小编给大家分享一下python中pandas_profiling怎么用,希望大家阅读完这篇文章之后都有所收获,下面让我们一起去探讨吧!
分析报告全貌
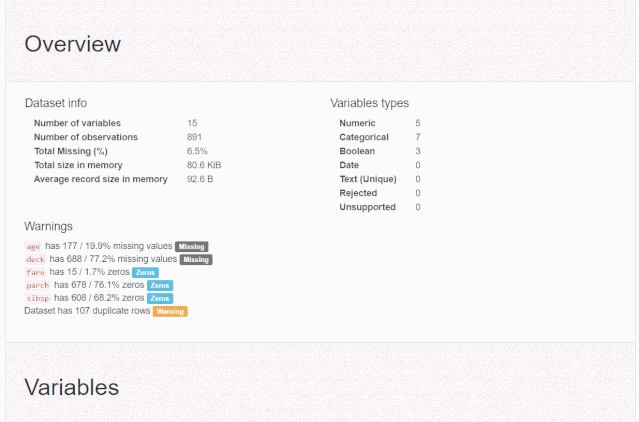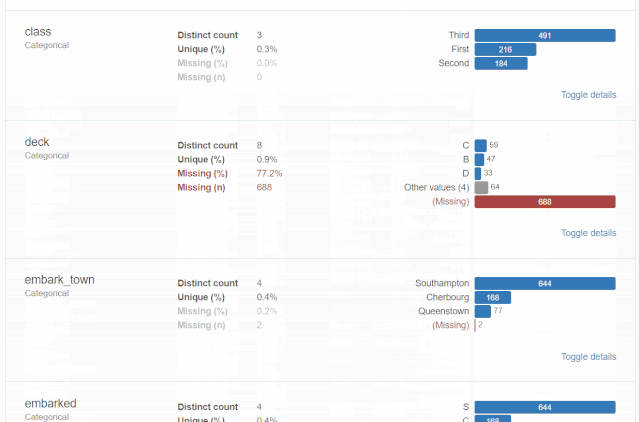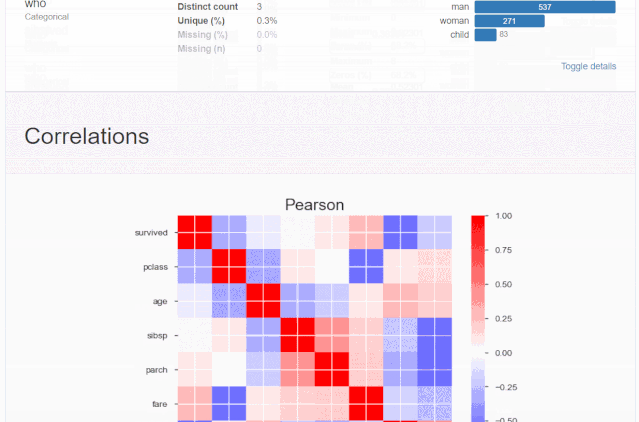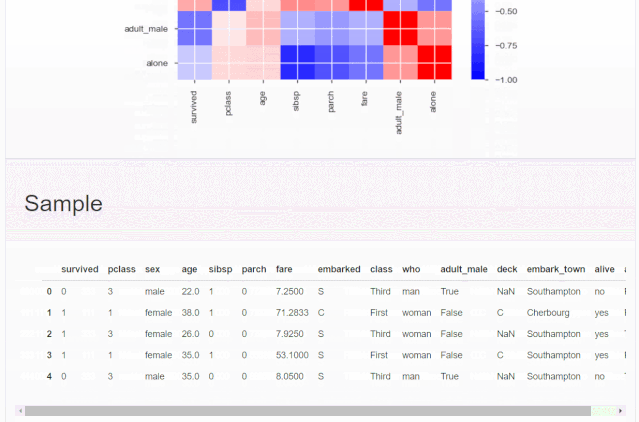
什么是探索性数据分析
熟悉pandas的童鞋估计都知道pandas的describe()和info()函数,用来查看数据的整体情况,比如平均值、标准差之类,就是所谓的探索性数据分析-EDA。
