这篇文章主要介绍了python模型的评估实例分析的相关知识,内容详细易懂,操作简单快捷,具有一定借鉴价值,相信大家阅读完这篇python模型的评估实例分析文章都会有所收获,下面我们一起来看看吧。
除了使用estimator的score函数简单粗略地评估模型的质量之外,
在sklearn.metrics模块针对不同的问题类型提供了各种评估指标并且可以创建用户自定义的评估指标,
使用model_selection模块中的交叉验证相关方法可以评估模型的泛化能力,能够有效避免过度拟合。
一,metrics评估指标概述
sklearn.metrics中的评估指标有两类:以_score结尾的为某种得分,越大越好,
以_error或_loss结尾的为某种偏差,越小越好。
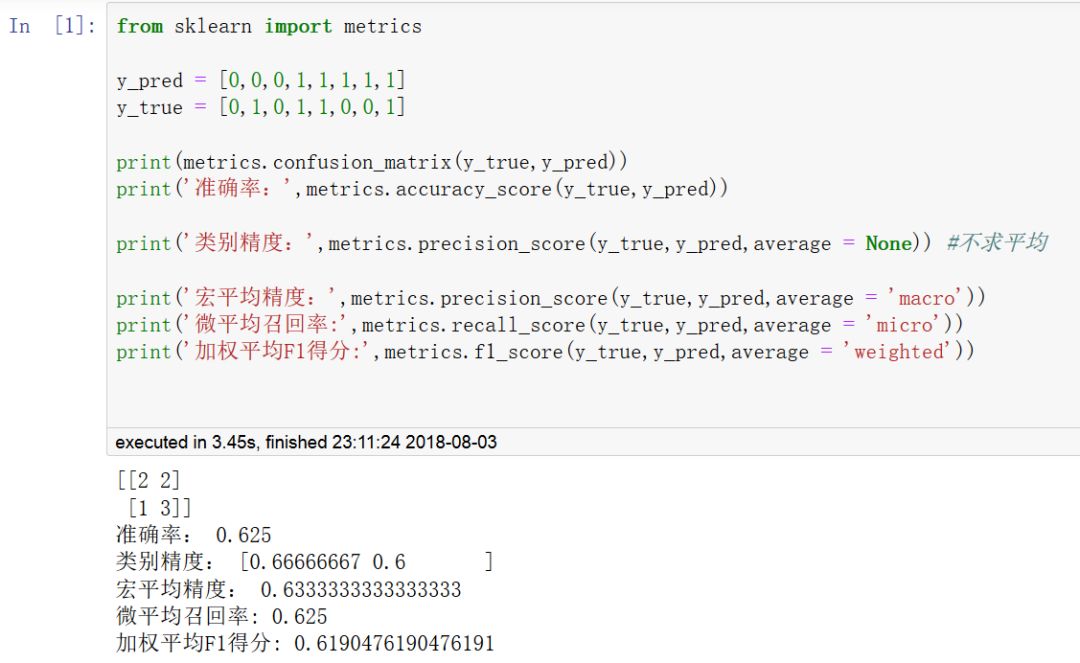
常用的分类评估指标包括:accuracy_score,f1_score,
precision_score,recall_score等等。
常用的回归评估指标包括:r2_score,explained_variance_score等等。
常用的聚类评估指标包括:adjusted_rand_score,adjusted_mutual_info_score等等。
二,分类模型的评估
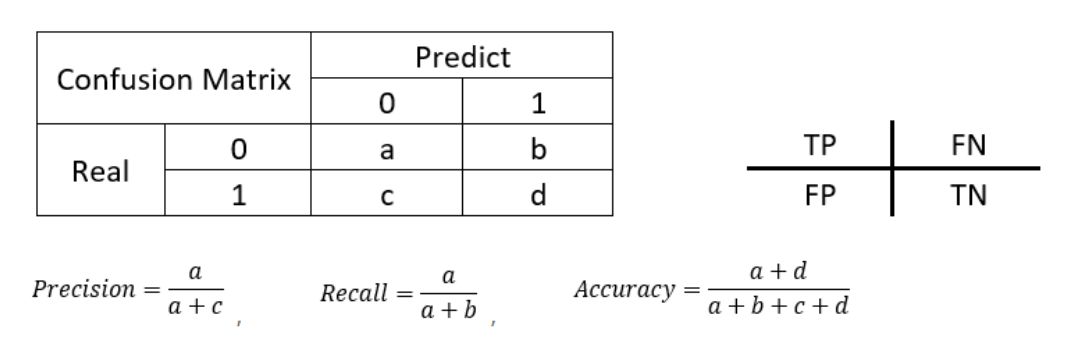
模型分类效果全部信息:
confusion_matrix 混淆矩阵,误差矩阵。

模型整体分类效果:
accuracy 正确率。通用分类评估指标。
模型对某种类别的分类效果:
precision 精确率,也叫查准率。模型不把正样本标错的能力。“不冤枉一个好人”。
