安装前说明:
安装hive前提是要先安装hadoop集群,并且hive只需要在hadoop的namenode节点集群里安装即可(需要再所有namenode上安装),而不需要在datanode节点的机器上安装。另外还需要说明的是,虽然修改配置文件并不需要你已经把hadoop跑起来,但是本文中用到了hadoop命令(创建文件夹时使用过),在执行这些命令前你必须确保hadoop是在正常跑着的,而且启动hive的前提也是需要hadoop在正常跑着,所以建议你先将hadoop跑起来在按照本文操作。
前提:
本文假使你已成功安装Hadoop!如未安装,请参考另一篇博文《centos下安装分布式Hadoop 3.1.1》。
本文假使你已成功安装配置MySql数据,如未安装,请参考另一篇博文《MySQL数据库安装及配置相关》。
一)安装环境
Centos 7.5
JDK 1.8.0_181
Hadoop 3.1.1
Hive 3.1.0
二)下载HIVE
下载地址:http://www.apache.org/dyn/closer.cgi/hive/
打开网址,点击图1中链接,然后选择Hive 版本,比如这里选择Hive 3.1.0(如图2),然后下载打好包的软件即可(如图3):

图1
图2
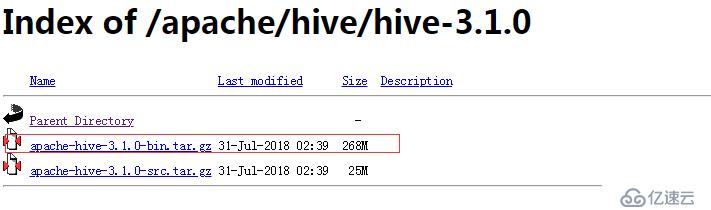
图3
三)安装
3.1 解压到特定目录,这里解压到/usr/local目录(用户自行安装软件,建议放在/usr/local目录)
# tar -zxvf apache-hive-3.1.0-bin.tar.gz -C /usr/local
3.2 设置环境变量,编辑/etc/profile添加以下红框内的内容:
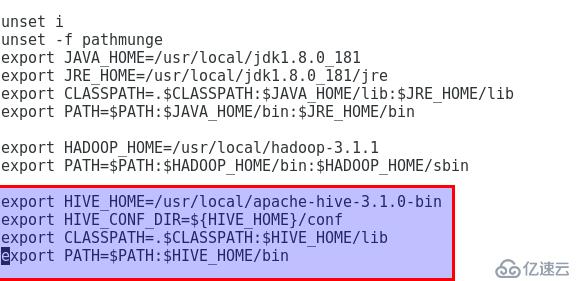
设置后运行 # source /etc/profile使修改生效。
3.3 新建3个目录,以便配置hive-site.xml文件
进入Hadoop的bin目录,运行以下命令:
# ./hadoop fs -mkdir -p /var/hive/warehouse
# ./hadoop fs -mkdir -p /var/hive/tmp
# ./hadoop fs -mkdir -p /tmp/hive
修改3个目录的权限:
# ./hadoop fs -chmod 777 /var/hive/warehouse
# ./hadoop fs -chmod 777 /var/hive/tmp
# ./hadoop fs -chmod 777 /tmp/hive
创建后,可运行# ./hadoop fs -ls /var/hive/命令进行查看是否创建成功。
3.4 编辑hive-site.xml文件
3.4.1 新建hive-site.xml文件
进入到/usr/local/apache-hive-3.1.0.bin/conf目录,将hive-default.xml.template文件复制一份,并命名为hive-site.xml.
3.4.2 修改hive-site.xml文件
3.4.2.1 修改name标签为hive.metastore.warehouse.dir的value值,如下:

3.4.2.2 修改name标签为hive.exec.scratchdir的value值,如下:

3.4.2.3 将hive-site.xml文件中所有value标签中的值中的"${system:java.io.tmpdir}"替换为"/var/hive/tmp",如下例子:

