1 前言
以Java/Scala代码通过设置开始时间和结束时间的方式来进行统计测试,其实不够准确,最好的方式就是把Spark应用部署到集群中,通过观察Spark UI的统计信息来获取时间,这样会更准备,尤其是希望观察RDD缓存时对性能带来的提升。
为了更好查看Spark UI提供的信息,通过操作方便简单,下面会使用Spark Shell的方式来做测试,这样一来,就可以轻松使用Spark Shell的localhost:8080来查看应用程序的执行信息。
测试是基于大数据计算的经典helloword案例—wordcount程序来进行,所以首先应该准备一定量的数据,这里我准备的数据如下:
yeyonghao@yeyonghaodeMacBook-Pro:~$ ls -lh wordcount_text.txt
-rw-r--r-- 1 yeyonghao staff 127M 10 1 14:24 wordcount_text.txt数据量不用太大,不然就需要等待很长时间,同时在进行RDD缓存时,也有可能会出现没有足够内容来缓存RDD的问题;数据量也不要太小,太小的话,时间差别不大,很难观察出效果。
如下:
yeyonghao@yeyonghaodeMacBook-Pro:~$ sudo spark-shell --driver-memory 2G
Password:
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Using Spark's repl log4j profile: org/apache/spark/log4j-defaults-repl.properties
To adjust logging level use sc.setLogLevel("INFO")
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.6.2
/_/
Using Scala version 2.10.5 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_181)
Type in expressions to have them evaluated.
Type :help for more information.
Spark context available as sc.
18/10/01 14:39:36 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
18/10/01 14:39:36 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
18/10/01 14:39:38 WARN ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