recall 召回率,也叫查全率。模型识别出全部正样本的能力。“也绝不放过一个坏人”。
f1_score F1得分。精确率和召回率的调和平均值。
利用不同方式将类别分类效果进行求和平均得到整体分类效果:
macro_averaged:宏平均。每种类别预测的效果一样重要。
micro_averaged:微平均。每一次分类预测的效果一样重要。
weighted_averaged:加权平均。每种类别预测的效果跟按该类别样本出现的频率成正比。
sampled_averaged: 样本平均。仅适用于多标签分类问题。根据每个样本多个标签的预测值和真实值计算评测指标。然后对样本求平均。
仅仅适用于概率模型,且问题为二分类问题的评估方法:
ROC曲线
auc_score
三,回归模型的评估
回归模型最常用的评估指标有:
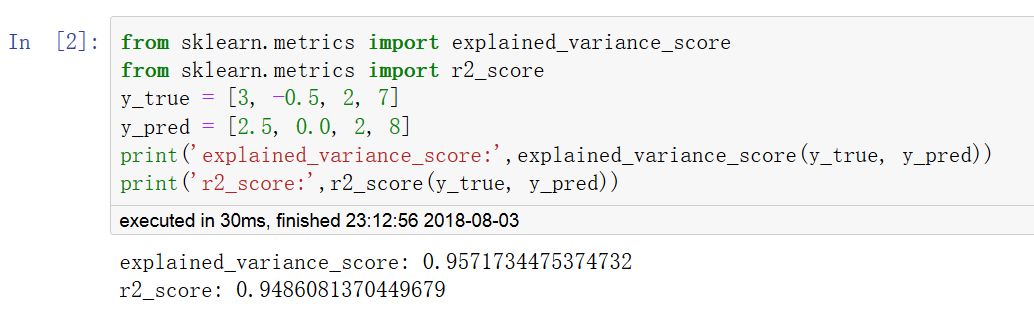
r2_score(r方,拟合优度,可决系数)
explained_variance_score(解释方差得分)
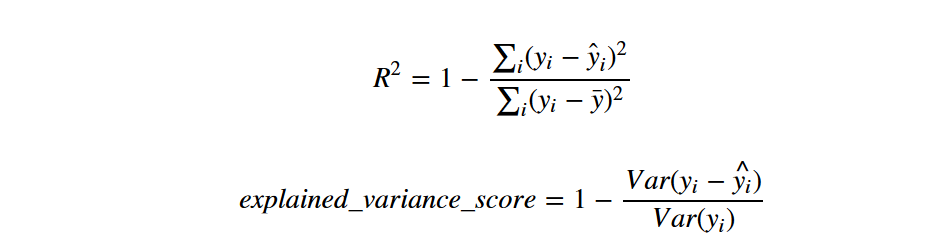
四,使用虚拟估计器产生基准得分
对于监督学习(分类和回归),可以用一些基于经验的简单估计策略(虚拟估计)的得分作为参照基准值。
DummyClassifier 实现了几种简单的分类策略:
stratified 通过在训练集类分布方面来生成随机预测.
most_frequent 总是预测训练集中最常见的标签.
prior 类似most_frequenct,但具有precit_proba方法
uniform 随机产生预测.
constant 总是预测用户提供的常量标签.
