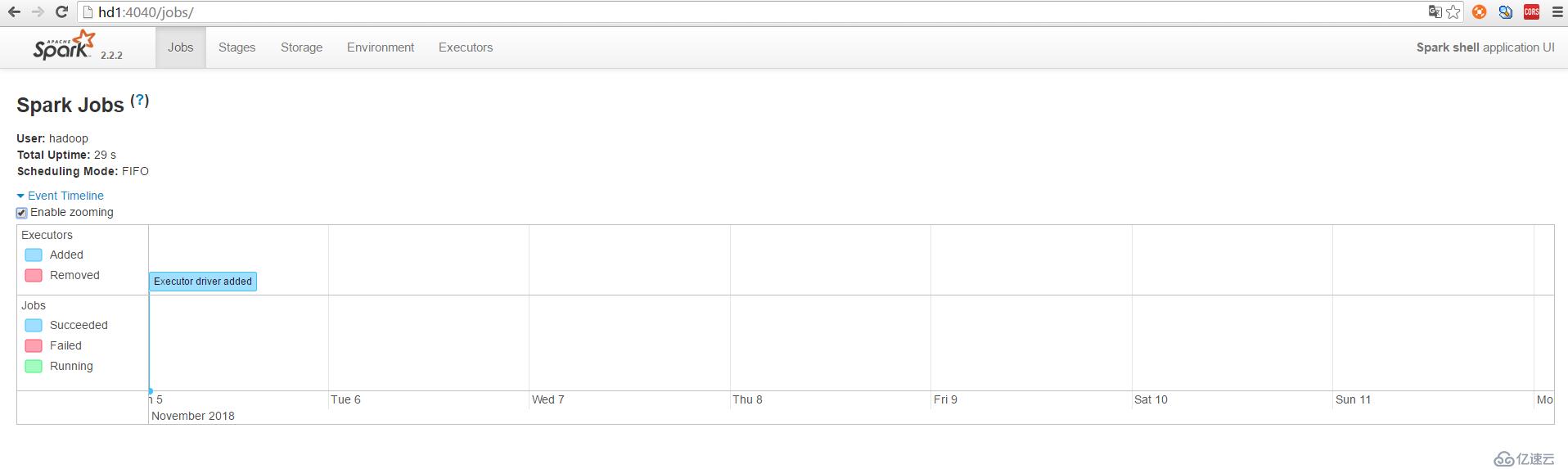
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