3.4.2.4 将hive-site.xml文件中所有value标签中的值中的"${system:user.name}"替换为"root",如下例子:

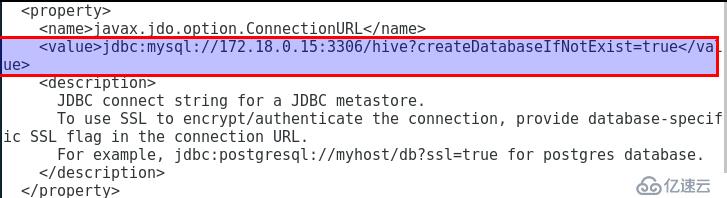
3.4.2.5 Hive元数据库配置,这里以mysql为例




3.4.2.6 将MySql驱动包传到hive的lib目录
MySql驱动包下载地址:https://dev.mysql.com/downloads/connector/j/
注意驱动与版本的对于关系,可参考网址:
https://dev.mysql.com/doc/connector-j/5.1/en/connector-j-versions.html
https://dev.mysql.com/doc/connector-j/8.0/en/connector-j-versions.html
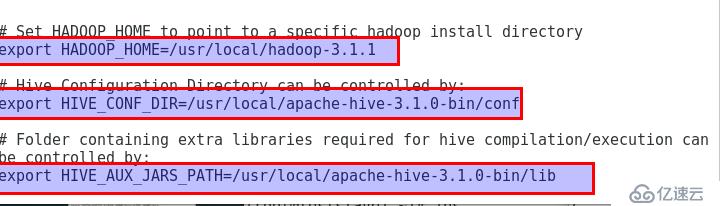
3.4.2.7 新建hive-env.sh文件并编辑
进入hive的conf目录,将hive-env.sh.template文件复制为hive-env.sh文件,并添加如下内容:
四)启动和测试
4.1 启动
进入hive的bin目录,执行命令:
# ./schematool -initSchema -dbType mysql //run this command to initialize DB.
# ./hive
4.2 测试
可执行以下命令进行测试:
# show functions; //查看支持的函数
# create database DBName; //创建数据库
# use DBName; //选中某个库
# create table TableName(id int, name string) row format delimited fields terminated by '\t'; //创建包含id及name列的表,且字段之间用Tab键分割
# load data local inpath 'File' into table DBName.TableName; //将文件File中的数据加载到创建的表中
文件的数据如下:
001 zhangsan
002 lisi
003 wangwu
004 zhaoliu
005 chenqi
说明:ID和name直接是TAB键,不是空格,因为在上面创建表的语句中用了terminated by '\t'所以这个文本里id和name的分割必须是用TAB键(复制粘贴如果有问题,手动敲TAB键吧),还有就是行与行之间不能有空行,否则下面执行load,会把NULL存入表内,该文件要使用unix格式,如果是在windows上用txt文本编辑器编辑后在上载到服务器上,需要用工具将windows格式转为unix格式,例如可以使用Notepad++来转换。
# select * from TableName; //在hive命令行窗口运行以查看表中数据
最后,还可以在mysql中查看创建的DB和Table,分别位于DBS表和TBLS表;
也可以通过namenode的URL在浏览器端查看数据:http://NameNodeIP:50070/explorer.html#/var/hive/warehouse/DBName.db //修改namenode的IP及自己配置的warehouse路径和创建的数据库名。
Appendix:
安装HIVE还可以参考网址:https://blog.csdn.net/pucao_cug/article/details/71773665 。
快速了解HIVE核心基本概念,参考网址:https://blog.csdn.net/freefish_yzx/article/details/77150248 。
快速上手使用HIVE数据仓库,参考网址: https://www.yiibai.com/hive/hive_partitioning.html 。
关于HIVE的分区概念及使用,参考网址: https://blog.csdn.net/qq_36743482/article/details/78418343 。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





