иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іеёёи§Ғж•°жҚ®з»“жһ„е’Ңз®—жі•зҡ„еә”з”Ёзі»еҲ—зӨәдҫӢеҲҶжһҗпјҢж–Үз« еҶ…е®№иҙЁйҮҸиҫғй«ҳпјҢеӣ жӯӨе°Ҹзј–еҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҜ№зӣёе…ізҹҘиҜҶжңүдёҖе®ҡзҡ„дәҶи§ЈгҖӮ
ж•°жҚ®з»“жһ„жҳҜжҢҮпјҡдёҖз§Қж•°жҚ®з»„з»ҮгҖҒз®ЎзҗҶе’ҢеӯҳеӮЁзҡ„ж јејҸпјҢе®ғеҸҜд»Ҙеё®еҠ©жҲ‘们е®һзҺ°еҜ№ж•°жҚ®й«ҳж•Ҳзҡ„и®ҝй—®е’Ңдҝ®ж”№гҖӮ
ж•°жҚ®з»“жһ„ = ж•°жҚ®е…ғзҙ + е…ғзҙ д№Ӣй—ҙзҡ„з»“жһ„гҖӮ
еҰӮжһңиҜҙж•°жҚ®з»“жһ„жҳҜйҖ еӨ§жҘјзҡ„йӘЁжһ¶пјҢз®—жі•е°ұжҳҜе…·дҪ“зҡ„йҖ жҘјжөҒзЁӢгҖӮжөҒзЁӢдёҚеҗҢпјҢж•ҲзҺҮиө„жәҗдёҚеҗҢгҖӮжҲ‘дјҡдёӨиҖ…з»“еҗҲз®ҖеҚ•жҺўи®ЁдёӢ他们зҡ„зү№зӮ№е’Ңеә”з”ЁгҖӮ
еёёи§Ғзҡ„ж•°жҚ®з»“жһ„еҸҜеҲҶдёәпјҡзәҝжҖ§з»“жһ„гҖҒж ‘еҪўз»“жһ„ е’Ң еӣҫзҠ¶з»“жһ„ гҖӮ
еёёи§Ғзҡ„з®—жі•жңүпјҡйҖ’еҪ’гҖҒжҺ’еәҸгҖҒдәҢеҲҶжҹҘжүҫгҖҒжҗңзҙўгҖҒе“ҲеёҢз®—жі•гҖҒиҙӘеҝғз®—жі•гҖҒеҲҶжІ»з®—жі•гҖҒеӣһжәҜз®—жі•гҖҒеҠЁжҖҒ规еҲ’гҖҒеӯ—з¬ҰдёІеҢ№й…Қз®—жі• зӯүгҖӮ
дёӢйқўд»Һ зәҝжҖ§ж•°жҚ®з»“жһ„гҖҒйҖ’еҪ’ е’Ң жҺ’еәҸз®—жі• и°Ҳиө·гҖӮ
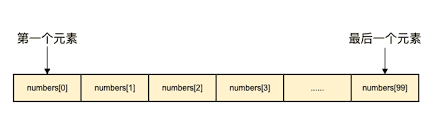
зәҝжҖ§з»“жһ„ зәҝжҖ§з»“жһ„пјҡжҳҜжҢҮж•°жҚ®жҺ’жҲҗеғҸдёҖжқЎзәҝдёҖж ·зҡ„з»“жһ„гҖӮжҜҸдёӘе…ғзҙ з»“зӮ№жңҖеӨҡеҜ№еә”дёҖдёӘеүҚй©ұз»“зӮ№е’ҢдёҖдёӘеҗҺ继结зӮ№гҖӮеҰӮж•°з»„, й“ҫиЎЁпјҢж Ҳ пјҢйҳҹеҲ—зӯүгҖӮ
ж•°з»„ ж•°з»„жҳҜжҳҜз”ұзӣёеҗҢзұ»еһӢзҡ„е…ғзҙ пјҲelementпјүзҡ„йӣҶеҗҲжүҖз»„жҲҗзҡ„ж•°жҚ®з»“жһ„пјҢеҲҶй…ҚдёҖеқ—иҝһз»ӯзҡ„еҶ…еӯҳжқҘеӯҳеӮЁгҖӮеҲ©з”Ёе…ғзҙ зҡ„дёӢж ҮдҪҚзҪ® еҸҜд»Ҙи®Ўз®—еҮәиҜҘе…ғзҙ еҜ№еә”зҡ„еӯҳеӮЁең°еқҖгҖӮ
еӣҫзүҮжқҘжәҗиҮӘзҪ‘з»ңпјҢдҫөеҲ
дјҳзӮ№ пјҡзҙўеј• з»“жһ„пјҢжҹҘиҜўдҝ®ж”№е…ғзҙ зҡ„ж•ҲзҺҮO(1)гҖӮеҗҢж—¶еҸҜд»ҘеҖҹеҠ© CPU зҡ„зј“еӯҳжңәеҲ¶пјҢйў„иҜ»ж•°з»„дёӯзҡ„ж•°жҚ®пјҢжүҖд»Ҙи®ҝй—®ж•ҲзҺҮжӣҙй«ҳгҖӮ
