通过集算器编写更为简单高效的算法加速计算进程,提升查询性能
采用集算器可控存储和索引机制,为 BI(CUBE)提供高速的数据存储
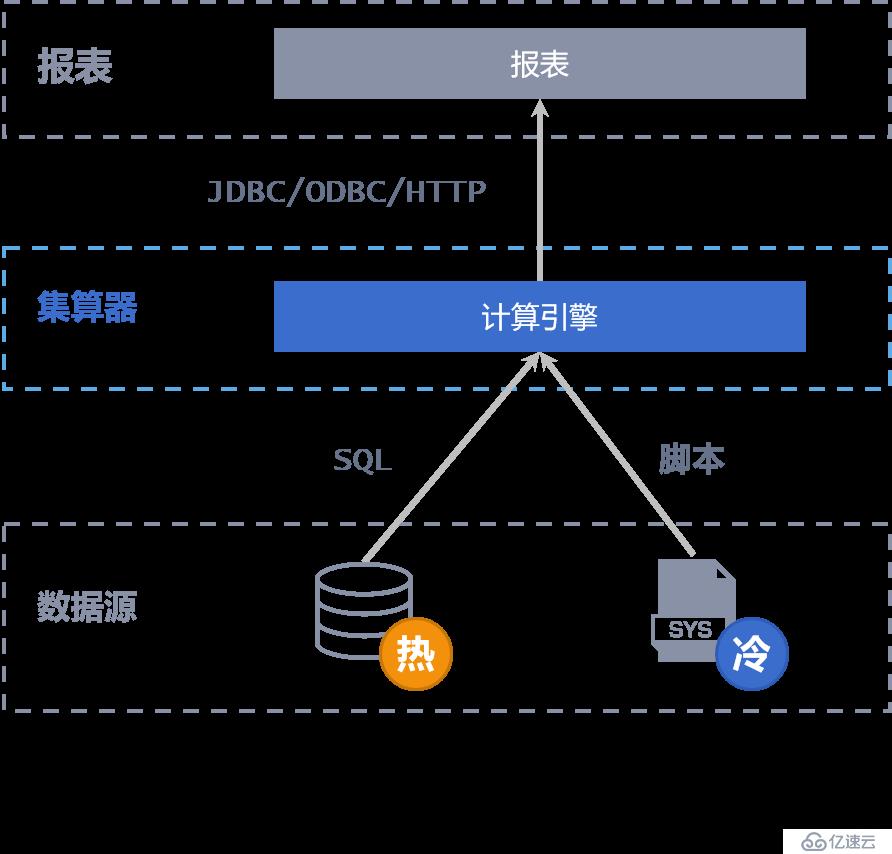
将冷热数据分离,仅将当期热数据存放在数据库中,冷数据存储在文件系统或数据库中,通过集算器完成跨源(库)计算,完成多源数据汇总、复杂计算,实现 T+0 全量数据实时查询
集算器提供不同数据库的基本 SQL 翻译功能,数据分库(同构异构均可)后,仍然可以使用通用 SQL 进行跨库查询
集算器重新定义关联运算,可以根据计算特征选用不同且高效的关联算法提升多表关联性能
一对多的主外键表可采用指针式连接提高性能
一对一的同维表和多对一的主子表可采用有序归并提升性能
集算器采用过程计算,分步实施计算简化实现代码,无需嵌套
过程中可以复用中间结果,性能更高
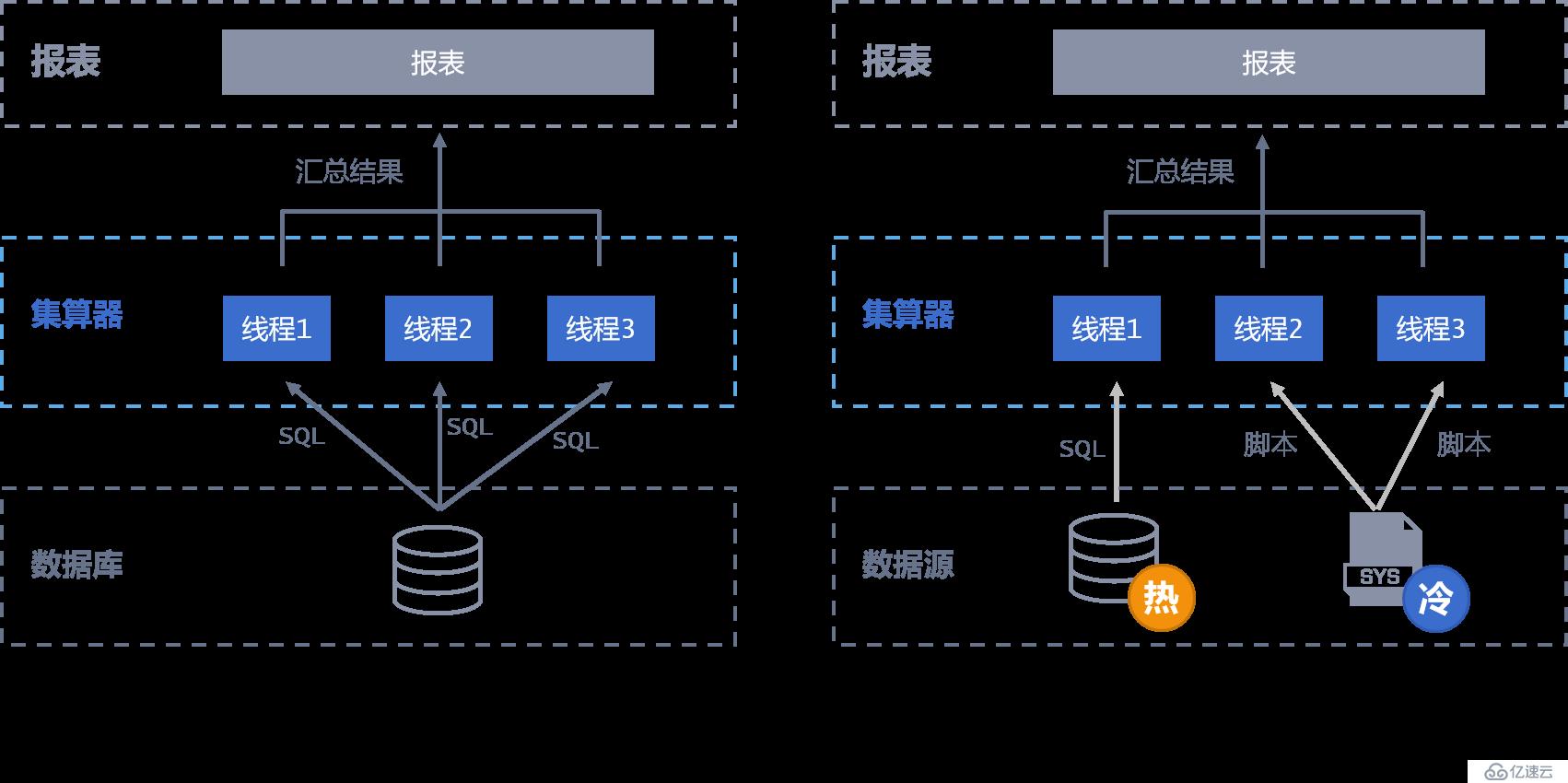
集算器通过(多线程)并行计算与数据库建立多个连接并行取数提升取数性能
可将量大的冷数据事先存储在库外文件系统中,集算器基于文件直接查询计算,避免通过 JDBC 取数
集算器将计算和呈现做成两个异步线程,取数线程发出 SQL 将数据缓存到本地交给呈现线程快速展现报表,此外取数线程只涉及一个事务不会出现数据不一致,保证数据准确性
集算器帮助报表开发彻底工具化,不仅报表呈现层工具化,报表数据计算层也工具化,从而降低报表开发难度,报表实现更快更简单
对人员要求更低,无需专业程序员
报表业务不稳定导致报表没完没了不可能消灭,集算器提供了最低成本的应对
集算器作为完备计算引擎,支持过程计算开发快捷
算法实现简单,适合一般技术人员使用
提供可视化编程环境,即装即用使用简单
通过多源支持,基于 Excel/TxT/DB 直接计算无需入库
集算器通过过程计算,分步编程简化算法开发难度,算法短小、分步同时降低了维护难度,极大改善上千行 SQL 编写调试和维护困难的情况
集算器作为库外通用计算引擎,可以编写不依赖数据库的通用算法,数据库发生变化时无需更改核心算法,易于移植
集算器提供了完备的结构化数据计算能力,解决了 JAVA 集合运算困难的问题,无需再用 JAVA 编写
集算器还很方便集成到现有应用中,与应用完美结合
