这篇文章给大家分享的是有关HBase中BloomFilter是什么的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
先简单的介绍下Bloom Filter(布隆过滤器)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
在计算机科学中,我们常常会碰到时间换空间或者空间换时间的情况,即为了达到某一个方面的最优而牺牲另一个方面。Bloom Filter在时间空间这两个因素之外又引入了另一个因素:错误率。在使用Bloom Filter判断一个元素是否属于某个集合时,会有一定的错误率。也就是说,有可能把不属于这个集合的元素误认为属于这个集合(False Positive),但不会把属于这个集合的元素误认为不属于这个集合(False Negative)。在增加了错误率这个因素之后,Bloom Filter通过允许少量的错误来节省大量的存储空间。简单地说就是宁可放过也不杀错。
它的用法其实是很容易理解的,我们拿个HBase中应用的例子来说下,我们已经知道rowKey存放在HFile中,那么为了从一系列的HFile中查询某个rowkey,我们就可以通过 Bloom Filter 快速判断 rowkey 是否在这个HFile中,从而过滤掉大部分的HFile,减少需要扫描的Block。
BloomFilter对于HBase的随机读性能至关重要,对于get操作以及部分scan操作可以剔除掉不会用到的HFile文件,减少实际IO次数,提高随机读性能。在此简单地介绍一下Bloom Filter的工作原理,Bloom Filter使用位数组来实现过滤,初始状态下位数组每一位都为0,如下图所示:

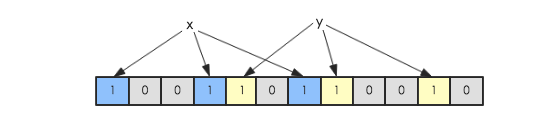
假如此时有一个集合S = {x1, x2, … xn},Bloom Filter使用k个独立的hash函数,分别将集合中的每一个元素映射到{1,…,m}的范围。对于任何一个元素,被映射到的数字作为对应的位数组的索引,该位会被置为1。比如元素x1被hash函数映射到数字8,那么位数组的第8位就会被置为1。下图中集合S只有两个元素x和y,分别被3个hash函数进行映射,映射到的位置分别为(0,3,6)和(4,7,10),对应的位会被置为1:
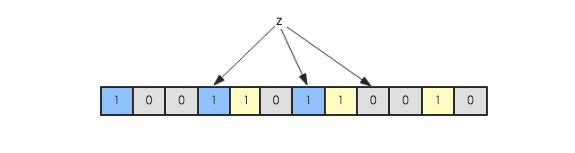
现在假如要判断另一个元素是否是在此集合中,只需要被这3个hash函数进行映射,查看对应的位置是否有0存在,如果有的话,表示此元素肯定不存在于这个集合,否则有可能存在。下图所示就表示z肯定不在集合{x,y}中:
从上面的内容我们可以得知,Bloom Filter有两个很重要的参数
哈希函数个数
位数组的大小
我们来理一下 HFile 中和 Bloom Filter 相关的Block,
Scanned Block Section(扫描HFile时被读取):Bloom Block
Load-on-open-section(regionServer启动时加载到内存):BloomFilter Meta Block、Bloom Index Block
Bloom Block:Bloom数据块,存储Bloom的位数组
Bloom Index Block:Bloom数据块的索引
BloomFilter Meta Block:从HFile角度看bloom数据块的一些元数据信息,大小个数等等。
HBase中每个HFile都有对应的位数组,KeyValue在写入HFile时会先经过几个hash函数的映射,映射后将对应的数组位改为1,get请求进来之后再进行hash映射,如果在对应数组位上存在0,说明该get请求查询的数据不在该HFile中。
HFile中的Bloom Block中存储的就是上面说得位数组,当HFile很大时,Data Block 就会很多,同时KeyValue也会很多,需要映射入位数组的rowKey也会很多,所以为了保证准确率,位数组就会相应越大,那Bloom Block也会越大,为了解决这个问题就出现了Bloom Index Block,作用和 Data Index Block 类似,一个HFile中有多个Bloom Block(位数组),根据rowKey拆分,一部分连续的Key使用一个位数组。这样查询rowKey就要先经过Bloom Index Block(在内存中)定位到Bloom Block,再把Bloom Block加载到内存,进行过滤。
谓词下推
1.Bloom Filter 在小表处生成;
2.广播到大表处;
3.大表根据 Bloom Filter 进行过滤;
4.剩下的数据传入 JoinNode 进行关联。
注意:Bloom Filter 处理 join 并不是总是有效地,如果JOIN两边的表并不能过滤到很多数据,例如左表和右表中Join键的差集并不大,这种情况下反而浪费了资源计算Bloom Filter和应用Bloom Filter
Google Guava library为我们提供了Bloom Filter的实现,直接用就可以啦:com.google.common.hash.BloomFilter
private final BloomFilter<String> bloomFilter = BloomFilter.create(new Funnel<String>() { private static final long serialVersionUID = 1L; @Override public void funnel(String arg0, PrimitiveSink arg1) { arg1.putString(arg0, Charsets.UTF_8); } }, 1024*1024*32);public synchronized boolean contains(String id){ if(StringUtils.isEmpty(id)){ return true; } boolean exists = bloomFilter.mightContain(id); //布隆过滤器是否包含这个id if(!exists){ bloomFilter.put(id); //添加进布隆过滤器 } return exists; }感谢各位的阅读!关于“HBase中BloomFilter是什么”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/3972754/blog/4453557



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



