这篇文章主要讲解了“R语言层次聚类与聚类树怎么使用”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“R语言层次聚类与聚类树怎么使用”吧!
在生态学研究当中,有些环境中的对象是连续(或者离散)的,而有些对象是不连续的,聚类的目的是识别在环境中不连续的对象子集,从而探索隐藏在数据背后的属性特征。聚类分析主要处理那些对象有足够的相似性被归于一组,并且确定组与组之间的差异或分离程度。聚类可以分为特征聚类(Vector Clustering)和图聚类(Graph Clustering)。特征聚类是指根据对象的特征向量矩阵来计算距离或者相关性来实现聚类,例如各种层次聚类和非层次聚类。而图聚类则针对的是复杂网络数据,有随机游走、贪心策略、标签传播等算法等。
根据对象归属方法,有以下两种:
⑴硬划分,也即将总体划分为不同的部分,每个对象或者变量只能归属于某一组(身份信息为0或1)。
⑵模糊划分,对象归属身份信息可以是连续的,也即身份信息可以是0到1中间的任意值。
聚类的结果可以输出为无层级分组,也可以是具有嵌套结构的层次聚类树。非约束的聚类分析只是一种数据划分,不是典型的统计方法,因此不必进行统计检验,但是约束的聚类分析(多元回归树)需要进行统计检验。
⑴单连接聚合聚类
单连接聚合聚类(singlelinkage agglomerative clustering)也称作最近邻分类(nearestneighbour sorting),依据最短的成对距离或最大相似性来依次连接对象直到连接完毕,两个组之间最近的两个对象之间距离即为组的距离。此方法一般使用弦距离矩阵(欧氏距离)进行分析,在hclust()函数中为"single"。
⑵完全连接聚合聚类
完全连接聚合聚类(completelinkage agglomerative clustering)也称作最远邻分类(furthestneighbour sorting),依据最远距离决定一个对象或者一个组是否与另一个组聚合,所有对象之间的距离必须完全计算然后进行比较。単连接聚合聚类更容易体现数据的梯度,而完全连接聚合聚类分类组之间差异更加明显。在在hclust()函数中为"complete"。
