JSON作为一种轻量级的数据交换格式,因其易于读写和交互的特点,已逐渐成为主流的数据类型之一。常见的编程语言大多都对 JSON 的读取与解析提供了接口,但是接下来如何把多层 JSON 数据经过筛选、计算并展开成二维数据,就需要开发人员去头疼了。本文就为大家分享一下如何利用集算器 SPL(结构化处理语言)轻松解决 JSON 数据解析入库的问题。
JSON 数据文件导入与解析
根据 JSON 数据文件的复杂程度,以及不同的需求,我们会分三种情况来讨论:
1. 单层的 JSON 数据文件
我们先从一个简单的例子入手,看看普通键值映射的 JSON 文件如何读取。下面是某产品订单信息的 JSON 数据文件:

SPL导入 JSON 数据文件只需要简单的一句脚本:
= json(file("product.json").read()) |
不需要写循环函数,也不用解析 JSON 对象,执行一下就可以看到,JSON 数据文件已经转换为二维数据序表了:
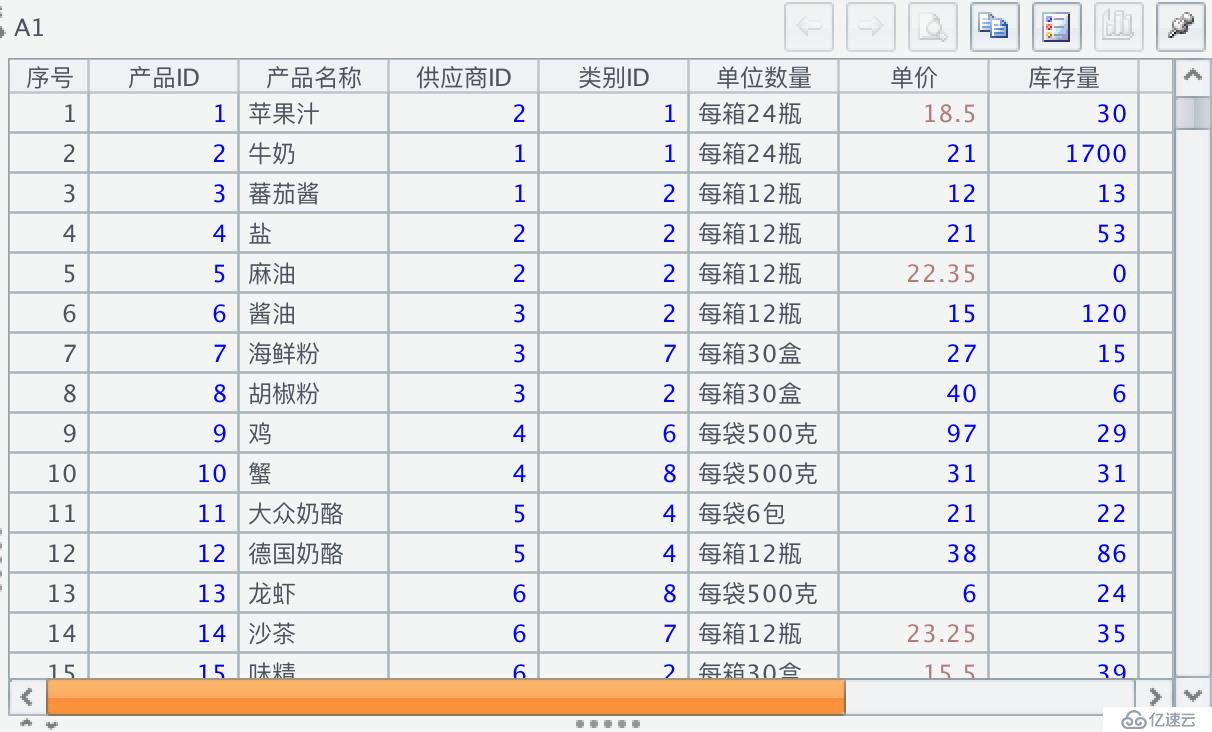
2. 明细数据相同结构的多层 JSON 数据文件
接下来,我们看一下多层的 JSON 文件如何处理。下面是我们要用到的 JSON 数据文件 orders.json:

可以看到,JSON 数据分为两层,第一层是 "货主国家" 和 "货主地区",第二层是明细数据。现在我们想要从中导入中国华北和华南地区 2013 年的订单,让我们看看如果用 SPL 实现。