18/10/01 14:39:38 WARN ObjectStore: Failed to get database default, returning NoSuchObjectException
18/10/01 14:39:39 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
18/10/01 14:39:39 WARN Connection: BoneCP specified but not present in CLASSPATH (or one of dependencies)
SQL context available as sqlContext.先加载数据,并设置transformation,如下:
scala> val linesRDD = sc.textFile("/Users/yeyonghao/wordcount_text.txt")
linesRDD: org.apache.spark.rdd.RDD[String] = /Users/yeyonghao/wordcount_text.txt MapPartitionsRDD[1] at textFile at <console>:27
scala> val retRDD = linesRDD.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
retRDD: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:29缓存RDD:
scala> retRDD.cache()
res0: retRDD.type = ShuffledRDD[4] at reduceByKey at <console>:29注意上面的操作并不会触发Spark的计算操作,只有执行action算子时才会触发,如下:
scala> retRDD.count()
res1: Long = 1388678此时打开Spark UI,观察执行结果:
Jobs界面: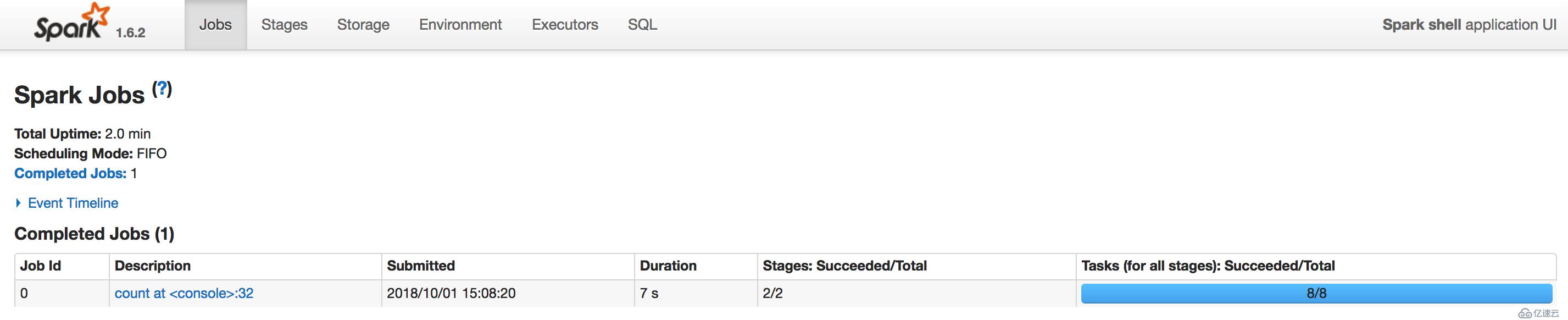
Stages界面: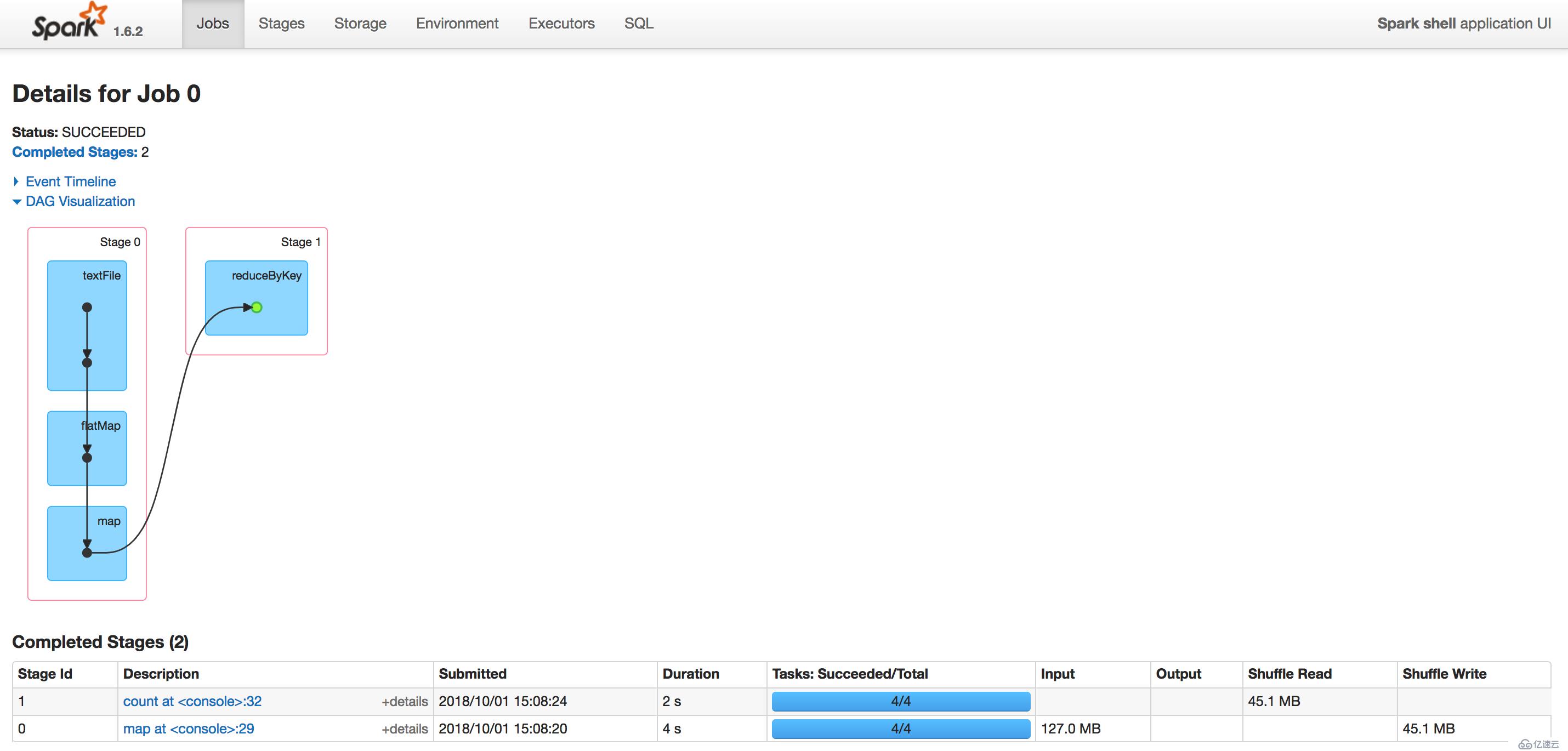
Storage界面:
分析:显然可以看到DAG图中,reduceByKey中有个绿色的点,说明该RDD已经被显示地缓存下来,这样在查看Storage界面时,也可以看到该缓存的RDD,另外需要说明的是,在执行该次操作中,所有的步骤都是需要执行的,然后产生了retRDD之后才将其缓存下来,这样下一次,如果再需要使用到retRDD时,就可以不用执行前面的操作了,可以节省很多时间,当然,不可否认地是,在本次操作中,缓存RDD时也是需要使用一定的时间的。
scala> retRDD.count()
res1: Long = 1388678Jobs界面: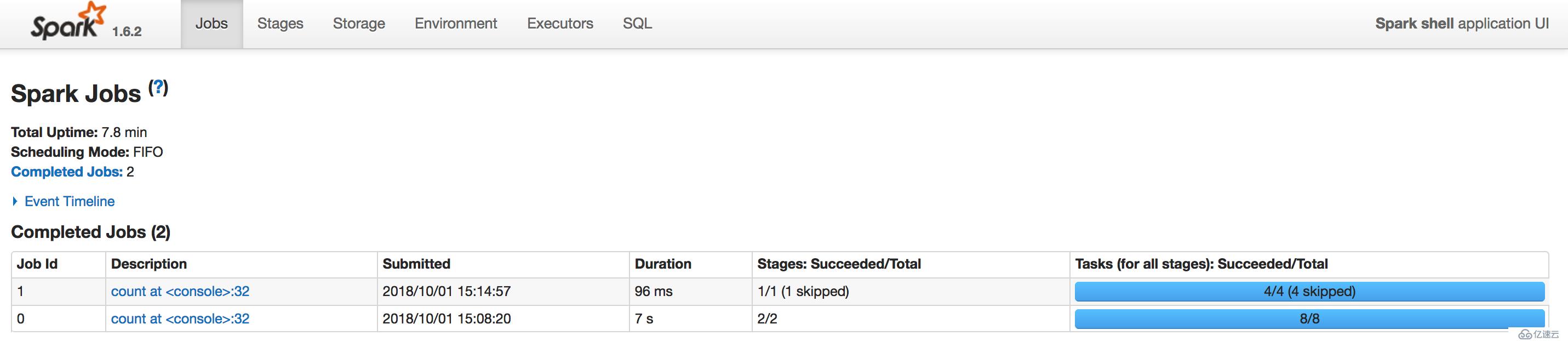
