这篇文章主要介绍“perl怎么分析相关性网络节点度”的相关知识,小编通过实际案例向大家展示操作过程,操作方法简单快捷,实用性强,希望这篇“perl怎么分析相关性网络节点度”文章能帮助大家解决问题。
#计算节点度diag(rcorr)=0degree=numeric(ncol(rcorr))for (i in 1:ncol(rcorr)) { degree[i]=length(which(rcorr[i,]!=0))}#计算度中心性centdeg=degree/(ncol(rcorr)-1)nodedata=data.frame(degree, centdeg, row.names=rownames(rcorr))nodedata=nodedata[order(nodedata[,2],decreasing=TRUE),]#节点度分布图library(ggplot2)ggplot(nodedata, aes(x=degree)) + geom_histogram(position='identity', alpha=0.5, fill="cyan", binwidth=1, aes(y=..density..)) + stat_density(geom='line', position='identity', col="cyan4") + xlab("Node Degree") + ylab("Density")此外,可以直接使用函数计算节点度等指标:
degree(g)#计算节点度
closeness(g)#计算接近度中心性
betweenness(g)#中介系数中心性
evcent(g)#计算特征向量中心性
节点度分布图是不同节点度范围内的节点数目统计情况,可以反映网络的异质性,也即节点之间的连接状况是否均匀,理论上高关联度节点越多网络结构越复杂,做图结果如下所示:
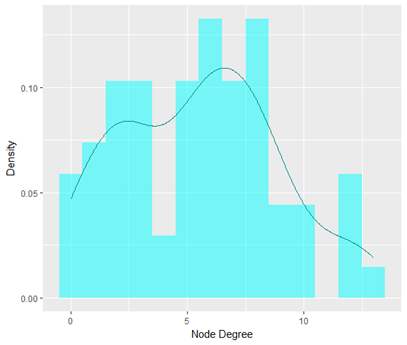
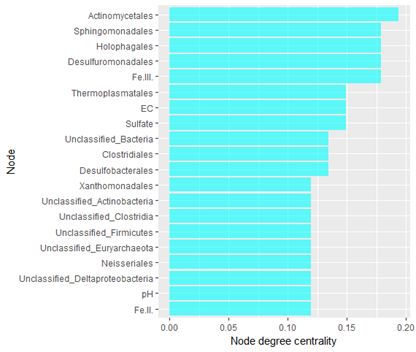
接下来我们可以筛选出度中心性高的节点,来看那些物种或者环境因子在相关性网络中的影响较大:
#节点度中心性条形图nodedata=nodedata[1:20, ]ggplot(nodedata, aes(x=factor(rownames(nodedata), levels=rev(rownames(nodedata))), y=centdeg)) + geom_bar(stat="identity", fill="cyan", alpha=0.6) + xlab("Node") + ylab("Node degree centrality") + coord_flip()做图结果如下所示:
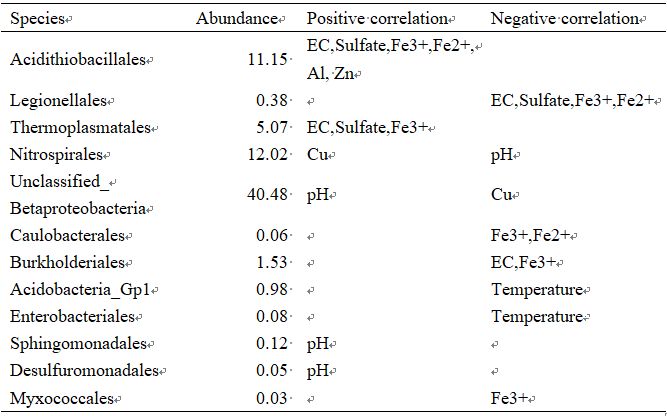
接下来,我们可以筛选受环境因子直接影响(相关系数之和不为0)的物种,并提取其相对丰度信息以便进行比较分析:
#提取筛选环境因子与物种相关性envcor=rcorr[1:m, (m+1):(m+n)]sumcor=numeric(m)for (i in 1:m) { sumcor[i]=sum(abs(envcor[i,]))}ecocor=data.frame(cbind(envcor, sumcor))ecocor=ecocor[order(abs(ecocor$sumcor), decreasing=TRUE),]abund=numeric(m)for (i in 1:m) { abund[i]=100*mean(com[, i])}names(abund)=colnames(com)abundance=abund[rownames(ecocor)]cordata=data.frame(ecocor, abundance)cordata=cordata[cordata$sumcor!=0,]write.csv(cordata, file="cordata.csv", row.names=TRUE, quote=FALSE)经整理结果如下所示:
关于“perl怎么分析相关性网络节点度”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识,可以关注亿速云行业资讯频道,小编每天都会为大家更新不同的知识点。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4599872/blog/4472981



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