这次我们先来定义一下参数:Country、Area 和 Year,分别对应需要导入的货主国家、货主地区和订购日期的年份。通过定义参数,以后导入不同国家、地区和年份的时候,就不再需要修改 SPL,只需要提供相应的参数值就行了。这里需要注意的是,Area 的值是序列,默认值是 [华北, 华南],这样就可以同时读取多个地区的数据。如下图:

我们先看一下 SPL 脚本:
A | B | |
1 | =json(file("orders.json").read()) | =A1.select(货主国家 ==Country && Area.contain( 货主地区)) |
2 | =B1.news(区域订单;B1. 货主国家: 货主国家,B1. 货主地区: 货主地区,#1,#2,#3,#4,#5,#6,#7,#8,#9,#10,#11,#12,#13) | =A2.select(year( 订购日期)==Year) |
下面来详细解释一下:
第一步:A1 中 =json(file("orders.json").read()),导入 JSON 文件生成序表。执行一下,可以看到 JSON 数据按层级被展现出来(在集算器设计器中我们可以通过双击“区域订单”值,来查看下一层明细数据):

第二步:从图中可以看到,"货主国家" 和 "货主地区" 字段就在第一层,因此在 B1 中直接调用A1.select(货主国家 ==Country && Area.contain( 货主地区)) 就可以筛选出中国华北和华南的数据。
第三步:"区域订单" 是我们想要的明细数据,但是其中不包含 "货主国家" 和 "货主地区" 这两个字段,因此我们需要把这两个字段和区域订单的明细字段拼在一起。这么复杂的需求通过 news 函数就可以一步到位解决。从 A2 格的表达式可以看到参数并不复杂,把 B1. 货主国家,B1. 货主地区和 "区域订单" 的全部字段拼在一起就可以了。看下执行结果:
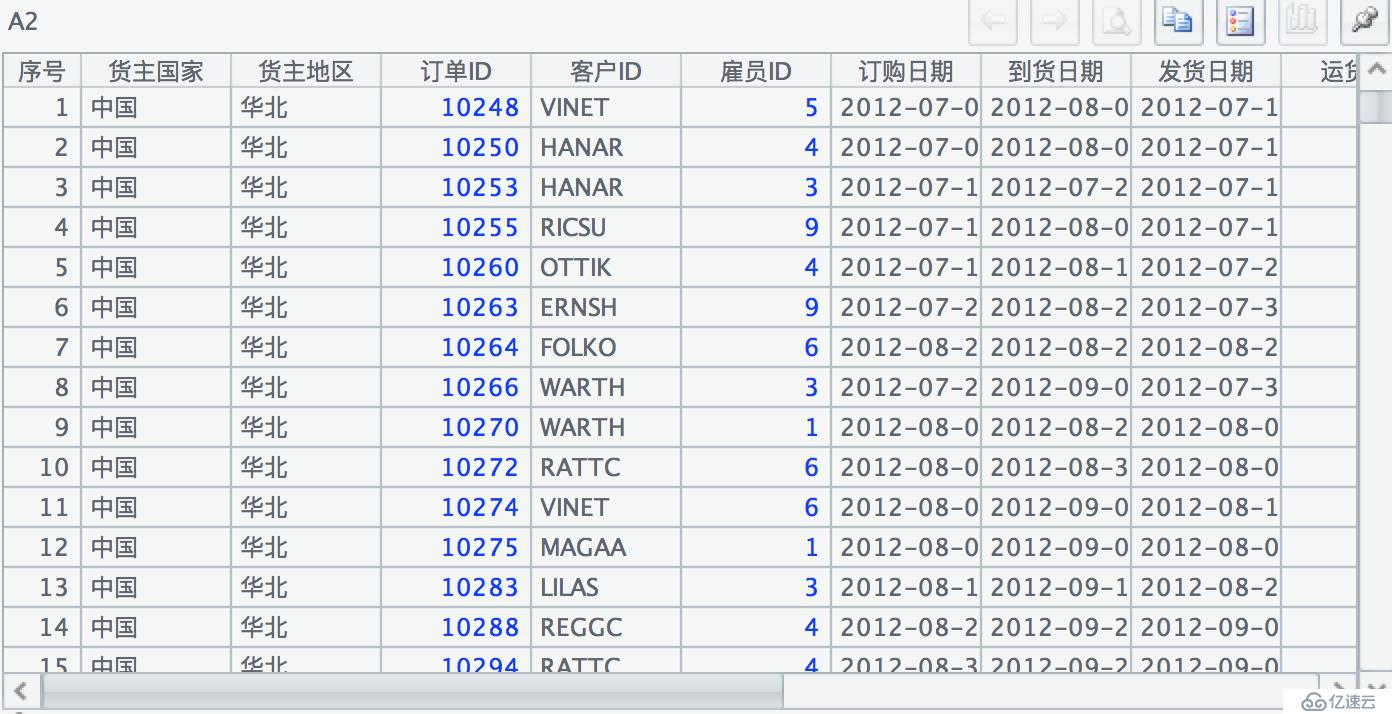
第四步:在 B2 中通过=A2.select(year( 订购日期)==Year)筛选出 "订购日期" 的年份是 2013 年的数据。
最后让我们执行一下,可以看到最终得到的二维表完全符合需求:

3. 明细数据不同结构的多层 JSON 数据文件
因为数据来源的复杂性,JSON 数据文件的明细数据有可能是不同结构的,我们一起看一下这种 JSON 文件如何处理。下面是我们要用到的 JSON 文件 sales.json:
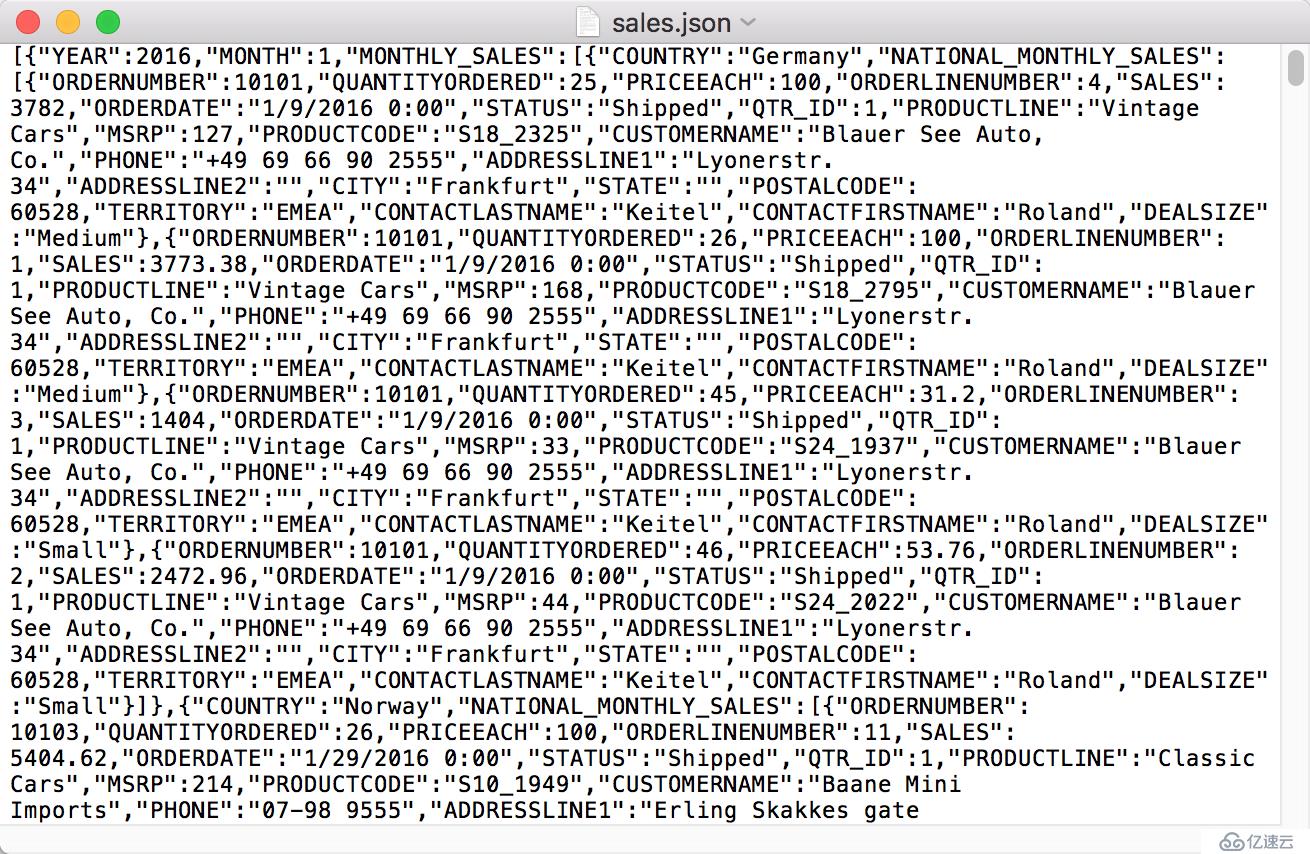
第一层以年和月为维度,第二层以国家为维度,第三层是明细数据。但是明细数据中,由于销售渠道不同,结构是不完全一致的,比如 "PRODUCTLINE"、"ADDRESSLINE1"、"ADDRESSLINE2" 在明细数据中并不是必须的。现在,我们要从数据中读取 2017 和 2018 年北美两个大国美国和加拿大的销售数据。
为了使用方便,我们还是先定义两个参数:Year 和 Country:

接下来先看一下 SPL:
A | B | |
1 | =json(file("sales.json").read()) | =A1.select(Year.contain(YEAR)) |
2 | =B1.news(MONTHLY_SALES;B1.YEAR:YEAR,B1.MONTH:MONTH,#1,#2) | =A2.select(Country.contain(COUNTRY)) |