Stages界面: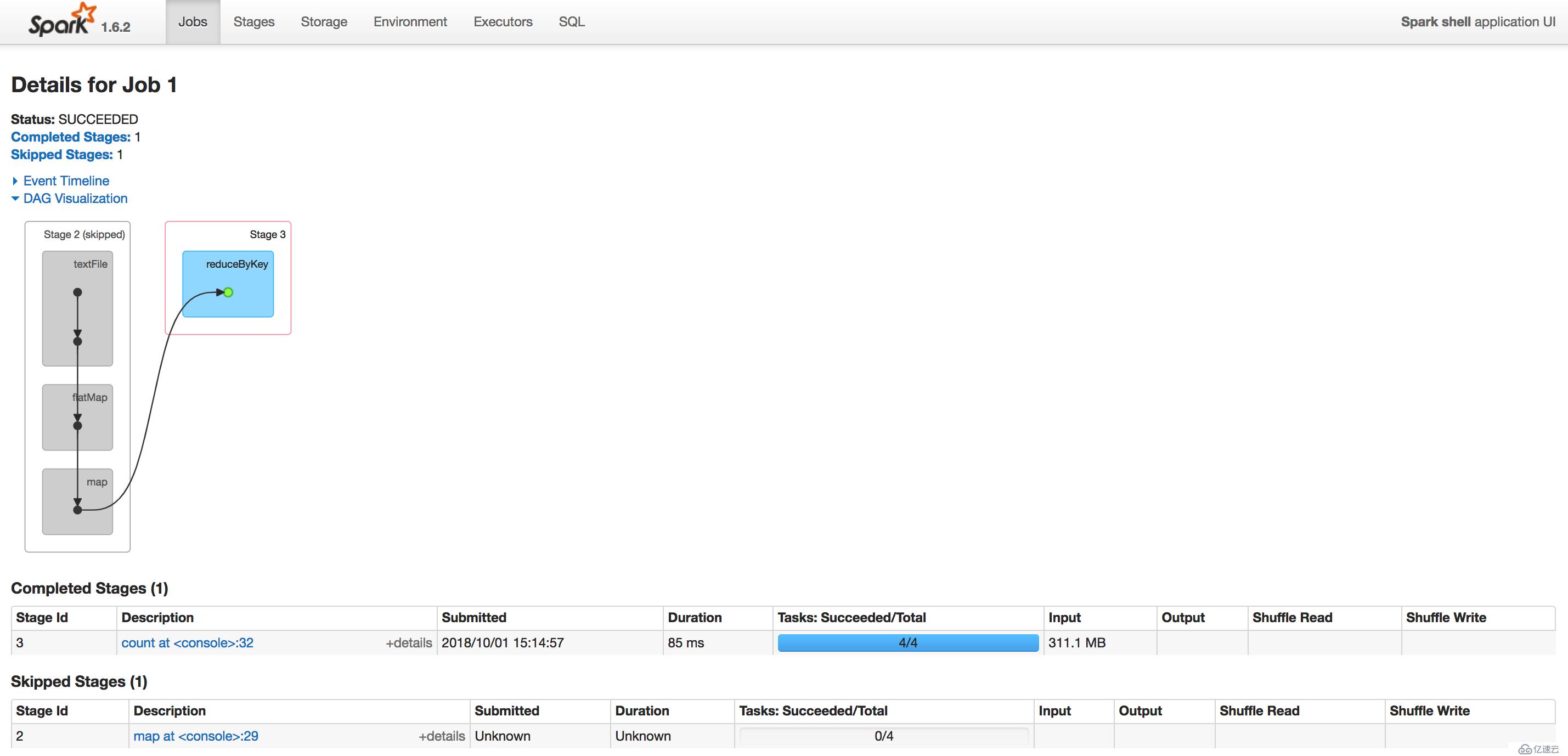
Storage界面:
分析,通过上面的观察也可以知道,retRDD前面的操作全部都没有执行,它是直接利用缓存的RDD来执行后面的action操作,所以时间上有大幅度地提升。
重新打开Spark-shell,执行下面的操作:
scala> val linesRDD = sc.textFile("/Users/yeyonghao/wordcount_text.txt")
linesRDD: org.apache.spark.rdd.RDD[String] = /Users/yeyonghao/wordcount_text.txt MapPartitionsRDD[1] at textFile at <console>:27
scala> val retRDD = linesRDD.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
retRDD: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:29
scala> retRDD.count()
res0: Long = 1388678
scala> retRDD.count()
res1: Long = 1388678
scala> retRDD.count()