DummyRegressor 实现了四个简单的经验法则来进行回归:
mean 总是预测训练目标的平均值.
median 总是预测训练目标的中位数.
quantile 总是预测用户提供的训练目标的 quantile(分位数).
constant 总是预测由用户提供的常数值.
在机器学习问题中,经常会出现模型在训练数据上的得分很高,
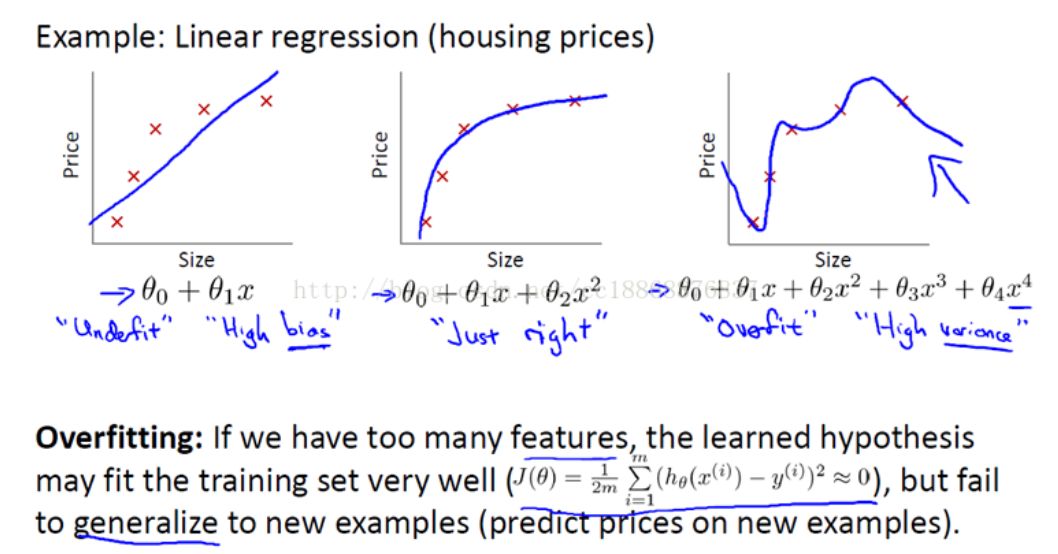
但是在新的数据上表现很差的情况,这称之为过拟合overfitting,又叫高方差high variance。
而如果在训练数据上得分就很低,这称之为欠拟合underfitting,又叫高偏差high bias。
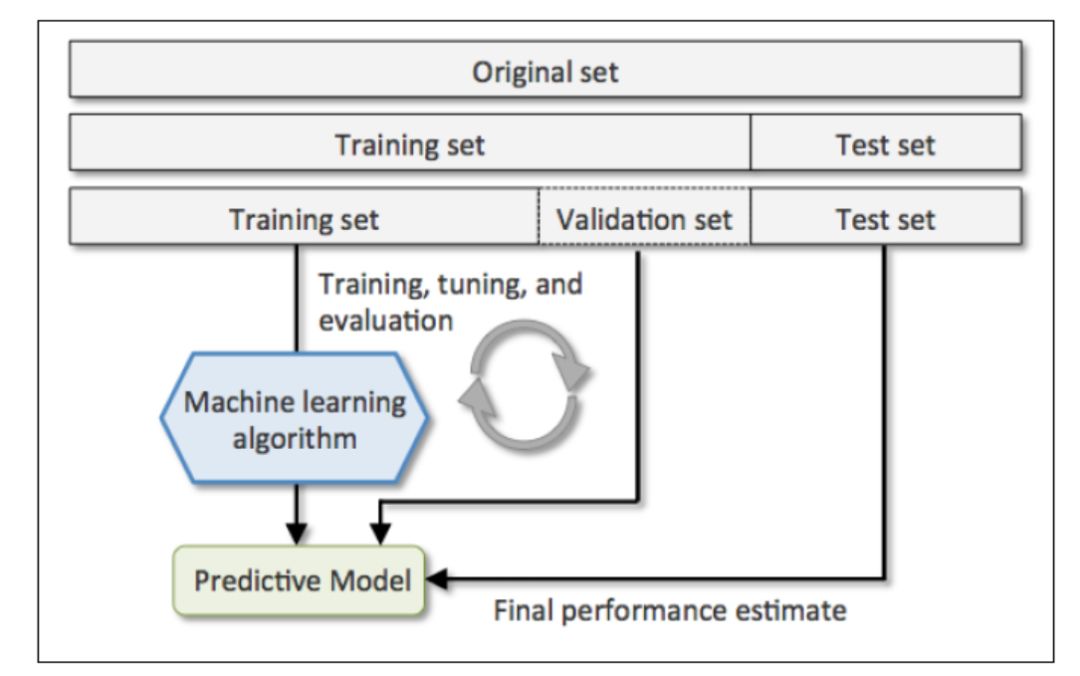
留出法