3 | =B2.news(NATIONAL_MONTHLY_SALES;B2.YEAR:YEAR,B2.COUNTRY:COUNTRY,ORDERNUMBER,QUANTITYORDERED,PRICEEACH,ORDERLINENUMBER,SALES,ORDERDATE,STATUS,QTR_ID,PRODUCTLINE,MSRP,PRODUCTCODE,CUSTOMERNAME,PHONE,ADDRESSLINE1,ADDRESSLINE2,CITY,STATE,POSTALCODE,TERRITORY,CONTACTLASTNAME,CONTACTFIRSTNAME,DEALSIZE) |
下面来详细解释一下。
A1格还是把 JSON 文件导入为多层序表。
由于年份字段就在第一层,B1 格中直接调用A1.select(Year.contain(YEAR))可以从 A1 中筛选出 2017 和 2018 年份的数据:
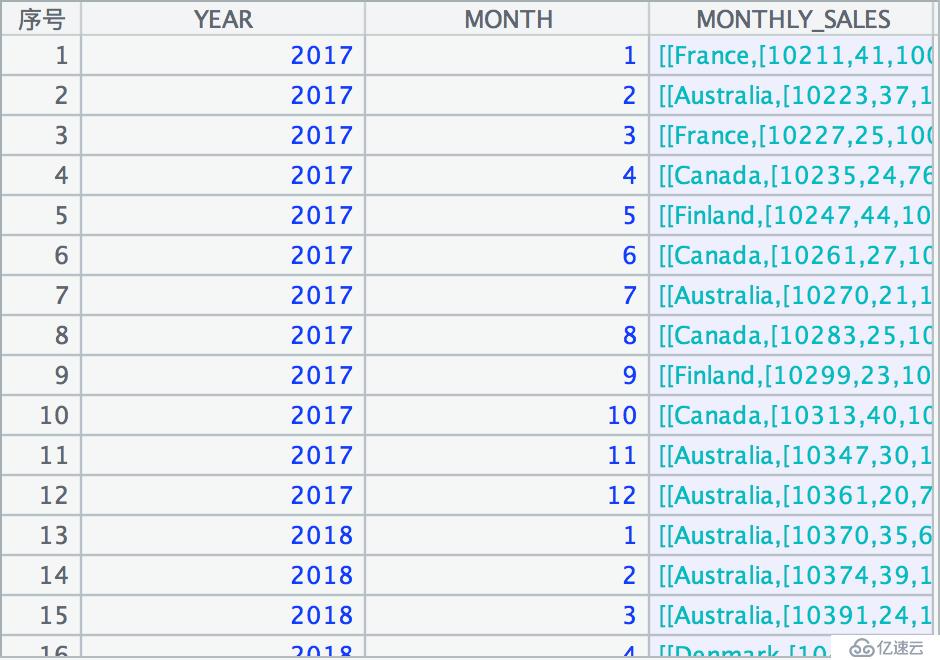
接下来 A2 格中我们再次用到了 news 函数,用来把年月字段和下一层的月销售明细拼在一起:

B2格中我们通过A2.select(Country.contain(COUNTRY))从中筛选出来美国和加拿大的数据。
然后在 A3 格中,我们再次用到了 news 函数,这次需要把 YEAR,MONTH,COUNTRY 和再下一层的国家月销售明细拼在一个序表中。由于这个文件中明细数据可能结构有所不同,我们使用全量的字段名作为参数来创建序表。字段的值会根据名称设置,无此字段的会缺省为空值(例如下图 "ADDRESSLINE1" 和 "ADDRESSLINE2" 字段):