⑶平均聚合聚类
平均聚合聚类(averageagglomerative clustering)是一类基于对象之间平均相异性或者聚类簇形心(centroid)的进行聚类的方法。一个对象加入一个组依据的是这个对象与这个组成员的平均距离。在hclust()函数中有等权重算术平均聚类"average"(UPGMA)、不等权重算术平均聚类"mcquitty"(WPGMA)、等权重形心聚类"centroid"(UPGMC)、不等权重形心聚类"median"(WPGMC)四种方法。在生态学中Bray-Curtis距离矩阵一般使用方法"average"进行分析,其聚类树结构介于单连接和完全连接聚类之间。
⑷最小方差聚类
Ward最小方差聚类是一种基于最小二乘法线性模型准则的聚类方法。分组的依据是使组内距离平方和(方差)最小化,由于使用了距离的平方,常常使聚类树基部过于膨胀,可取平方根再进行可视化。在hclust()函数中有"ward.D"、"ward.D2"两种方法。
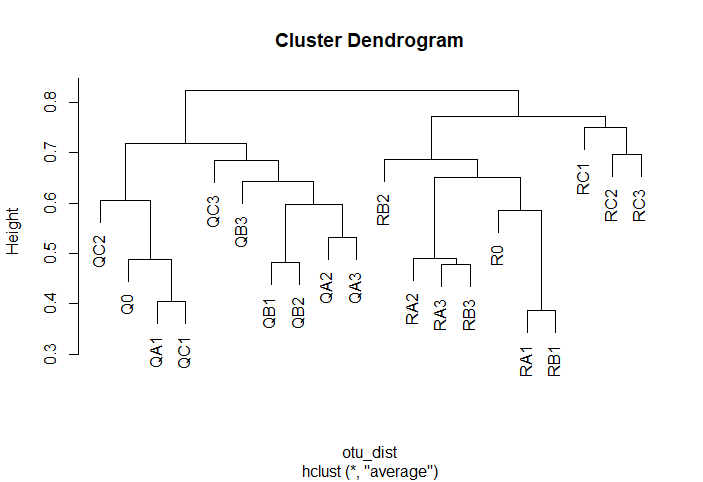
#读取群落数据并计算Bray-Curtis距离矩阵data=read.table(file="sample.subsample.otu_table.txt", header=T, check.names=FALSE)rownames(data)=data[,1]data=data[,-1]library(vegan)data=decostand(data, MARGIN=2, "total")otu=t(data)otu_dist=vegdist(otu, method="bray", diag=TRUE, upper=TRUE, p=2)#进行聚类分析并作图hclust=hclust(otu_dist, method="average")plot(hclust)聚类树如下图所示:
library(dendextend)library(circlize)tree=as.dendrogram(hclust)par(mfrow=c(2,2), mar=c(3,3,1,5), cex=0.7)plot(tree, horiz=TRUE, main="UPGMA Tree")#隐藏平均距离小于0.5的对象(类群)plot(cut(tree, h=0.5)$upper, horiz=TRUE, main="Samples with distance higher than 0.5")#在上一步基础上筛选第二个分类簇plot(cut(tree, h=0.5)$upper[[2]], horiz=TRUE, main="Second branch samples with distance higher than 0.5")circlize_dendrogram(tree)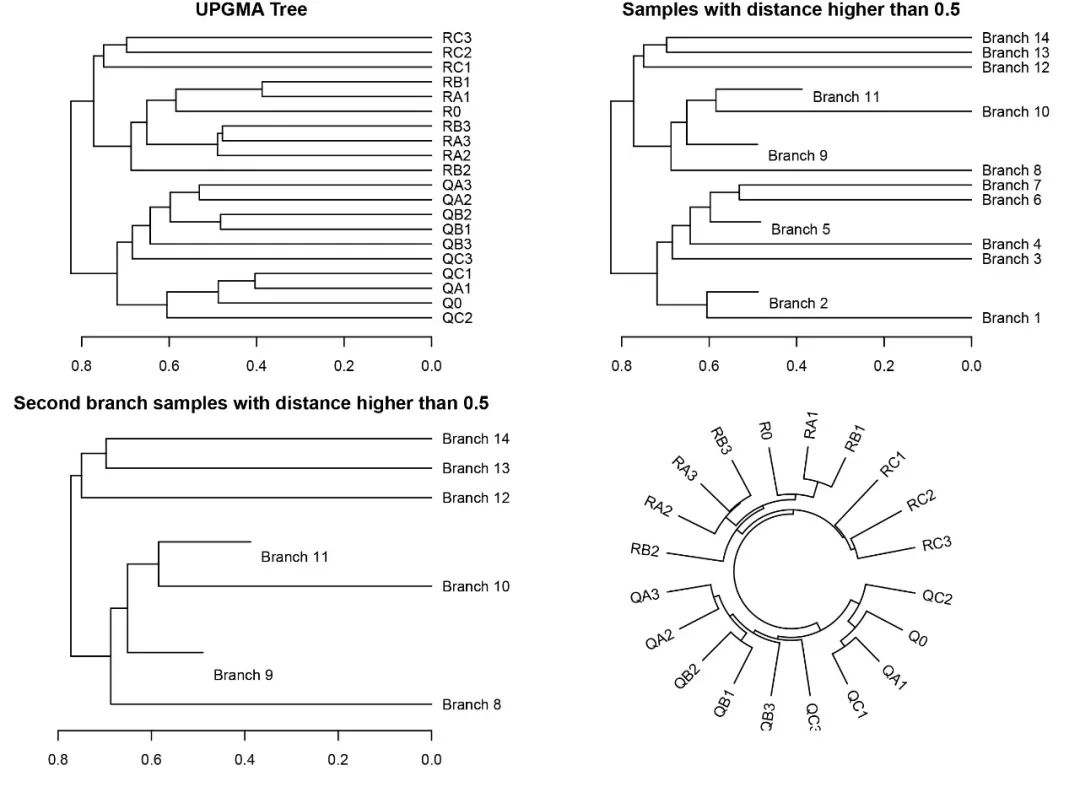
par(mfrow=c(1,1), mar=c(3,3,3,5), cex=1)#读取群落数据并计算Bray-Curtis距离矩阵data=read.table(file="sample.subsample.otu_table.txt", header=T, check.names=FALSE)rownames(data)=data[,1]data=data[,-1]library(vegan)data=decostand(data, MARGIN=2, "total")otu=t(data)otu_dist=vegdist(otu, method="bray", diag=TRUE, upper=TRUE, p=2)#进行聚类分析并作图hclust=hclust(otu_dist, method="average")library(dendextend)library(RColorBrewer)hcd=as.dendrogram(hclust)labelColors=brewer.pal(n=4, name="Set1")#聚类分组,预设聚类簇数目为4clusMember=cutree(hcd, 