зјәзӮ№ пјҡ
еҸҜйҖҡиҝҮд»ҘдёӢж–№ејҸйҒҝе…Қе…ғзҙ жӢ·иҙқе’ҢеҚ з”ЁеӨ§зҡ„ејҖй”Җпјҡ
1.жҮ’еҲ йҷӨпјҡеҲ йҷӨж—¶еҸӘж Үи®°е…ғзҙ иў«еҲ йҷӨпјҢ并дёҚзңҹжӯЈзҡ„жү§иЎҢеҲ йҷӨгҖӮеҪ“ж•°з»„ж•ҙдҪ“еҶ…еӯҳдёҚеӨҹз”Ёж—¶пјҢеҶҚжү§иЎҢзңҹжӯЈзҡ„еҲ йҷӨгҖӮMysql зҡ„InnoDBеј•ж“ҺдёӯжҜҸдёӘBuffer Poolе®һдҫӢз”ұиӢҘе№ІдёӘchunkз»„жҲҗпјҢе®һйҷ…еҶ…еӯҳз”іиҜ·ж“ҚдҪңд»ҘchunkдёәеҚ•дҪҚгҖӮ
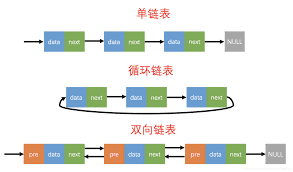
й“ҫиЎЁ й“ҫиЎЁзҡ„еӯҳеңЁе°ұжҳҜдёәдәҶи§ЈеҶіж•°з»„зҡ„еўһеҲ еӨҚжқӮиҖ—ж—¶пјҢеҶ…еӯҳеҚ з”ЁиҫғеӨ§зҡ„й—®йўҳгҖӮе®ғ并дёҚйңҖиҰҒдёҖеқ—иҝһз»ӯзҡ„еҶ…еӯҳз©әй—ҙпјҢе®ғйҖҡиҝҮ жҢҮй’Ҳ е°ҶдёҖз»„йӣ¶ж•Јзҡ„еҶ…еӯҳеқ—дёІиҒ”иө·жқҘгҖӮж №жҚ®жҢҮй’Ҳзҡ„дёҚеҗҢпјҢжңүеҚ•й“ҫиЎЁпјҢеҸҢеҗ‘й“ҫиЎЁпјҢеҫӘзҺҜй“ҫиЎЁд№ӢеҲҶгҖӮ
еӣҫзүҮжқҘжәҗиҮӘзҪ‘з»ңпјҢдҫөеҲ
дјҳзӮ№ пјҡ
зјәзӮ№ пјҡ
еҸҜд»ҘзңӢеҮәпјҡж•°з»„е’Ңй“ҫиЎЁжҳҜзӣёдә’иЎҘе……зҡ„дёҖеҜ№ж•°жҚ®з»“жһ„гҖӮйӮЈжҖҺд№ҲејҘиЎҘй“ҫиЎЁзҡ„дёҚи¶іе‘ўпјҹ
еҶ…еӯҳиҝҷеқ—жҳҜдёҚеҘҪи§ЈеҶіпјҢиҝҷжҳҜз”ұ жҢҮй’Ҳ еҶіе®ҡзҡ„гҖӮ
е…ідәҺзҙўеј•пјҢжІЎзҙўеј•е°ұеё®е®ғе»әзҙўеј•еҘҪдәҶпјҡ
1.з»“еҗҲhashиЎЁпјҢи®°еҪ•й“ҫиЎЁжҜҸдёӘз»“зӮ№зҡ„дҪҚзҪ®гҖӮ
еә”з”ЁеңәжҷҜпјҡ
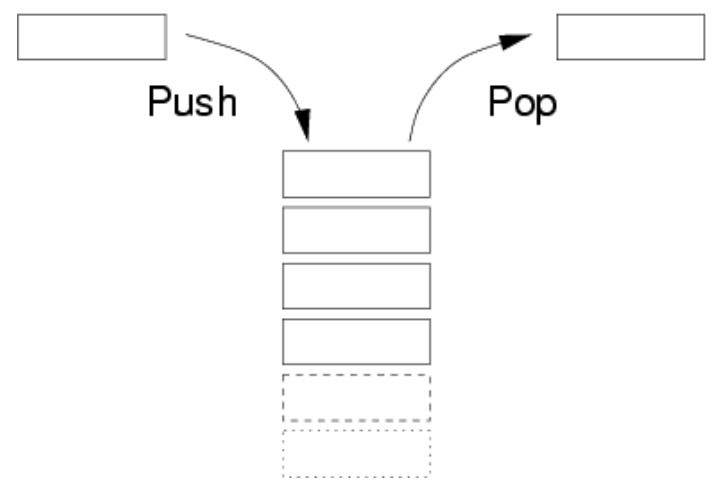
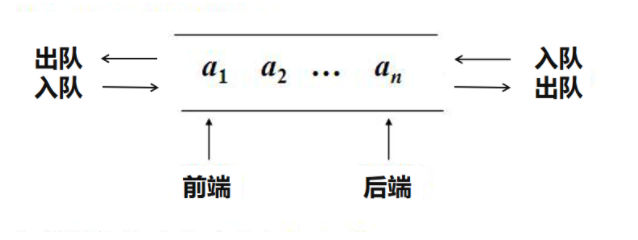
ж Ҳ ж ҲжҳҜдёҖз§ҚеҸ—йҷҗеҲ¶зҡ„зәҝжҖ§ж•°жҚ®з»“жһ„гҖӮе…ғзҙ еҸӘеҸҜд»ҘеңЁж ҲйЎ¶иў«и®ҝй—®гҖӮз¬ҰеҗҲе…ҲиҝӣеҗҺеҮәзҡ„First-In-Last-Outзҡ„и®ҝй—®ж–№ејҸгҖӮ
еӣҫзүҮжқҘжәҗиҮӘзҪ‘з»ңпјҢдҫөеҲ
з”Ёж•°з»„е®һзҺ°зҡ„еҸ«йЎәеәҸж ҲпјҢз”Ёй“ҫиЎЁе®һзҺ°зҡ„еҸ«й“ҫејҸж ҲгҖӮ
еҸҜиғҪжңүдәәдјҡжңүз–‘й—®пјҡжҲ‘з”Ёж•°з»„й“ҫиЎЁеңЁеӨҙе°ҫдёӨз«ҜеҸҜдјёеҸҜзј©пјҢдёәжҜӣиҰҒз”ЁеҸӘиғҪеңЁеӨҙйғЁж“ҚдҪңзҡ„ж Ҳз»“жһ„е‘ўпјҹ
