这篇文章主要介绍了SQL中组内排序的示例分析,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
为什么说是简讲呢,其实分析函数在工作中用到的地方也是非常多的,但是它可以实现的方面有很多,这里给大家讲三方面:1.分组内排序、2.分组内求聚合、3.计算行与行数据之间的偏移量。(ps:当你学会分析函数,相信我,你会爱上它!)
江湖惯例,先拿excel开刀,有这样一个场景,我们学校有8个班级,名字就叫一、二、三...班,每个班里有n名学生,现在老师想要看到,每个学生在班里面的排名和在整个年级的排名,大致模型就是这样:
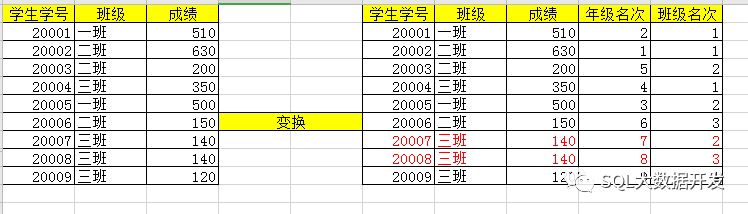
从左侧变成右边这样,这个变换过程excel应该可以实现,但是我不会~,会玩excel的同学可以在公众号给作者留言,我也学习学习~
说回正题,我们还是先在数据库中创建表用于存储这些数据:
CREATE TABLE student(xh INT(10),bj CHAR(10),cj INT(10));INSERT INTO student VALUES (20001 ,'一班', 510);INSERT INTO student VALUES (20002 ,'二班', 630);INSERT INTO student VALUES (20003 ,'二班', 200);INSERT INTO student VALUES (20004 ,'三班', 350);INSERT INTO student VALUES (20005 ,'一班', 500);INSERT INTO student VALUES (20006 ,'二班', 150);INSERT INTO student VALUES (20007 ,'三班', 140);INSERT INTO student VALUES (20008 ,'三班', 140);INSERT INTO student VALUES (20009 ,'三班', 120);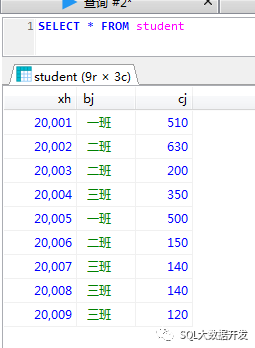
然后我们运行下面查询:
select xh,bj,cj, row_number()over(order by cj desc,xh asc) as njpm, row_number()over(partition by bj order by cj desc,xh asc) as bjpm from student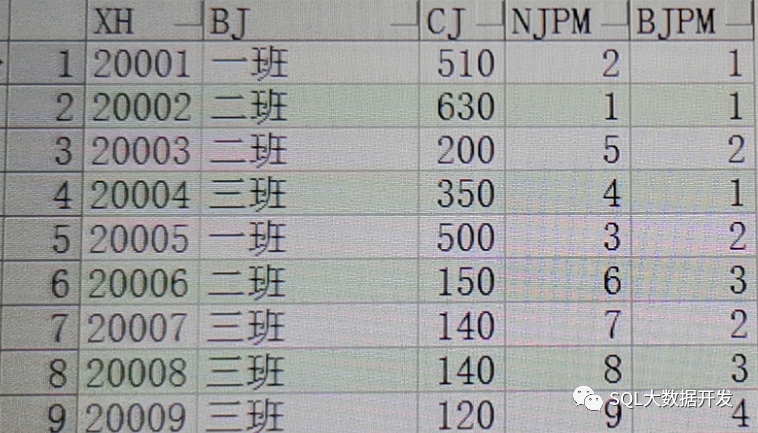
可以看到,数据已经按照我们的规则,进行排序,在这里我们看到,其中 20008 和20007 学号的学生成绩相同,在这里做了个当成绩相同时,按照学号从大到小进行排序。
接下来我们来分析一下这个函数
row_number()over(partition by 分组列, order by 排序列)前面的row_number()over是不变的,后面括号中的内容是关键,在这里我们需要对每个班级的学生成绩都进行排序,所以需要把每个班都分成一组一组,也就是partition by 后面跟上班级列,如果是按照年级分组,我们这里全表就一个年级的数据,所以不写分组,就是把全部数据当做一组。然后后面跟上我们的学生成绩,desc就是说是按照从大到小 也就是从高到低 进行排序,可以有多个排序字段,比如当成绩相同的时候,后面可以跟上按照学号从小到大进行排序,也就是asc 。分组和排序都一样,可以有0个或者多个字段。
但是有的老师可能想看到更加公平的结果,就是成绩相同的学生名次也相同,但是会产生一个新的问题,就是再往下的 20009号学生 排名多少,是按照上两名都是第二名 ,然后它是第三名,还是说这直接跨越第三名,把它排到第四名,这里就引出来row_number()的两个兄弟函数:dense_rank()和rank():
rank()over(partition by 分组列, order by 排序列)---rank()可以对相同名次的学生进行跨越式的排序,比如 1 2 2 4 dense_rank()over(partition by 分组列, order by 排序列)---dense_rank()的功能和rank()相似,但是会形成连续的排名, 比如 1 2 2 3感谢你能够认真阅读完这篇文章,希望小编分享的“SQL中组内排序的示例分析”这篇文章对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,更多相关知识等着你来学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4601010/blog/4459213



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