pandas_profiling简介
如果你想更方便快捷地了解数据的全貌,泣血推荐一个python库:pandas_profiling,这个库只需要一行代码就可以生成数据EDA报告。
pandas_profiling基于pandas的DataFrame数据类型,可以简单快速地进行探索性数据分析。
对于数据集的每一列,pandas_profiling会提供以下统计信息:
1、概要:数据类型,唯一值,缺失值,内存大小
2、分位数统计:最小值、最大值、中位数、Q1、Q3、最大值,值域,四分位
3、描述性统计:均值、众数、标准差、绝对中位差、变异系数、峰值、偏度系数
4、最频繁出现的值,直方图/柱状图
5、相关性分析可视化:突出强相关的变量,Spearman, Pearson矩阵相关性色阶图
并且这个报告可以导出为HTML,非常方便查看。
pandas_profiling安装
安装pandas_profiling可以使用pip、conda或者下载文件安装,非常方便。
我这里使用pip方式,在命令行输入:
pip install pandas-profiling
本文在Jupyter notebook中进行代码实验。
pandas_profiling使用方法
1、加载数据集
我这里用经典的泰坦尼克数据集:
# 导入相关库import seaborn as snsimport pandas as pdimport pandas_profiling as ppimport matplotlib.pyplot as plt# 加载泰坦尼克数据集data = sns.load_dataset('titanic')data.head()输出:

2、使用pandas_profiling生成数据探索报告
report = pp.ProfileReport(data)report输出报告:
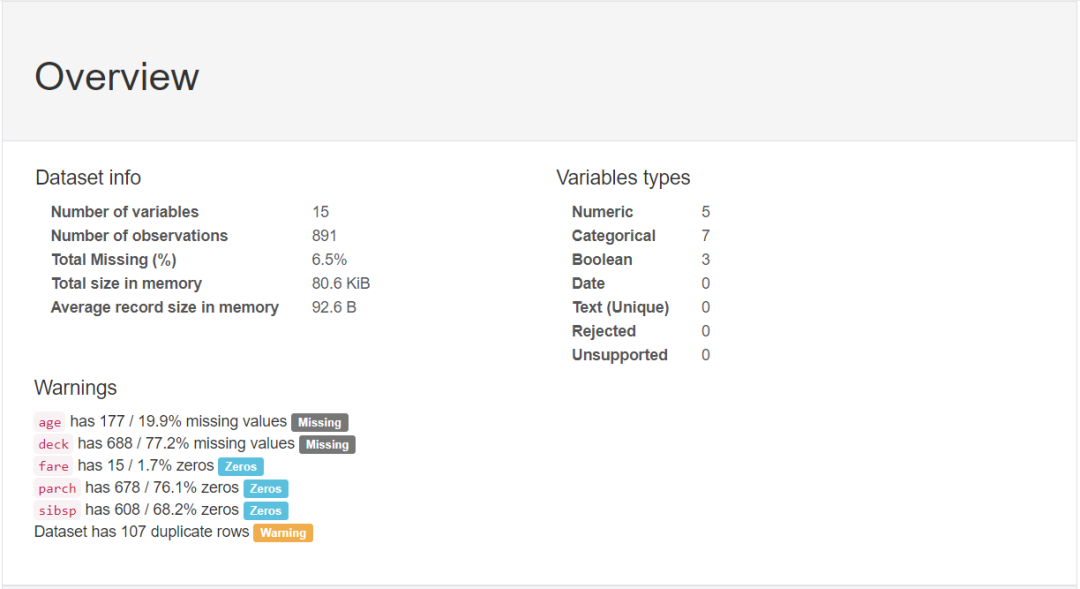
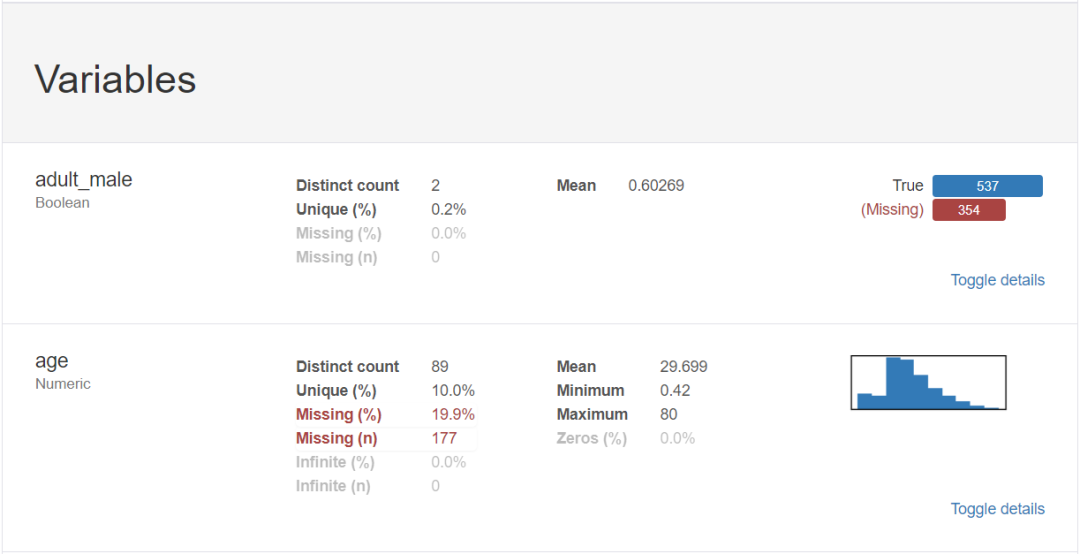
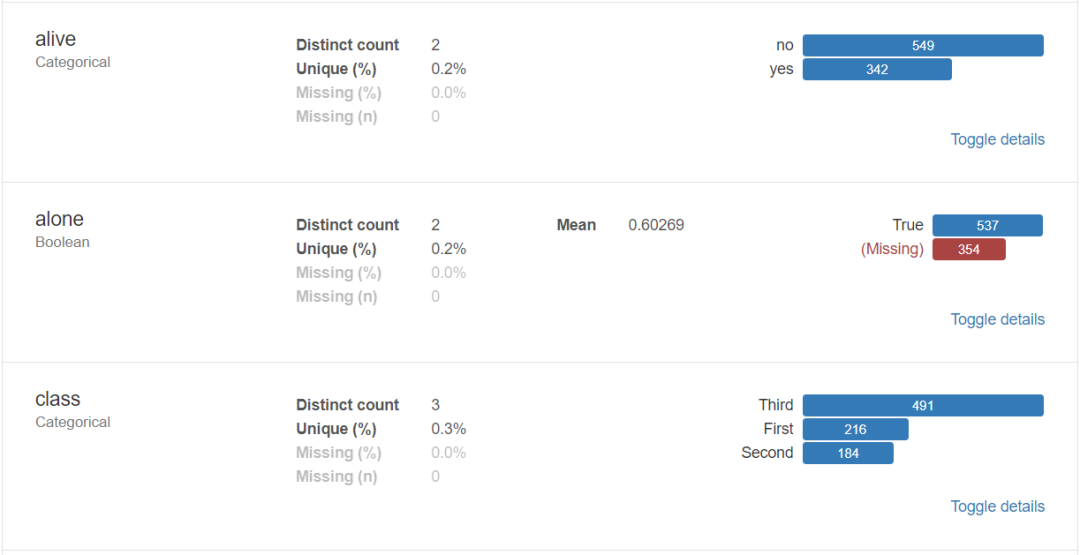
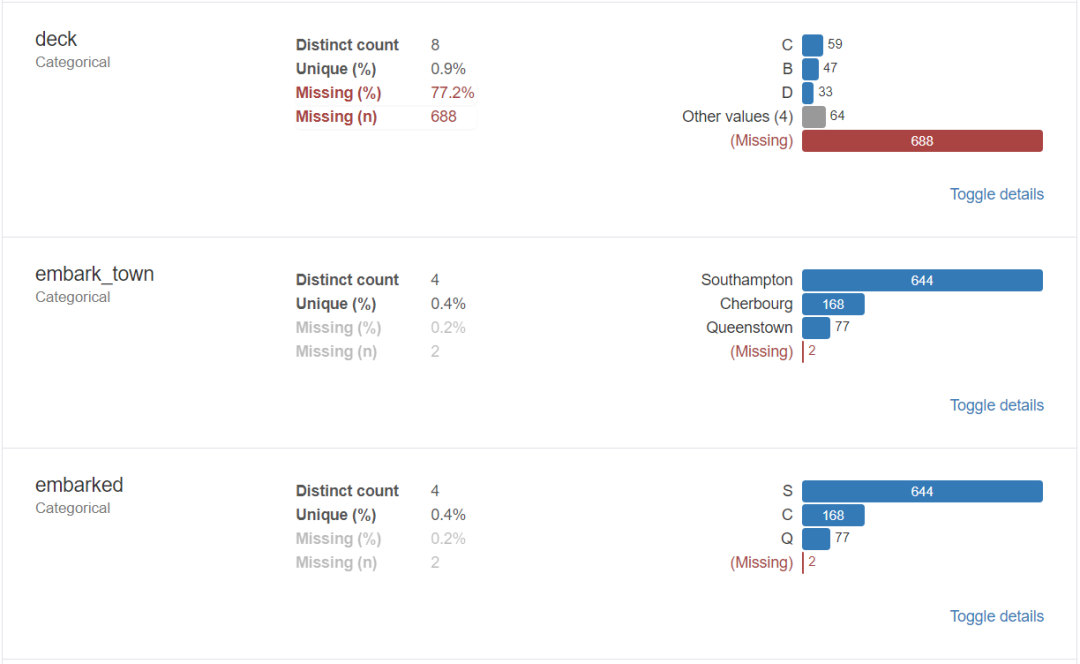
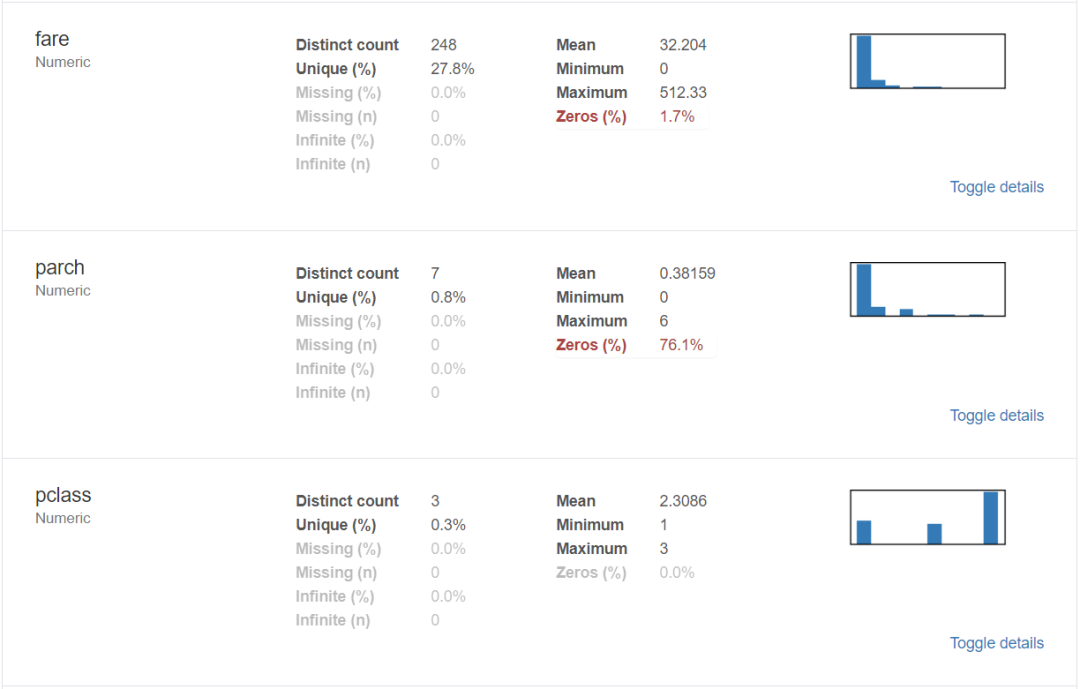
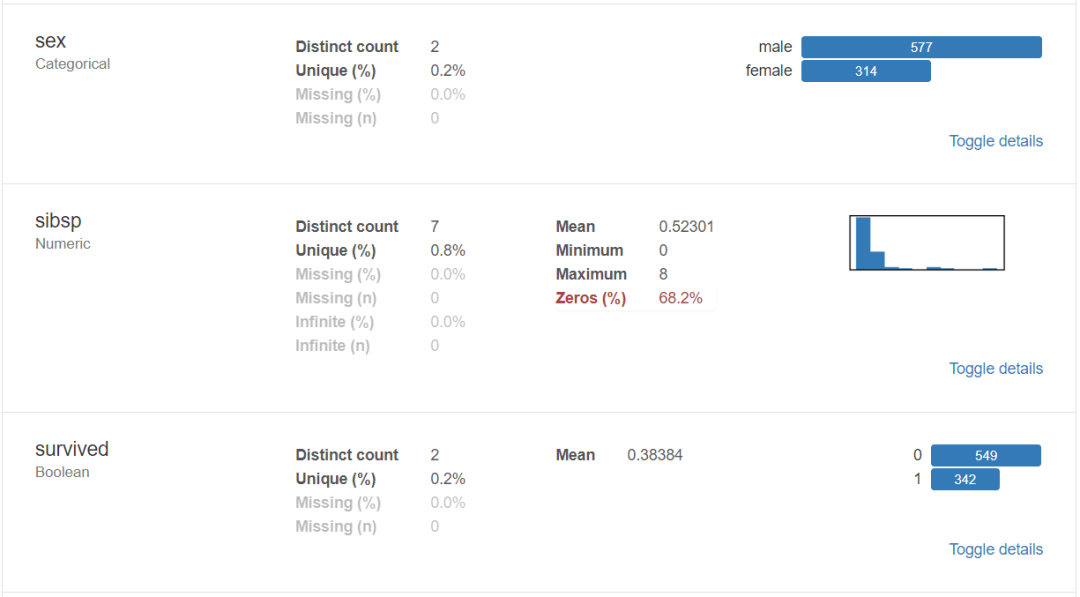