集算器可作为报表独立的计算层,数据准备算法和报表模板一起存储,共同管理,可与应用分开部署,降低应用的耦合度
解释执行的集算器脚本可实现热切换
集算器作为完备计算引擎,提供了丰富的结构化数据运算函数,改善 MySQL 无法使用窗口函数导致的编码困难
集算器作为完备结构化数据计算引擎,可以充当通用库外存储过程,提供不依赖于数据库的强计算能力和易移植特性
集算器提供直接针对文件使用 SQL 查询的功能
还可以编写脚本读取 NoSQL、文本、Excel 数据,实施计算,实现复杂度与 SQL 相当或更低
集算器提供了对 JSON/XML 这类分层数据的支持,基于这类数据计算不仅编码简单,而且性能高实时性好
集算器具备强计算能力,非常擅长复杂计算,可以辅助或替代现有 ETL 工具实现复杂业务逻辑,实现复杂度远远低于硬编码 ETL 计算脚本
集算器支持过程计算,提供可视化编程环境,每步的计算结果所见即所得,还提供设置断点、单步执行、执行到光标等编辑调试功能,开发效率极高
相对存储过程需要反复读写磁盘使用中间结果,集算器提供丰富的运算,大量减少中间结果落地,性能更高
集算器采用过程计算,提供丰富函数类库,实现算法短小精悍易于维护
集算器脚本可以脱离数据库编写和运行,减少数据库安全隐患
集算器提供通过 SQL 针对文件的查询功能
还可以针对 NoSQL、文本和 Excel 直接进行多源混合计算,编码效率远高于硬编码
集算器作为完备计算引擎可以实现真正的 ETL,基于多源混合计算能力先将多源数据进行清洗(E)传输(T),将整理好数据加载(L)到目标数据库,避免汇总到单库带来的时间、空间和管理上的过多开销
集算器采用过程计算,分步编写代码,提供丰富的类库和方法,开发简单易维护,大大降低编码难度,提升实施效率
集算器可基于生产库和分析库进行混合计算,量小的实时热数据从生产库查,将对生产系统的影响降到最低,量大的历史冷数据从分析库查,两部分数据混合计算实现全量数据实时计算
集算器允许将量大且不再变化的历史数据从数据库导出到文件系统存储,借助集算器完备的数据计算能力,直接基于文件系统计算,同时支持与数据库混合计算,从而降低数据库扩容压力,实施成本低
集算器易于应用集成,可将数据仓库中的部分计算和数据移植到应用层借助集算器计算能力实施数据存储和计算,分担数据仓库压力