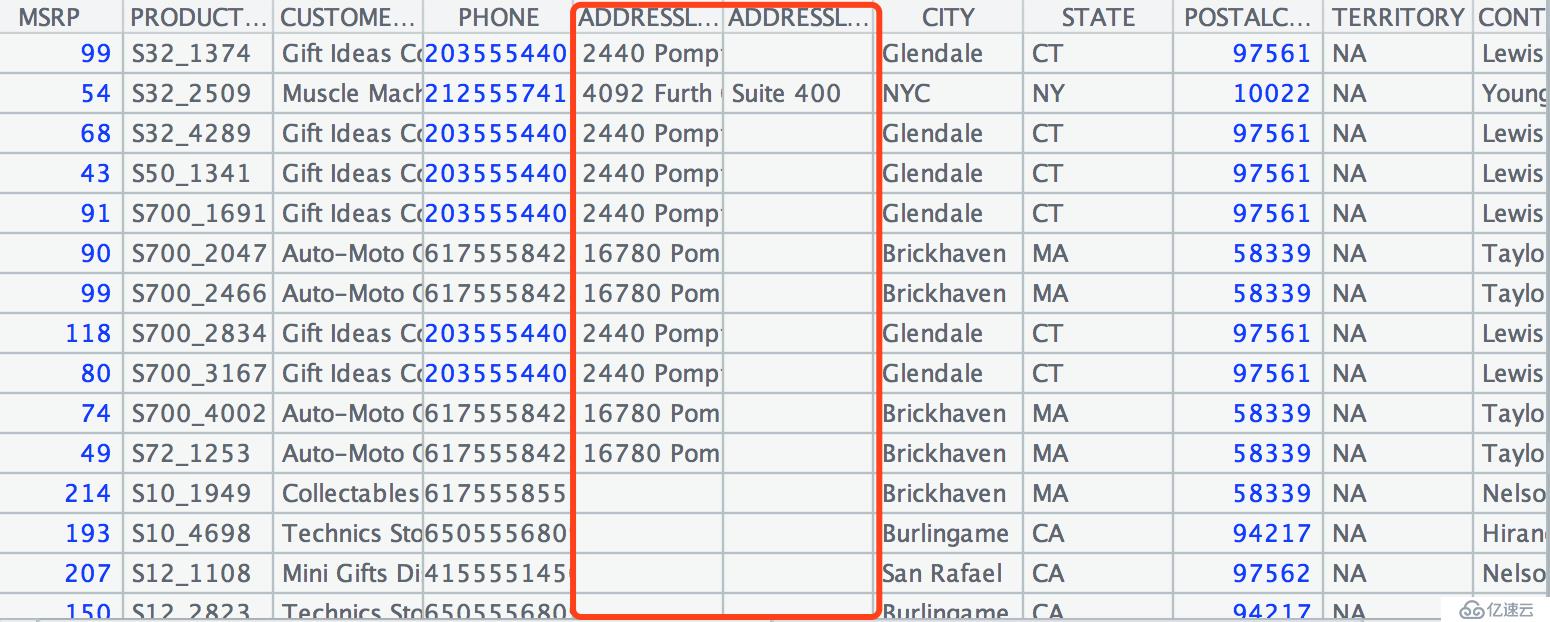
执行后可以看到最终结果:

至此,一个多层结构的明细数据结构不完全一致的 JSON 文件就成功展开成为一个二维表了。
序表入库
前面介绍了常见的 JSON 数据文件导入与解析,接下来是数据入库的问题。之所以在最后才说入库,并不是因为复杂,恰恰相反的是,由于前面的例子中最后生成的都是序表,因此更新数据库就变得非常简单方便。以前面导入 JSON 的例子 2 中的订单表为例:
A | |
1 | =file("orders.json").read().import@j().select(货主国家 ==Country && 货主地区 ==Area). 区域订单.select(year( 订购日期)==Year).derive(Country: 货主国家,Area: 货主地区) |
2 | =connect("demo").update(A1, 订单; 订单 ID) |
可以看到,更新数据库只需要一句脚本!
这里是比较常见的通过主键更新,用序表 A1 通过主键订单 ID 来更新数据库中的订单表。SPL 中的 update 函数有很多选项,可以满足更多的更新数据需求,这里就不再一一赘述了。
因此,只要用对了工具,从 JSON 文件导入解析到数据入库,再繁琐的任务也可以轻松应对。除了 JSON 数据文件,集算器 SPL 还支持各种丰富多样的数据来源,后续将通过更多的文章继续分享给大家。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