4)#自定义函数,根据聚类结果进行着色colLab=function(n) { if (is.leaf(n)) { a=attributes(n) labCol=labelColors[clusMember[which(names(clusMember)==a$label)]] attr(n, "nodePar")=c(a$nodePar, lab.col=labCol) } n}clusDendro=dendrapply(hcd, colLab)plot(clusDendro, main ="UPGMA Tree", type="rectangle", horiz=TRUE)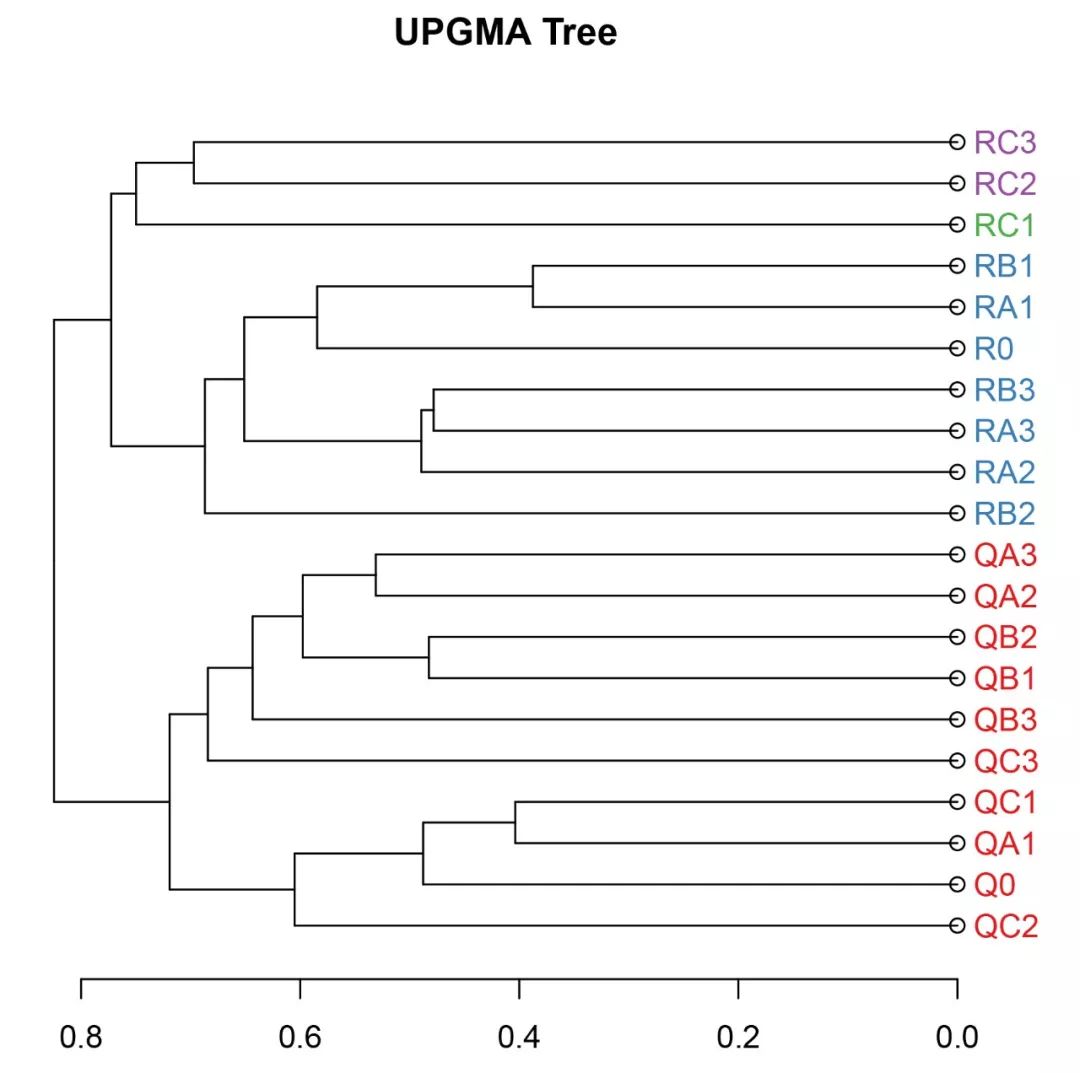
软件包dendextend是一个很好的聚类树可视化工具,可以使用“%>%”来对tree文件进行更新美化,如下所示:
hcd=hcd %>% set("labels_cex", 1.5) %>% set("branches_lwd", 2) %>% set("branches_k_color", k=4) %>% set("branches_k_lty", k=4) clusDendro=dendrapply(hcd, colLab)plot(clusDendro, main="UPGMA Tree", type="rectangle", horiz=TRUE)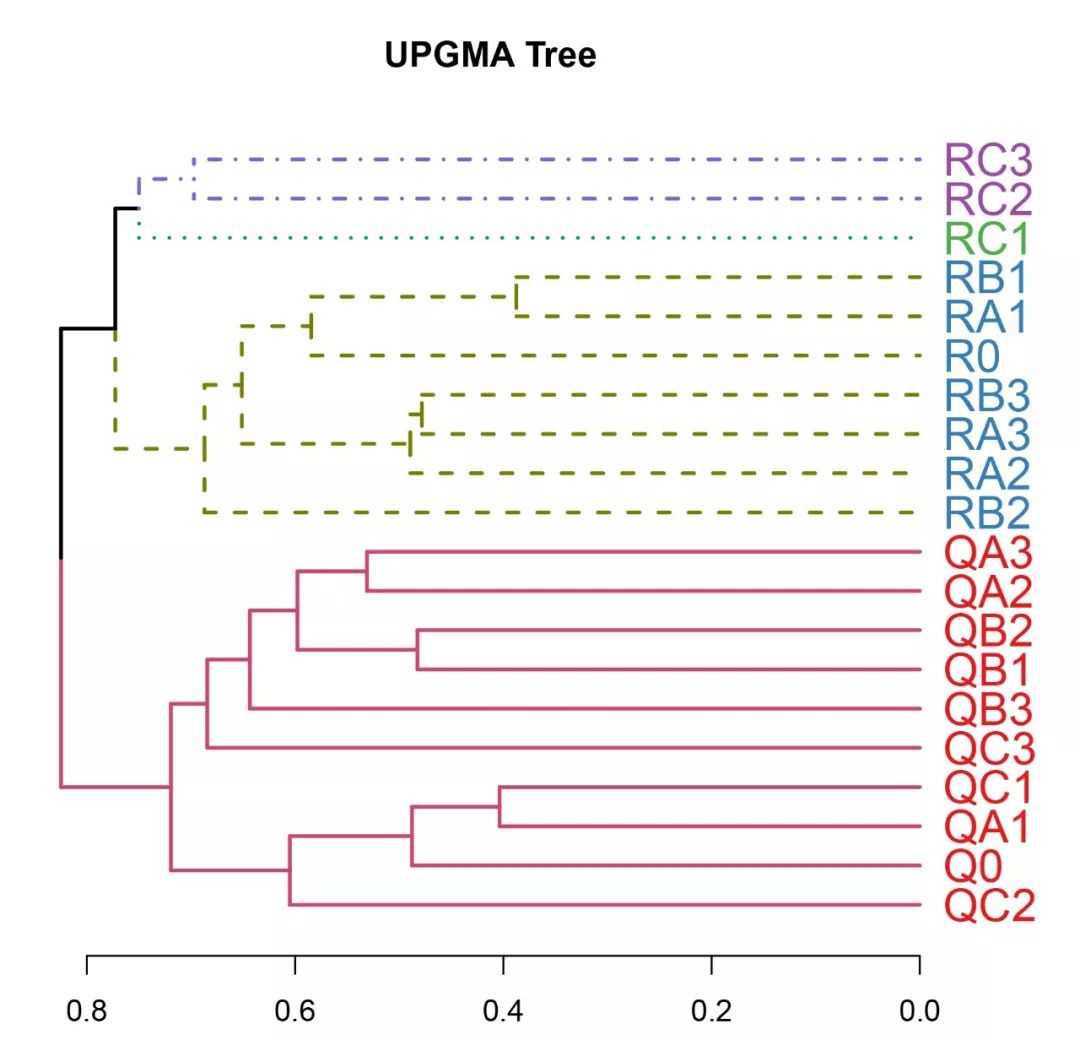
感谢各位的阅读,以上就是“R语言层次聚类与聚类树怎么使用”的内容了,经过本文的学习后,相信大家对R语言层次聚类与聚类树怎么使用这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4599872/blog/4472876



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