为了解决过拟合问题,常见的方法将数据分为训练集和测试集,用训练集去训练模型的参数,用测试集去测试训练后模型的表现。有时对于一些具有超参数的模型(例如svm.SVC的参数C和kernel就属于超参数),还需要从训练集中划出一部分数据去验证超参数的有效性。
交叉验证法
在数据数量有限时,按留出法将数据分成3部分将会严重影响到模型训练的效果。为了有效利用有限的数据,可以采用交叉验证cross_validation方法。
交叉验证的基本思想是:以不同的方式多次将数据集划分成训练集和测试集,分别训练和测试,再综合最后的测试得分。每个数据在一些划分情况下属于训练集,在另外一些划分情况下属于测试集。
简单的2折交叉验证:把数据集平均划分成A,B两组,先用A组训练B组测试,再用B组训练A组测试,所以叫做交叉验证。
常用的交叉验证方法:K折(KFold),留一交叉验证(LeaveOneOut,LOO),留P交叉验证(LeavePOut,LPO),重复K折交叉验证(RepeatedKFold),随机排列交叉验证(ShuffleSplit)。
此外,为了保证训练集中每种标签类别数据的分布和完整数据集中的分布一致,可以采用分层交叉验证方法(StratifiedKFold,StratifiedShuffleSplit)。
当数据集的来源有不同的分组时,独立同分布假设(independent identical distributed:i.i.d)将被打破,可以使用分组交叉验证方法保证训练集的数据来自各个分组的比例和完整数据集一致。(GroupKFold,LeaveOneGroupOut,LeavePGroupsOut,GroupShuffleSplit)