еә”з”ЁеңәжҷҜпјҡ
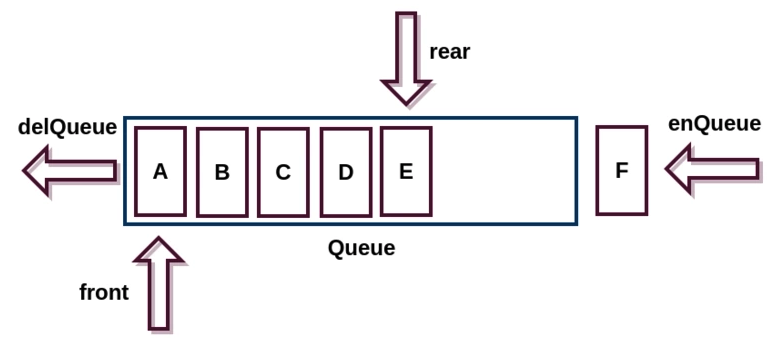
йҳҹеҲ— йҳҹеҲ—д№ҹжҳҜдёҖз§ҚеҸ—йҷҗеҲ¶зҡ„зәҝжҖ§ж•°жҚ®з»“жһ„гҖӮз¬ҰеҗҲе…Ҳиҝӣе…ҲеҮәзҡ„First-In-First-Out зҡ„и®ҝй—®ж–№ејҸгҖӮеҗҢж ·пјҢз”Ёж•°з»„е®һзҺ°зҡ„йҳҹеҲ—еҸ«дҪңйЎәеәҸйҳҹеҲ—пјҢз”Ёй“ҫиЎЁе®һзҺ°зҡ„йҳҹеҲ—еҸ«дҪңй“ҫејҸйҳҹеҲ—гҖӮ
еӣҫзүҮжқҘжәҗиҮӘзҪ‘з»ңпјҢдҫөеҲ
ж №жҚ®еӨҙе°ҫжҢҮй’Ҳе’Ңж“ҚдҪңзҡ„дёҚеҗҢпјҢйҳҹеҲ—еҸҲеҸҜеҲҶдёәеҸҢз«ҜйҳҹеҲ—пјҢеҫӘзҺҜйҳҹеҲ—пјҢйҳ»еЎһйҳҹеҲ—пјҢ并еҸ‘йҳҹеҲ—гҖӮ
еҸҢз«ҜйҳҹеҲ—пјҡеӨҙе°ҫеқҮеҸҜд»ҘиҝӣиЎҢжҸ’е…ҘпјҢеҲ йҷӨпјҢи®ҝй—®е…ғзҙ пјҢжӣҙдёәе®һз”ЁгҖӮдёҚеӯҳеңЁFIFOиҝҷз§ҚйҷҗеҲ¶гҖӮ
еӣҫзүҮжқҘжәҗиҮӘзҪ‘з»ңпјҢдҫөеҲ
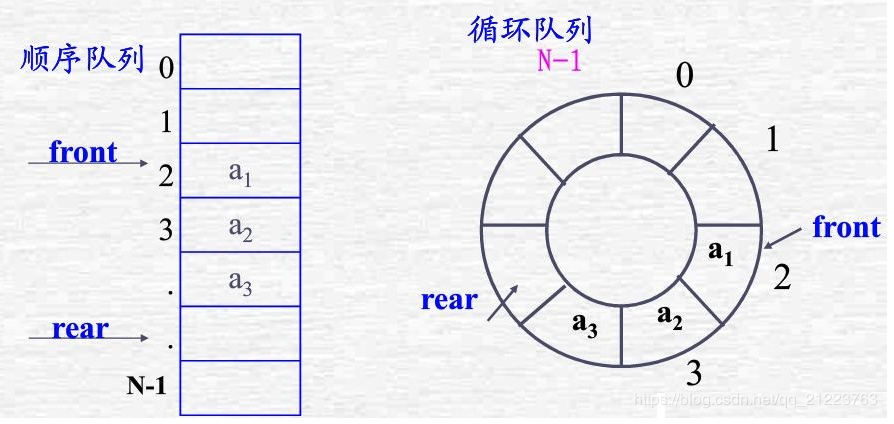
еҫӘзҺҜйҳҹеҲ—пјҡжҠҠйҳҹеҲ—зҡ„еӨҙе°ҫзӣёиҝһжҺҘ并且дҪҝз”ЁйЎәеәҸеӯҳеӮЁз»“жһ„иҝӣиЎҢж•°жҚ®еӯҳеӮЁзҡ„йҳҹеҲ—гҖӮ
еӣҫзүҮжқҘжәҗиҮӘзҪ‘з»ңпјҢдҫөеҲ
еӯҳеңЁе№¶еҸ‘зҡ„еңәжҷҜдёӢпјҢйҳҹеҲ—еӯҳеҸ–е…ғзҙ зҡ„дёҙз•ҢеҢәдёә enqueueгҖҒdequeueж“ҚдҪңгҖӮдҝқиҜҒ并еҸ‘дёӢзҡ„йҳҹеҲ—еӯҳеҸ–е®үе…Ёзҡ„йҳҹеҲ—дёәйҳ»еЎһйҳҹеҲ— е’Ң 并еҸ‘йҳҹеҲ—гҖӮдёӨиҖ…зҡ„еҢәеҲ«еңЁдәҺ еҗҢжӯҘиө„жәҗзҡ„зІ’еәҰдёҚеҗҢгҖӮ
йҳ»еЎһйҳҹеҲ—пјҡйҖҡиҝҮ дә’ж–Ҙй”Ғ дҝқиҜҒenqueueгҖҒdequeueзҡ„е®үе…ЁпјҢй”ҒзІ’еәҰиҫғеӨ§гҖӮеҰӮJava JUCеҢ…дёӯзҡ„йҳ»еЎһйҳҹеҲ—гҖӮ
并еҸ‘йҳҹеҲ—пјҡеҹәдәҺж•°з»„зҡ„еҫӘзҺҜйҳҹеҲ—пјҢеҲ©з”Ё CAS еҺҹеӯҗж“ҚдҪңдҝқиҜҒenqueueгҖҒdequeueзҡ„е®үе…ЁгҖӮеӨҡж¬ЎvolatileиҜ» + CASж“ҚдҪң enqueueгҖҒdequeueзҡ„е®үе…ЁгҖӮCASзҡ„еҗҢжӯҘд»Јд»·е°Ҹиҫғе°ҸпјҢжүҖд»Ҙз§°дёәпјҡж— й”Ғ并еҸ‘йҳҹеҲ—гҖӮеҰӮDisruptorжЎҶжһ¶дёӯRing Bufferе°ұиҝҗз”ЁдәҶиҝҷзӮ№гҖӮ
PS: еҫҲеӨҡжЎҶжһ¶еҜ№зәҝзЁӢжұ зҡ„йңҖжұӮйғҪжӣҝжҚўжҲҗдәҶDisruptorжқҘе®һзҺ°пјҢеҰӮLog4j2гҖҒCanalзӯүгҖӮ
еә”з”ЁеңәжҷҜпјҡ
