本篇文章给大家分享的是有关大数据中常用的无监督异常检测算法技术有哪些,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
下面将介绍关于异常检测类的文章,主要介绍了几种无监督异常检测方法,实验部分仅供参考。
在仙侠剧中,有正魔之分,然何为正道,何为魔道,实属难辨。自称正道的人也许某一天会堕入魔道,被众人称为魔头的人,或许内心自始至终都充溢着正义感!所以说,没有绝对的黑,也没有绝对的白。
话说回来,对于“异常”这个词,每个人的心里大概都有一个衡量标准,扩展起来的确很广(如异常点、异常交易、异常行为、异常用户、异常事故等等),那么究竟何为异常呢?
异常是相对于其他观测数据而言有明显偏离的,以至于怀疑它与正常点不属于同一个数据分布。异常检测是一种用于识别不符合预期行为的异常模式的技术,又称之为异常值检测。
在商业中也有许多应用,如网络入侵检测(识别可能发出黑客攻击的网络流量中的特殊模式)、系统健康性监测、信用卡交易欺诈检测、设备故障检测、风险识别等。这里,将异常分为三种:
数据点异常:如果样本点与其他数据相距太远,则单个数据实例是异常的。业务用例:根据“支出金额”检测信用卡欺诈。
上下文异常:在时间序列数据中的异常行为。业务用例:旅游购物期间信用卡的花费比平时高出好多倍属于正常情况,但如果是被盗刷卡,则属于异常。
集合异常:单个数据难以区分,只能根据一组数据来确定行为是否异常。业务用例:蚂蚁搬家式的拷贝文件,这种异常通常属于潜在的网络攻击行为。
异常检测类似于噪声消除和新颖性检测。噪声消除(NR)是从不需要的观察发生中免疫分析的过程; 换句话说,从其他有意义的信号中去除噪声。新颖性检测涉及在未包含在训练数据中的新观察中识别未观察到的模式。
在面对真实的业务场景时,我们往往都是满腹激情、豪情壮志,心里默念着终于可以进入实操,干一番大事业了。然而事情往往都不是那么美好,业务通常比较特殊、背景复杂,对于业务的熟悉过程也会耗掉你大部分的时间。然后在你绞尽脑汁将其转化为异常检测场景后,通常又面临着以下几大挑战:
不能明确定义何为正常,何为异常,在某些领域正常和异常并没有明确的界限;
数据本身存在噪声,致使噪声和异常难以区分;
正常行为并不是一成不变,也会随着时间演化,如正常用户被盗号之后,进行一系列的非法操作;
标记数据获取难:没有数据,再好的算法也是无用。
针对上述挑战,下面我们来看看具体的场景和用于异常检测的算法。
这里将基于统计的作为一类异常检测技术,方法比如多,下面主要介绍MA和3-Sigma。
识别数据不规则性的最简单的方法是标记偏离分布的数据点,包括平均值、中值、分位数和模式。假定异常数据点是偏离平均值的某个标准偏差,那么我们可以计算时间序列数据滑动窗口下的局部平均值,通过平均值来确定偏离程度。这被技术称为滑动平均法(moving average,MA),旨在平滑短期波动并突出长期波动。滑动平均还包括累加移动平均、加权移动平均、指数加权移动平均、双指数平滑、三指数平滑等,在数学上,
缺点:
数据中可能存在与异常行为类似的噪声数据,所以正常行为和异常行为之间的界限通常不明显;
异常或正常的定义可能经常发生变化,因为恶意攻击者不断适应自己。因此,基于移动平均值的阈值可能并不总是适用。
3-Sigma原则又称为拉依达准则,该准则定义如下:
假设一组检测数据只含有随机误差,对原始数据进行计算处理得到标准差,然后按一定的概率确定一个区间,认为误差超过这个区间的就属于异常值。
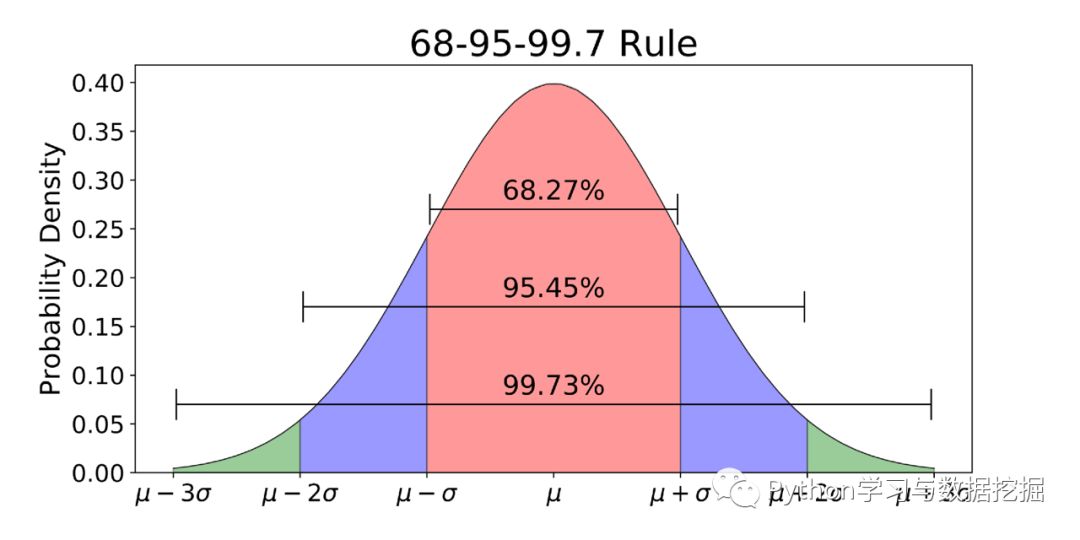
使用3-Sigma的前提是数据服从正态分布,当然如果x不服从正态分布可以使用log将其转为正态分布。下面是3-Sigma的Python实现。
#3-sigma识别异常值def three_sigma(df_col): ''' df_col:DataFrame数据的某一列 ''' rule = (df_col.mean() - 3 * df_col.std() > df_col) | (df_col.mean() + 3 * df_col.std() < df_col) index = np.arange(df_col.shape[0])[rule] outrange = df_col.iloc[index] return outrange对于异常值检测出来的结果,有多种处理方式,如果是时间序列中的值,那么我们可以认为这个时刻的操作属于异常的;如果是将异常值检测用于数据预处理阶段,处理方法有以下四种:
删除带有异常值的数据;
将异常值视为缺失值,交给缺失值处理方法来处理;
用平均值进行修正;
当然我们也可以选择不处理。
基于密度的异常检测有一个先决条件,即正常的数据点呈现“物以类聚”的聚合形态,正常数据出现在密集的邻域周围,而异常点偏离较远。对于这种场景,我们可以计算得分来评估最近的数据点集,这种得分可以使用Eucledian距离或其它的距离计算方法,具体情况需要根据数据类型来定:类别型或是数字型。
iForest(isolation forest,孤立森林)算法是一种基于Ensemble的快速异常检测方法,具有线性时间复杂度和高精准度,该算法是刘飞博士在莫纳什大学就读期间由陈开明(Kai-Ming Ting)教授和周志华(Zhi-Hua Zhou)教授指导发表的,与LOF、OneClassSVM相比,其占用的内存更小、速度更快。算法原理如下:

算法部分的代码如下:
classifiers = {"Isolation Forest":IsolationForest(n_estimators=100, max_samples=len(X), contamination=0.005,random_state=state, verbose=0)}def train_model(clf, train_X): #Fit the train data and find outliers clf.fit(X) #scores_prediction = clf.decision_function(X) y_pred = clf.predict(X) return y_pred, clfy_pred,clf = train_model(clf=classifiers["Isolation Forest"], train_X=X)以上就是大数据中常用的无监督异常检测算法技术有哪些,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4593030/blog/4419108



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



