如何正确的使用Annovar,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
annovar的下载及安装
Annovar是用perl语言写的,可以在任何安装了perl的系统上运行,且不需要进行安装,直接下载解压就可以使用。但它的下载需要注册,且需要使用教育机构或者科研单位后缀的邮箱。当然,如果你没有注册邮箱也没有关系,后台回复annovar即可得到软件安装包。Annovar主要有三种不同形式的注释方式:
1、Gene-based annotation:根据SNP或者CNV的位置来判断是否会引起蛋白质编码的变化,是否发生了氨基酸的改变。
2、 Region-based annotation: 来鉴定特定基因组区域的突变。
3、Filter-based annotation:用来鉴定特定数据库中的突变。下载完annovar并且解压之后,主要包括以下文件:
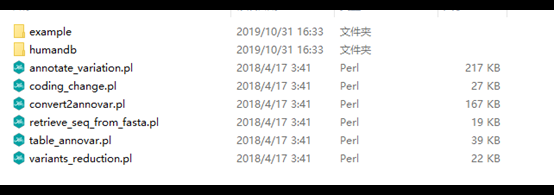
example:存放的是示例文件
humandb:部分注释数据库的文件,annovar的软件中自带了一部分,根据自己的研究需要也可以自己下载
annotate_variation.pl:主程序,用来进行数据库的下载,以及不同形式的注释
coding_change.pl:用来推断蛋白质的序列是否发生变化
convert2annovar.pl:将其他多种形式转化为annovar可识别的形式(如将vcf文件转化为annovar可识别形式)
retrieve_seq_from_fasta.pl:自行建立其它物种的转录本
table_annovar.pl:可以一次完成三种不同形式的注释
variants_reduction.pl:用来定制过滤注释流程
— 输入文件 —
Annovar的输入文件是一个简单的文本格式文件,其中前五列应分别是染色体号、突变位点在染色体上的起始位置、突变位点的结束位置、该突变位点在参考序列上的碱基以及该位点的突变碱基,其他列的内容可以有也可以没有。
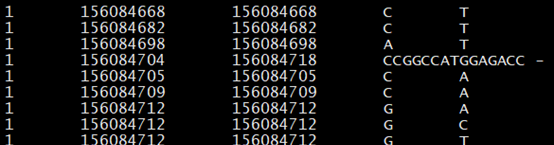
如果输入文件是vcf文件,可以采用annovar的convert2annovar.pl程序将vcf文件转化为annovar可识别的文件形式,具体的命令如下:
perl convert2annovar.pl -format vcf4 G-001.vcf -outfile G.avinput
输出文件的格式为:
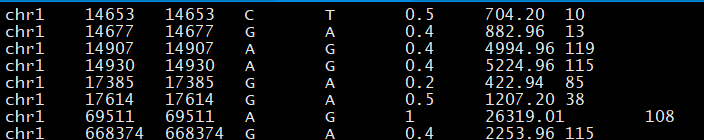
— 数据库下载 —
Annovar的注释主要依赖于数据库,因此在进行分析之前,应将所需的数据库下载到humandb文件夹中,下载的命令如下:
perl annotate_variation.pl -buildver hg19 -downdb -webfrom annovar avsnp147 humandb/
-buildver:对应参考基因组的版本
-downdb –webfrom annovar:从annovar库中下载对应的数据库,如果不知道要下载什么数据库,可以在annovar库中查看对应的数据库以及对应的功能,网址为:(http://annovar.openbioinformatics.org/en/latest/user-guide/download/)
avsnp147:下载的数据库的名称
humandb:下载到humandb文件夹中
— 结果注释—
整理好输入文件格式以及下载好数据库后,就可以进行注释了,下面以table_annovar.pl为例介绍下annovar的注释功能,具体命令如下:
perl table_annovar.pl GCK.avinput annovar/humandb/ -buildver hg19 -out GCK -remove –protocol refGene,1000g2015aug_eas,1000g2015aug_eur,1000g2015aug_sas,1000g2015aug_amr -operation g,f,f,f ,f -nastring .
table_annovar.pl:输入文件
-buildver:参考序列版本
-out:输出文件
-remove:删掉程d序运行过程中产生的中间文件
–protocol:数据库的名称
-operation:对应顺序的数据库的类型,如千人基因组,dbsnp数据库等(g代表gene-based、r代表region-based、f代表filter-based),与前面数据库一一对应
-nastring .:缺省值用.表示
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4592469/blog/4439364



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