йҖ’еҪ’е®һзҺ° йҖ’еҪ’ жҳҜдёҖз§Қз®—жі•жұӮи§Јзҡ„зј–з Ғе®һзҺ°гҖӮеә”з”ЁдәҺеҰӮж·ұеәҰдјҳе…ҲжҗңзҙўгҖҒеүҚдёӯеҗҺеәҸдәҢеҸүж ‘йҒҚеҺҶпјҲжҢ–еқ‘еҗҺйқўи®ІпҪһпјүзӯүгҖӮеӣ дёәжҺҘдёӢжқҘзҡ„жҺ’еәҸз®—жі•еҰӮпјҡеҪ’并/еҝ«жҺ’ еҸҜйҖҡиҝҮйҖ’еҪ’жқҘе®һзҺ°пјҢжүҖд»ҘжҲ‘们е…ҲзңӢдёҖдёӢд№ҰеҶҷйҖ’еҪ’зҡ„жӯҘйӘӨгҖӮзҶҹжӮүдәҶйҖ’еҪ’зҡ„жҖқжғіпјҢе®ғе…¶е®һжҳҜдёҖз§Қд№ҰеҶҷз®ҖеҚ•зҡ„зј–з Ғж–№ејҸгҖӮ
еҸӘиҰҒй—®йўҳж»Ўи¶ід»ҘдёӢдёүзӮ№пјҢеқҮеҸҜдҪҝз”ЁйҖ’еҪ’жқҘиҝӣиЎҢжұӮи§Јпјҡ
1.дёҖдёӘй—®йўҳзҡ„и§ЈеҸҜд»ҘеҲҶи§ЈдёәеҮ дёӘеӯҗй—®йўҳзҡ„и§Ј
еҶҷйҖ’еҪ’д»Јз Ғзҡ„е…ій”®еңЁдәҺпјҡжүҫеҲ°еҰӮдҪ•е°ҶеӨ§й—®йўҳеҲҶи§Јдёәе°Ҹй—®йўҳзҡ„规еҫӢ йҖ’жҺЁе…¬ејҸ з»ҲжӯўжқЎд»¶
еӣ дёәдәә并дёҚж“…й•ҝеӨ„зҗҶиҝҷз§ҚзЁӢеәҸпјҢжүҖд»ҘеңЁеҶҷйҖ’еҪ’д»Јз Ғзҡ„ж—¶еҖҷпјҢжҲ‘们еҸҜд»ҘиҮӘеҠЁеұҸи”ҪжҺүйҖ’еҪ’зҡ„жү§иЎҢиҝҮзЁӢгҖӮжҲ‘们еҸӘйңҖиҰҒе‘ҠиҜүзЁӢеәҸпјҡйҖ’жҺЁе…¬ејҸ е’Ң з»ҲжӯўжқЎд»¶ жҳҜд»Җд№ҲпјҢдәӢжғ…е°ұдјҡеҸҳEasy~
дҪҝз”Ёж—¶зҡ„жіЁж„ҸйЎ№пјҡ
1.stackoverflow: е®һйҷ…еҮҪж•°и°ғз”ЁеұӮж¬ЎеӨӘж·ұпјҢе°ұдјҡжңүзі»з»ҹж ҲжҲ–иҖ…иҷҡжӢҹжңәж Ҳз©әй—ҙжәўеҮәзҡ„йЈҺйҷ©гҖӮ
2.еӯҗй—®йўҳзҡ„йҮҚеӨҚи®Ўз®—пјҡеүҚйқўж–Үз« жҲ‘жңүи®І еҠЁжҖҒ规еҲ’йҖҡиҝҮйҒҝе…Қеӯҗй—®йўҳзҡ„йҮҚеӨҚи®Ўз®—иғҪеӨҹйҷҚдҪҺж—¶й—ҙеӨҚжқӮеәҰгҖӮдёҖз§Қж–№ејҸе°ұжҳҜйҖҡиҝҮ йҖ’еҪ’ + еӨҮеҝҳеҪ•пјҲеӯҗй—®йўҳзҡ„и§Јдҝқеӯҳиө·жқҘпјүжқҘи§ЈеҶігҖӮ
жҺ’еәҸз®—жі• 233й…ұеӯҰд№ зҡ„第дёҖдёӘз®—жі•е°ұжҳҜеҶ’жіЎжҺ’еәҸз®—жі•пјҢжҲ‘жғідёҚе°‘з ҒеҶңйғҪз»ҸеҺҶиҝҮиў« вҖңеҮ еӨ§жҺ’еәҸз®—жі•вҖқ ж”Ҝй…Қзҡ„жҒҗжғ§гҖӮ
жҺ’еәҸжҳҜжҲ‘们еңЁйЎ№зӣ®е·ҘзЁӢдёӯз»ҸеёёйҒҮеҲ°зҡ„дёҖдёӘеңәжҷҜпјҢеҰӮTopKпјҢдёӯдҪҚж•°й—®йўҳзӯүгҖӮжңүеәҸ е’Ң ж— еәҸ зҡ„ж•°жҚ®йӣҶеҗҲд№Ӣй—ҙзҡ„е·®еҲ«еңЁдәҺ еүҚиҖ… вҖңйҖҶеәҸеҜ№вҖқ дёә0.