集算器支持将数据库的中间表移植到 I/O 性能更高的文件系统,降低数据库冗余,集算器直接基于文件计算,性能更高,还方便实施并行计算,进一步提升效率
中间表在库外采用文件系统的树状结构进行分类管理,优于数据库的线性结构,管理方便
集算器的强计算能力 + 数据缓存 + 数据网关 + 多源混算可以替代单独数据集市或前置数据库,成本低廉
集算器作为轻量级大数据解决非常适合几个到几十个节点的集群规模,相对 hadoop 集算器资源利用率更高,节约资源,同样的计算指标需要硬件更少,同样的硬件计算效率更高
集算器可将 hadoop 作为数据源,实现 hadoop 难以完成的计算
同时支持实时查询,避免部署 RDB 带来的 ETL 时间成本高,数据实时性差,商用 RDB 价格成本高等问题
集算器计算引擎具备复杂计算实现简单、效率高的特点,适合使用 hadoop 或 spark 却还经常需要编写 UDF 的场景,极大提升开发效率
集算器提供灵活的数据分布和计算分布,可以根据数据特征、计算特征和硬件特征实施个性化大数据计算从而获得最高性能,解决了 hadoop/spark 过于透明导致无法实施高性能计算的难题
集算器提供内存和外存两种计算方式,由于采用高效计算模型,内存计算时效率更高、内存利用率更低,从而降低成本
当内存容量不够或无需全内存计算时,集算器采用外存计算从而减轻对内存容量的依赖,硬件成本更低
集算器借助高性能计算和高性能数据存储特征,优化所以体系,很好解决了 Hbase 等 KV 数据库批量查询效率低下的难题
集算器专为结构化数据计算设计,支持过程化计算,提供了丰富的结构化数据集算函数,提供即装即用的可视化编辑调试环境,非常适合进行桌面数据分析,随装随用,随用随走
集算器具备完备的数据计算能力,作为商业软件,提供了丰富的接口处理 Excel/JSON 等非库数据,即装即用,避免了 Python 等开源技术版本混乱、使用困难
集算器提供了多线程并行计算和分布式计算能力,通过简单的脚本即可实现并行计算,可充分利用多 CPU 核能力实施高性能计算
集算器可作为计算中间件无缝嵌入应用系统,桌面数据分析编写的脚本可直接移植到生产系统中,无需重写
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