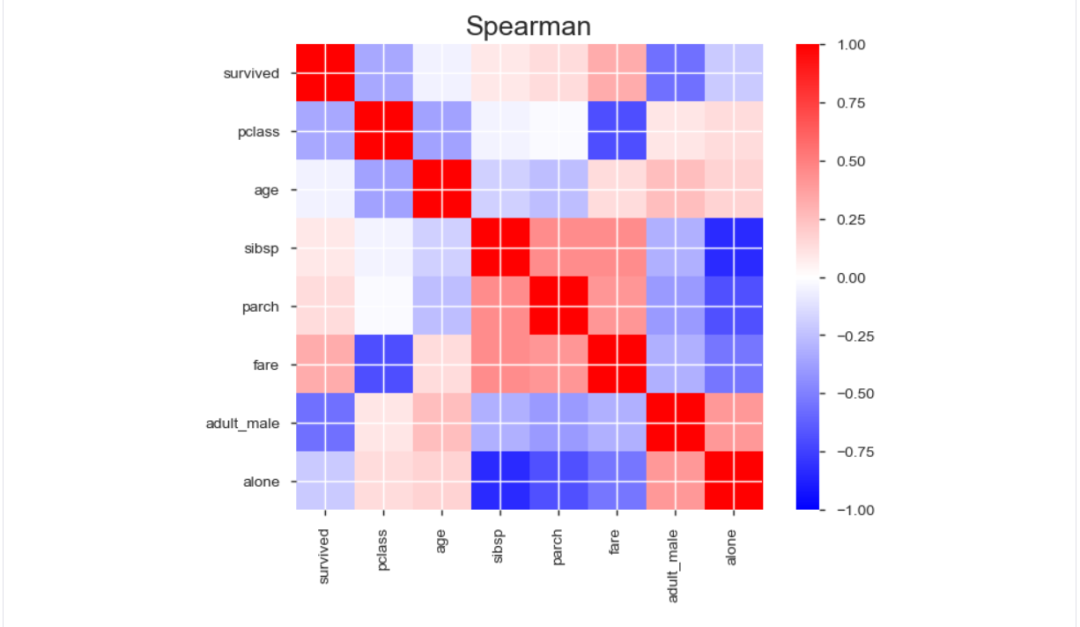
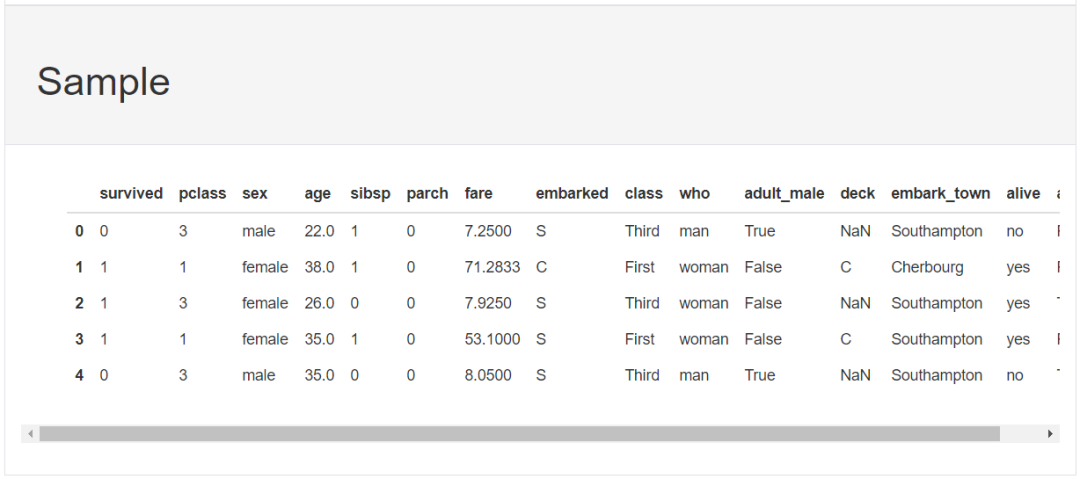
3、导出为html文件
report.to_file('report.html')看完了这篇文章,相信你对“python中pandas_profiling怎么用”有了一定的了解,如果想了解更多相关知识,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/freeshow/blog/4441267



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