е°ҸиҙҙеЈ«пјҡеҰӮжһңi < jпјҢдё”a[i] > a[j], е°ұз§°дёәдёҖдёӘйҖҶеәҸеҜ№пјҢеҰӮ 1пјҢ7пјҢ3пјҢ5 дёӯзҡ„ <7пјҢ5>
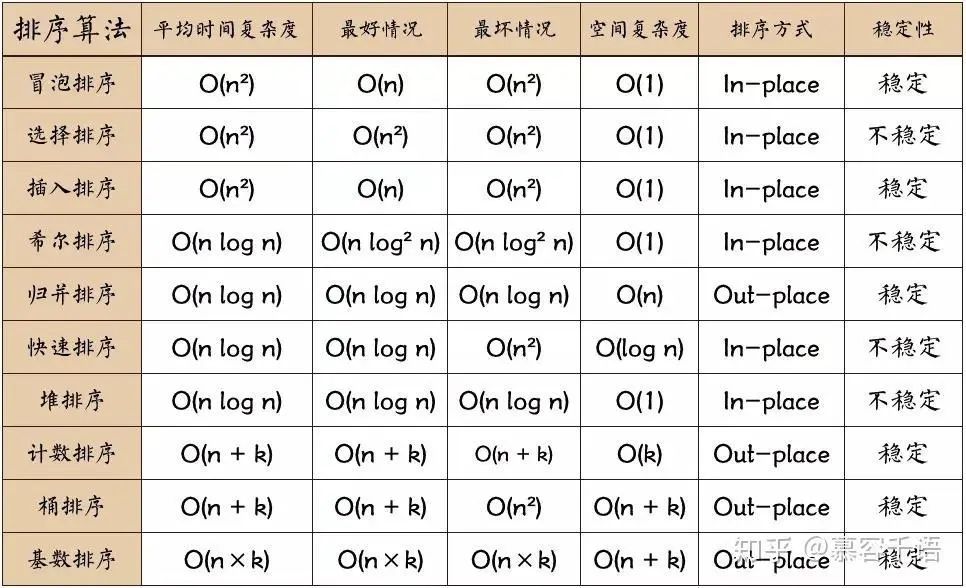
дёҚеҗҢзҡ„жҺ’еәҸз®—жі•ж¶ҲзҒӯйҖҶеәҸеҜ№зҡ„ж–№ејҸдёҚдёҖж ·пјҢдҪ“зҺ°еңЁж—¶з©әеӨҚжқӮеәҰпјҢжҺ’еәҸж–№ејҸпјҢзЁіе®ҡжҖ§пјҢйҖӮз”ЁеңәжҷҜзӯүж–№йқўдёҚеҗҢгҖӮ
жҲ‘е…Ҳж”ҫдёҖеј зҪ‘дёҠжҺ’еәҸз®—жі•зҡ„еӣҫпјҡ
еӣҫзүҮжқҘжәҗиҮӘзҪ‘з»ңпјҢдҫөеҲ
йҖүжӢ©жҺ’еәҸз®—жі•ж—¶пјҢжҲ‘们еә”иҜҘиҖғиҷ‘з®—жі•зҡ„жү§иЎҢж•ҲзҺҮпјҢеҶ…еӯҳж¶ҲиҖ—пјҢзЁіе®ҡжҖ§зӯүиҝҷдәӣеӣ зҙ гҖӮ
PSпјҡд»ҘдёӢеҶ…е®№дё»иҰҒеј•з”ЁжһҒе®ўж—¶й—ҙзҺӢдәүеӨ§дҪ¬зҡ„гҖҠж•°жҚ®з»“жһ„е’Ңз®—жі•д№ӢзҫҺгҖӢиҜҫзЁӢпјҢ233иғҪеҠӣжңүйҷҗпјҢй»ҳй»ҳз»ҷеӨ§дҪ¬жү“е№ҝе‘Ҡ&зӮ№иөһгҖӮ
еҰӮдҪ•еҲҶжһҗжҺ’еәҸз®—жі•зҡ„жү§иЎҢж•ҲзҺҮ 1. жңҖеҘҪжғ…еҶөгҖҒжңҖеқҸжғ…еҶөгҖҒе№іеқҮжғ…еҶөж—¶й—ҙеӨҚжқӮеәҰ
еҜ№дәҺиҰҒжҺ’еәҸзҡ„еҺҹе§Ӣж•°жҚ®пјҢж•°жҚ®зҡ„жңүеәҸеәҰдёҚеҗҢпјҢеҜ№жҺ’еәҸзҡ„жү§иЎҢж•ҲзҺҮжҳҜжңүеҪұе“Қзҡ„гҖӮжҜ”еҰӮжҺҘиҝ‘жңүеәҸзҡ„еҫ…жҺ’еәҸж•°жҚ® жҸ’е…ҘжҺ’еәҸзҡ„ж—¶й—ҙеӨҚжқӮеәҰжҺҘиҝ‘O(n)гҖӮжҲ‘们йңҖиҰҒдәҶи§ЈжҺ’еәҸз®—жі•еңЁдёҚеҗҢж•°жҚ®дёӢзҡ„жҖ§иғҪиЎЁзҺ°гҖӮ
2.ж—¶й—ҙеӨҚжқӮеәҰзҡ„зі»ж•°гҖҒеёёж•° гҖҒдҪҺйҳ¶
еңЁеҜ№е°Ҹ规模зҡ„ж•°жҚ®жҺ’еәҸж—¶пјҢеҰӮ10дёӘпјҢ100дёӘпјҢ1000дёӘгҖӮйңҖиҰҒжҠҠзі»ж•°гҖҒеёёж•°гҖҒдҪҺйҳ¶д№ҹиҖғиҷ‘иҝӣжқҘпјҢжүҚиғҪйҖүжӢ©еҗҲйҖӮзҡ„жҺ’еәҸз®—жі•гҖӮ
3.жҜ”иҫғж¬Ўж•°е’ҢдәӨжҚўпјҲжҲ–移еҠЁпјүж¬Ўж•°
еҹәдәҺжҜ”иҫғзҡ„жҺ’еәҸз®—жі•зҡ„жү§иЎҢиҝҮзЁӢпјҢдјҡж¶үеҸҠдёӨз§Қж“ҚдҪңпјҢдёҖз§ҚжҳҜе…ғзҙ жҜ”иҫғеӨ§е°ҸпјҢеҸҰдёҖз§ҚжҳҜе…ғзҙ дәӨжҚўжҲ–移еҠЁгҖӮжүҖд»ҘпјҢеҰӮжһңжҲ‘们еңЁеҲҶжһҗжҺ’еәҸз®—жі•зҡ„жү§иЎҢж•ҲзҺҮзҡ„ж—¶еҖҷпјҢеә”иҜҘжҠҠжҜ”иҫғж¬Ўж•°е’ҢдәӨжҚўпјҲжҲ–移еҠЁпјүж¬Ўж•°д№ҹиҖғиҷ‘иҝӣеҺ»гҖӮ