res2: Long = 1388678Jos界面: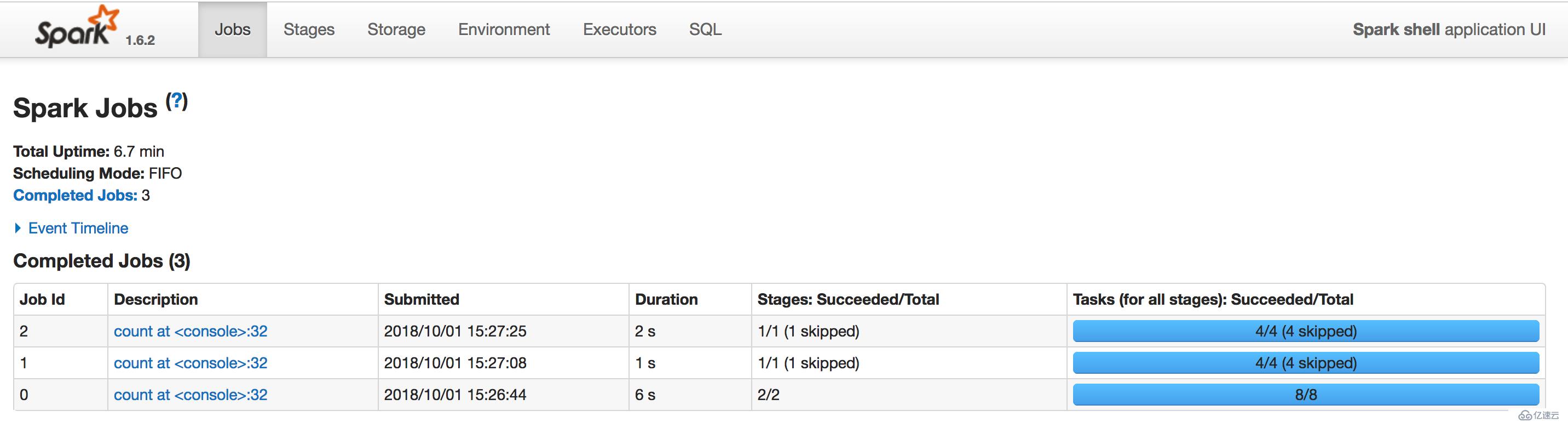
所有job的stages界面: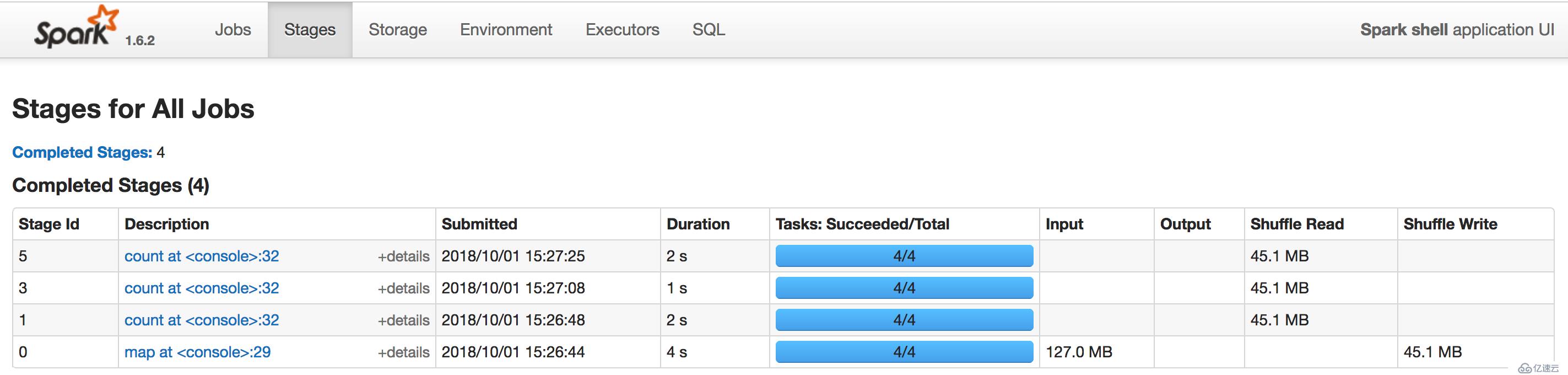
storage界面:
再查看后面两个job其中一个的详细stages界面: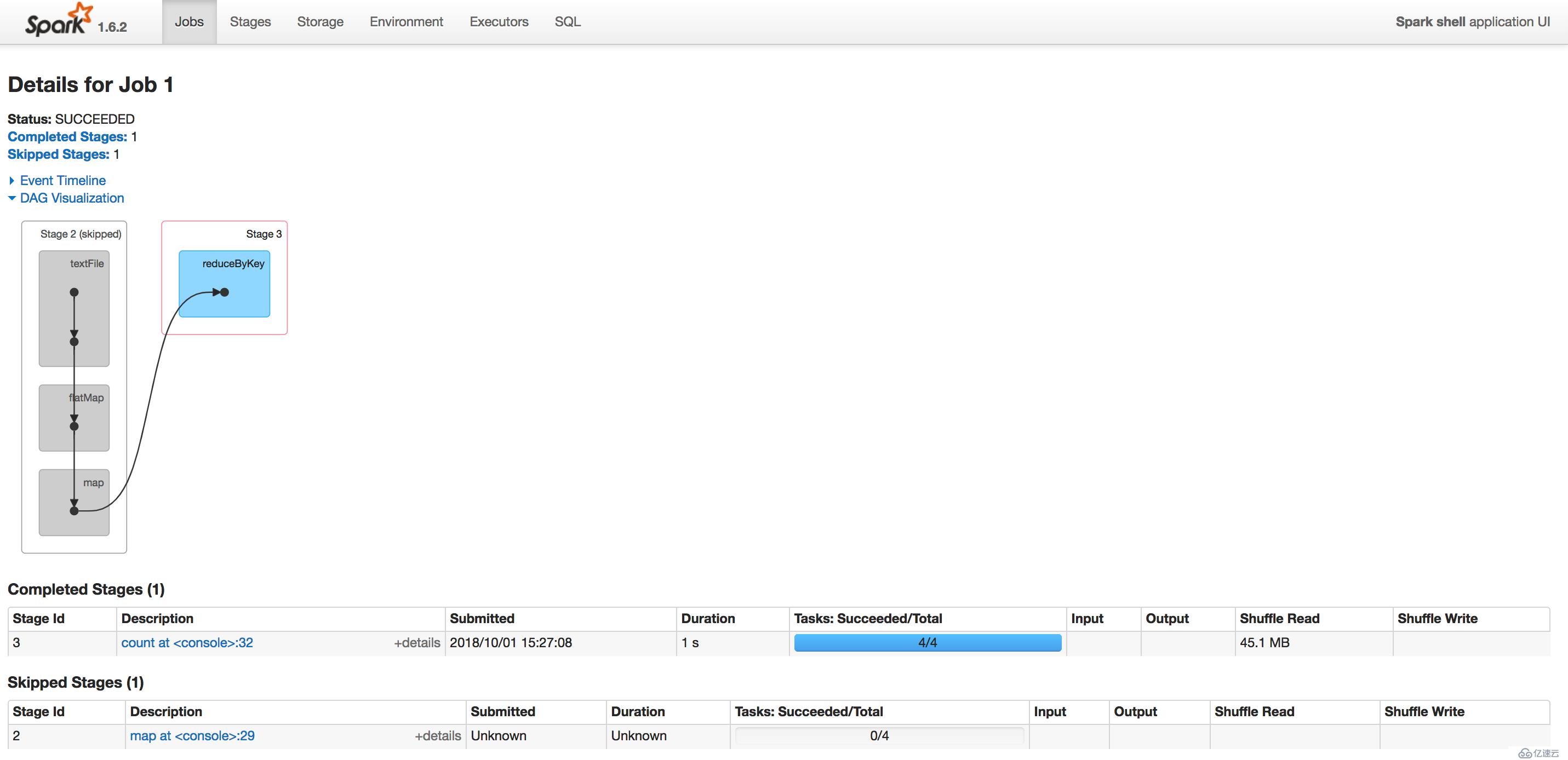
可以看到这与前面执行RDD缓存操作之后是一样的,是因为在linestage中,最后一个RDD即便不显示执行RDD缓存的操作,那么它也会保存在内存当中,当然,比如这里的retRDD再执行了一次transformation操作,那么当执行action操作之后`retRDD就不会被缓存下来了,经过迭代式计算之后,它转化为下一个RDD;然而如果是显式缓存了retRDD的操作,在storage界面可以看到它,不管它后面再执行怎么样的操作,retRDD还是会存在内存当中,这就是主动缓存RDD跟非主动缓存RDD的最大区别。
有很多细节的东西这里是没有办法展示的,这需要进一步去实践操作,如果可以,阅读源码也是十分不错的选择,当然这里也提供了十分不错的验证方式,通过这样一个操作的过程,相信会比在抽象概念上去理解RDD持久化会有更大的提升。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