жҺ’еәҸз®—жі•зҡ„еҶ…еӯҳж¶ҲиҖ— дёҠеӣҫдёӯжңүдёҖеҲ—жҺ’еәҸж–№ејҸпјҡеҺҹең°жҺ’еәҸпјҲIn-placeпјү е’Ң еӨ–йғЁжҺ’еәҸ(Out-place)гҖӮеүҚиҖ…жҳҜжҢҮз©әй—ҙеӨҚжқӮеәҰдёәO(1)зҡ„жҺ’еәҸз®—жі•пјҢдёҚйңҖиҰҒеңЁеӨ–йғЁејҖиҫҹеҶ…еӯҳз©әй—ҙгҖӮеҗҺиҖ…йңҖиҰҒйўқеӨ–ејҖиҫҹз©әй—ҙжқҘеӯҳеӮЁдёӯй—ҙзҠ¶жҖҒгҖӮеүҚиҖ…зҡ„еҘҪеӨ„еңЁдәҺеҸҜд»ҘеҖҹеҠ© CPU зҡ„зј“еӯҳжңәеҲ¶пјҢи®ҝй—®ж•ҲзҺҮжӣҙй«ҳгҖӮиҝҷжҳҜдёҖдёӘйҮҚиҰҒзҡ„иҖғйҮҸеӣ зҙ гҖӮ
е°ҸиҙҙеЈ«пјҡеҝ«жҺ’зҡ„з©әй—ҙеӨҚжқӮеәҰдёәжҳҜеӣ дёәе®ғзҡ„е®һзҺ°жҳҜйҖ’еҪ’и°ғз”Ёзҡ„пјҢ жҜҸж¬ЎеҮҪж•°и°ғз”ЁдёӯеҸӘдҪҝз”ЁдәҶеёёж•°зҡ„з©әй—ҙпјҢеӣ жӯӨз©әй—ҙеӨҚжқӮеәҰзӯүдәҺйҖ’еҪ’ж·ұеәҰO(logn)гҖӮ
жҺ’еәҸз®—жі•зҡ„зЁіе®ҡжҖ§ зЁіе®ҡжҖ§жҳҜжҢҮпјҡеҫ…жҺ’еәҸзҡ„еәҸеҲ—дёӯеӯҳеңЁеҖјзӣёзӯүзҡ„е…ғзҙ пјҢз»ҸиҝҮжҺ’еәҸд№ӢеҗҺпјҢзӣёзӯүе…ғзҙ д№Ӣй—ҙеҺҹжңүзҡ„е…ҲеҗҺйЎәеәҸжҳҜдёҚеҸҳзҡ„гҖӮ
дёәе•ҘиҰҒиҖғиҷ‘жҺ’еәҸз®—жі•зҡ„зЁіе®ҡжҖ§е‘ўпјҹ
иҝҷжҳҜеӣ дёәе®һйҷ…еңәжҷҜдёӯзҡ„еҫ…жҺ’еәҸзҡ„еҜ№иұЎ жҺ’еәҸз»ҙеәҰеҸҜиғҪжҳҜеӨҡдёӘгҖӮжҜ”еҰӮжҲ‘们еҜ№и®ўеҚ•е…ҲжҢүз…§йҮ‘йўқжҺ’еәҸпјҢеҶҚжҢүз…§дёӢеҚ•ж—¶й—ҙжҺ’еәҸгҖӮе®һзҺ°з®ҖеҚ•зҡ„жҖқи·Ҝдёәпјҡе…Ҳз»ҷи®ўеҚ•жҢүз…§ дёӢеҚ•ж—¶й—ҙжҺ’еәҸпјҢеҶҚжҢүз…§йҮ‘йўқжҺ’еәҸгҖӮзЁіе®ҡжҖ§зҡ„жҺ’еәҸз®—жі•иғҪеӨҹдҝқиҜҒ йҮ‘йўқзӣёеҗҢзҡ„дёӨдёӘеҜ№иұЎпјҢеңЁжҺ’еәҸд№ӢеҗҺзҡ„дёӢеҚ•йЎәеәҸдёҚеҸҳгҖӮ
дёӢйқўдё»иҰҒд»Һж•°жҚ®и§„жЁЎдёҠи®Ёи®әиҝҷдәӣжҺ’еәҸз®—жі•зҡ„еә”з”ЁгҖӮ
е°Ҹ规模数жҚ®жҺ’еәҸ
еңЁе°Ҹ规模数жҚ®дёӢпјҢеҶ’жіЎжҺ’еәҸ/йҖүжӢ©жҺ’еәҸ/жҸ’е…ҘжҺ’еәҸе®һзҺ°иҫғдёәз®ҖеҚ•пјҢжҺ’йҷӨдёҚзЁіе®ҡзҡ„йҖүжӢ©жҺ’еәҸпјҢжҸ’е…ҘжҺ’еәҸпјҲеҸҜзұ»жҜ”жү“жү‘е…ӢжҠ“зүҢж—¶зҡ„жҺ’еәҸжҖқжғіпјүжҜ”еҶ’жіЎжҺ’еәҸпјҲжңҖеӨ§е…ғзҙ дҫқж¬ЎеҫҖеҗҺеҶ’пјүеҘҪеңЁдәӨжҚўж¬Ўж•°е°‘пјҢе°Ҹ规模дёӢжҺ’еәҸж•ҲзҺҮжӣҙй«ҳгҖӮ
жӯӨеӨ–еҪ“еҫ…жҺ’еәҸеәҸеҲ—зҡ„жңүеәҸеәҰжҜ”иҫғй«ҳж—¶пјҢжҸ’е…ҘжҺ’еәҸд№ҹеҘҪиҝҮеҪ’并/еҝ«жҺ’иҝҷзұ»O(nlogn)зҡ„ж•ҲзҺҮгҖӮжүҖд»ҘеңЁе°Ҹ规模数жҚ®еңәжҷҜдёӢпјҢйҖӮеҗҲз”ЁжҸ’е…ҘжҺ’еәҸгҖӮ
еӨ§и§„жЁЎеҶ…еӯҳзә§ж•°жҚ®жҺ’еәҸ
еӨ§и§„жЁЎж•°жҚ®жҺ’еәҸйҖӮеҗҲиҖғиҷ‘O(nlogn)зә§еҲ«зҡ„жҺ’еәҸз®—жі•пјҢиҝҷйҮҢи®Ёи®ә еҪ’并жҺ’еәҸ е’Ң еҝ«йҖҹжҺ’еәҸгҖӮеҪ’并жҺ’еәҸ зҡ„жҖқжғіжҳҜ еҲҶжІ» жҖқжғігҖӮе°Ҷж•ҙдёӘж— еәҸеәҸеҲ—зҡ„жҺ’еәҸ еҲ’еҲҶдёә ж— еәҸе°ҸеәҸеҲ—зҡ„жҺ’еәҸй—®йўҳгҖӮеӯҗеәҸеҲ—жңүеәҸдәҶпјҢеҶҚеҗҲ并иө·жқҘжңүеәҸзҡ„еӯҗеәҸеҲ—пјҢж•ҙдҪ“е°ұжҺ’еҘҪеәҸдәҶгҖӮ
еҪ’并жҺ’еәҸжҳҜеӨ–йғЁжҺ’еәҸгҖӮжҜҸж¬ЎеҗҲ并ж“ҚдҪңйғҪйңҖиҰҒз”іиҜ·йўқеӨ–зҡ„еҶ…еӯҳз©әй—ҙпјҢеңЁеҗҲ并е®ҢжҲҗд№ӢеҗҺпјҢдёҙж—¶ејҖиҫҹзҡ„еҶ…еӯҳз©әй—ҙе°ұиў«йҮҠж”ҫжҺүдәҶгҖӮеңЁд»»ж„Ҹж—¶еҲ»пјҢCPU еҸӘдјҡжңүдёҖдёӘеҮҪж•°еңЁжү§иЎҢпјҢд№ҹе°ұеҸӘдјҡжңүдёҖдёӘдёҙж—¶зҡ„еҶ…еӯҳз©әй—ҙеңЁдҪҝз”ЁгҖӮдёҙж—¶еҶ…еӯҳз©әй—ҙжңҖеӨ§д№ҹдёҚдјҡи¶…иҝҮ n дёӘж•°жҚ®зҡ„еӨ§е°ҸпјҢжүҖд»Ҙз©әй—ҙеӨҚжқӮеәҰжҳҜ O(n)гҖӮ
еҝ«йҖҹжҺ’еәҸ еҲ©з”Ёзҡ„д№ҹжҳҜ еҲҶжІ» жҖқжғігҖӮеұҖйғЁжңүеәҸ жңҖз»ҲеҜјиҮҙ е…ЁеұҖжңүеәҸгҖӮе®ғдҪҝз”ЁдёҖдёӘеҲҶеҢәзӮ№ж•°жҚ®(pivort)е°Ҷе…ғзҙ еҲҶдёә< pivort,=pivort,>pivortдёүдёӘйғЁеҲҶгҖӮ然еҗҺеңЁ< pivort е’Ң >pivortиҝҷдёӨйғЁеҲҶ继з»ӯйҖ’еҪ’еӨ„зҗҶпјҢжңҖз»ҲжҺ’еәҸе®ҢжҲҗгҖӮ
еҰӮжһң еҝ«жҺ’еҗҲзҗҶзҡ„йҖүжӢ©pivortпјҢеӨҡи·ҜжҢҮй’ҲеҸӮдёҺеҲҶеҢәеҸҜд»ҘйҒҝе…Қж—¶й—ҙеӨҚжқӮеәҰзҡ„жҒ¶еҢ–гҖӮиҖҢдё”еҝ«жҺ’жҳҜеҺҹең°жҺ’еәҸпјҢзӣёжҜ”еҪ’并жҺ’еәҸжҳҜеӨ–йғЁжҺ’еәҸпјҢз©әй—ҙеӨҚжқӮеәҰиҫғй«ҳO(n)гҖӮеҝ«жҺ’зҡ„еә”з”Ёжӣҙдёәе№ҝжіӣгҖӮ
JavaдёӯArrays.sortжҳҜж··еҗҲжҺ’еәҸпјҢе®һзҺ°зӯ–з•ҘеҲҶдёәдёӨз§Қпјҡ
Case1. еӯҳеӮЁзҡ„ж•°жҚ®зұ»еһӢжҳҜеҹәжң¬ж•°жҚ®зұ»еһӢ
дҪҝз”Ёзҡ„жҳҜеҝ«жҺ’пјҢеңЁж•°жҚ®йҮҸеҫҲе°Ҹзҡ„ж—¶еҖҷпјҢдҪҝз”Ёзҡ„жҸ’е…ҘжҺ’еәҸпјӣ
Case2. еӯҳеӮЁзҡ„ж•°жҚ®зұ»еһӢжҳҜObject
дҪҝз”Ёзҡ„жҳҜеҪ’并жҺ’еәҸпјҢеңЁж•°жҚ®йҮҸеҫҲе°Ҹзҡ„ж—¶еҖҷпјҢдҪҝз”Ёзҡ„д№ҹжҳҜжҸ’е…ҘжҺ’еәҸгҖӮ
еӨ§и§„жЁЎеӨ–йғЁж•°жҚ®жҺ’еәҸ
еҪ“ж•°жҚ®и§„жЁЎеҫҲеӨ§ж—¶пјҢжҲ‘们并дёҚиғҪжҠҠжүҖжңүж•°жҚ®йғҪеҠ иҪҪеҲ°еҶ…еӯҳгҖӮиҝҷж—¶еҖҷеҸҜд»ҘиҖғиҷ‘ж—¶й—ҙеӨҚжқӮеәҰжҳҜ O(n) зҡ„еӨ–йғЁжҺ’еәҸз®—жі•пјҡжЎ¶жҺ’еәҸгҖҒи®Ўж•°жҺ’еәҸгҖҒеҹәж•°жҺ’еәҸгҖӮеӨ–йғЁжҺ’еәҸжҳҜжҢҮж•°жҚ®еӯҳеӮЁеңЁеӨ–йғЁзЈҒзӣҳдёӯгҖӮ
иҝҷйҮҢж—¶й—ҙеӨҚжқӮеәҰд№ӢжүҖд»ҘдҪҺжҳҜеӣ дёәпјҡиҝҷдёүдёӘз®—жі•жҳҜйқһеҹәдәҺжҜ”иҫғзҡ„жҺ’еәҸз®—жі•пјҢйғҪдёҚж¶үеҸҠе…ғзҙ д№Ӣй—ҙзҡ„жҜ”иҫғж“ҚдҪңгҖӮ
жЎ¶жҺ’еәҸ жҳҜжҢүз…§жҹҗз§ҚеұһжҖ§е°Ҷе…ғзҙ еҲҶй…ҚеҲ°е…ЁеұҖжңүеәҸзҡ„еӯҗжЎ¶еҶ…пјҢеҶҚеңЁеӯҗжЎ¶еҶ…еҒҡеұҖйғЁжҺ’еәҸгҖӮеҪ“еӯҗжЎ¶дёӘж•°еҲ’еҲҶзҡ„и¶іеӨҹеӨ§ж—¶пјҢж—¶й—ҙеӨҚжқӮеәҰе°ұжҺҘиҝ‘O(n) гҖӮ
и®Ўж•°жҺ’еәҸ е…¶е®һжҳҜжЎ¶жҺ’еәҸзҡ„дёҖз§Қзү№ж®Ҡжғ…еҶөгҖӮеҪ“иҰҒжҺ’еәҸзҡ„ n дёӘж•°жҚ®пјҢжүҖеӨ„зҡ„иҢғеӣҙ并дёҚеӨ§зҡ„ж—¶еҖҷпјҢжҜ”еҰӮжңҖеӨ§еҖјжҳҜ kпјҢжҲ‘们е°ұеҸҜд»ҘжҠҠж•°жҚ®еҲ’еҲҶжҲҗ k дёӘжЎ¶гҖӮжҜҸдёӘжЎ¶еҶ…зҡ„ж•°жҚ®еҖјйғҪжҳҜзӣёеҗҢзҡ„пјҢзңҒжҺүдәҶжЎ¶еҶ…жҺ’еәҸзҡ„ж—¶й—ҙгҖӮ
еҹәж•°жҺ’еәҸ жҳҜж №жҚ®жҜҸдёҖдҪҚжқҘжҺ’еәҸпјҢеҹәж•°жҺ’еәҸеҜ№иҰҒжҺ’еәҸзҡ„ж•°жҚ®жҳҜжңүиҰҒжұӮзҡ„пјҢйңҖиҰҒеҸҜд»ҘеҲҶеүІеҮәзӢ¬з«Ӣзҡ„вҖңдҪҚвҖқжқҘжҜ”иҫғпјҢиҖҢдё”дҪҚд№Ӣй—ҙжңүйҖ’иҝӣзҡ„е…ізі»пјҢеҰӮжһң a ж•°жҚ®зҡ„й«ҳдҪҚжҜ” b ж•°жҚ®еӨ§пјҢйӮЈеү©дёӢзҡ„дҪҺдҪҚе°ұдёҚз”ЁжҜ”иҫғдәҶгҖӮйҷӨжӯӨд№ӢеӨ–пјҢжҜҸдёҖдҪҚзҡ„ж•°жҚ®иҢғеӣҙдёҚиғҪеӨӘеӨ§пјҢиҰҒеҸҜд»Ҙз”ЁзәҝжҖ§жҺ’еәҸз®—жі•жқҘжҺ’еәҸпјҢеҗҰеҲҷпјҢеҹәж•°жҺ’еәҸзҡ„ж—¶й—ҙеӨҚжқӮеәҰе°ұж— жі•еҒҡеҲ° O(n) дәҶгҖӮ
е…ідәҺеёёи§Ғж•°жҚ®з»“жһ„е’Ңз®—жі•зҡ„еә”з”Ёзі»еҲ—зӨәдҫӢеҲҶжһҗе°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