对于时间序列数据,一个非常重要的特点是时间相邻的观测之间的相关性(自相关性),因此用过去的数据训练而用未来的数据测试非常重要。TimeSeriesSplit可以实现这样的分割。
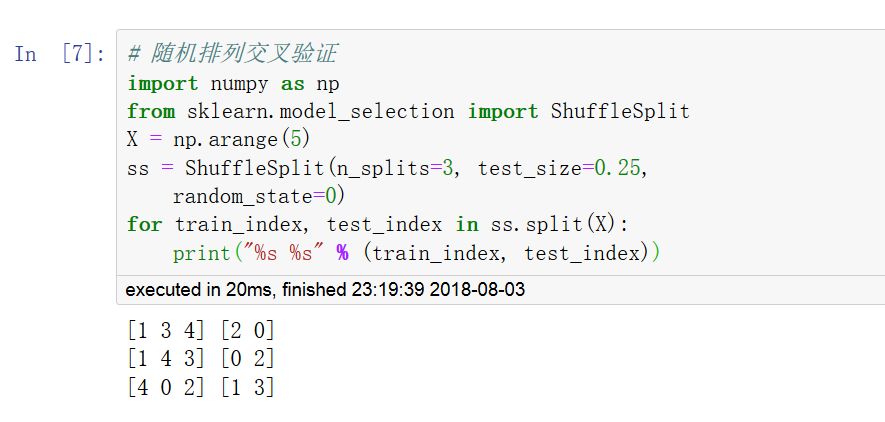
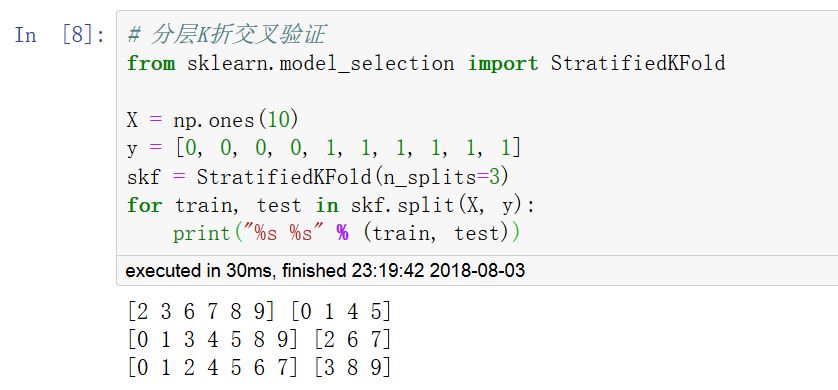
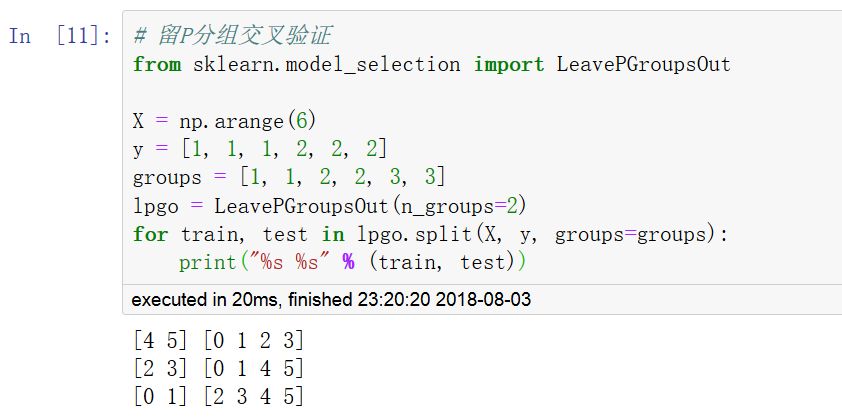
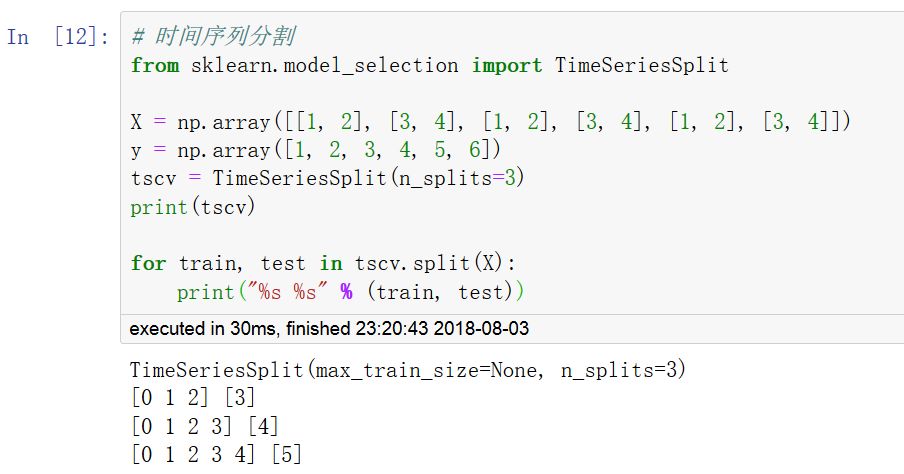
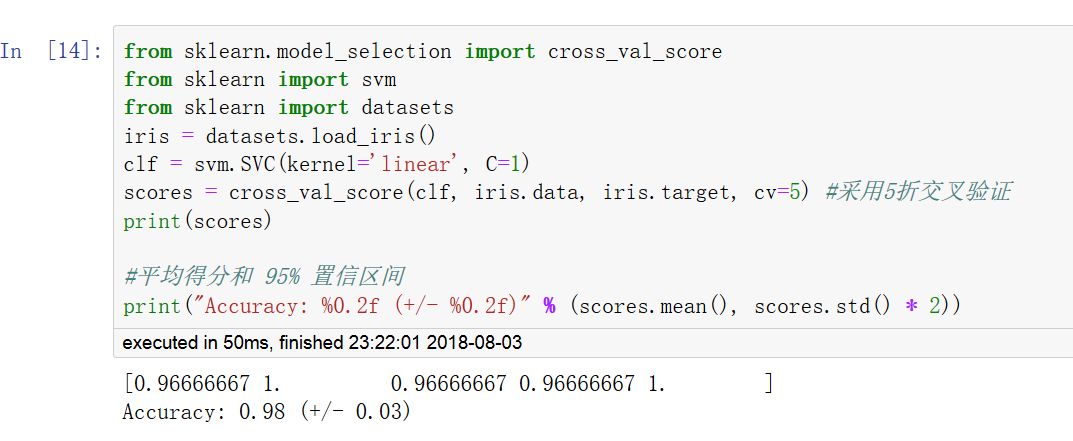
调用 cross_val_score 函数可以计算模型在各交叉验证数据集上的得分。
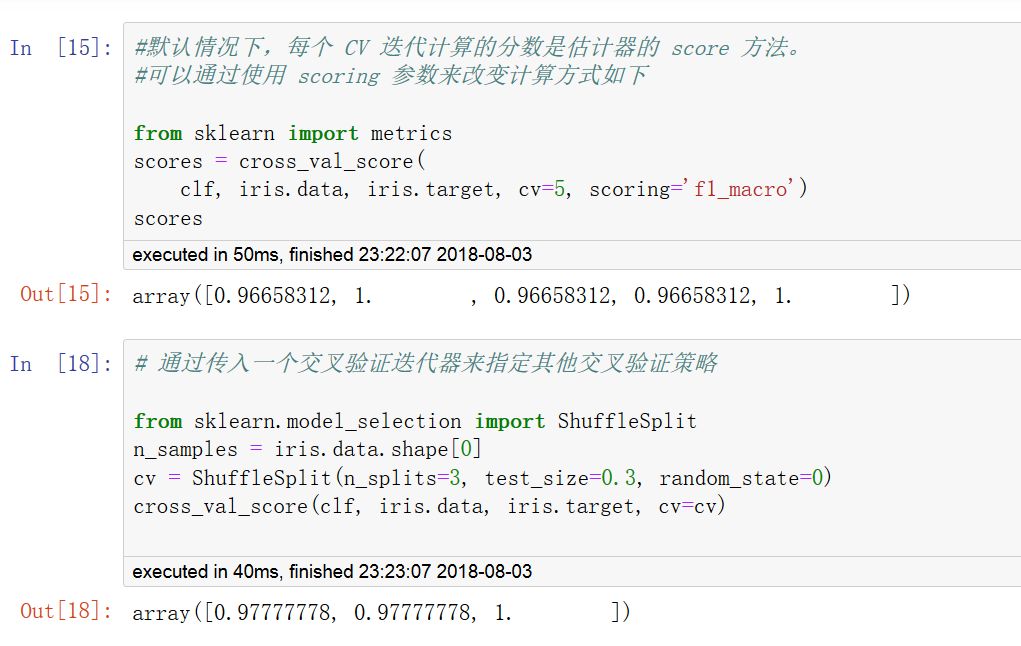
可以指定metrics中的打分函数,也可以指定交叉验证迭代器。
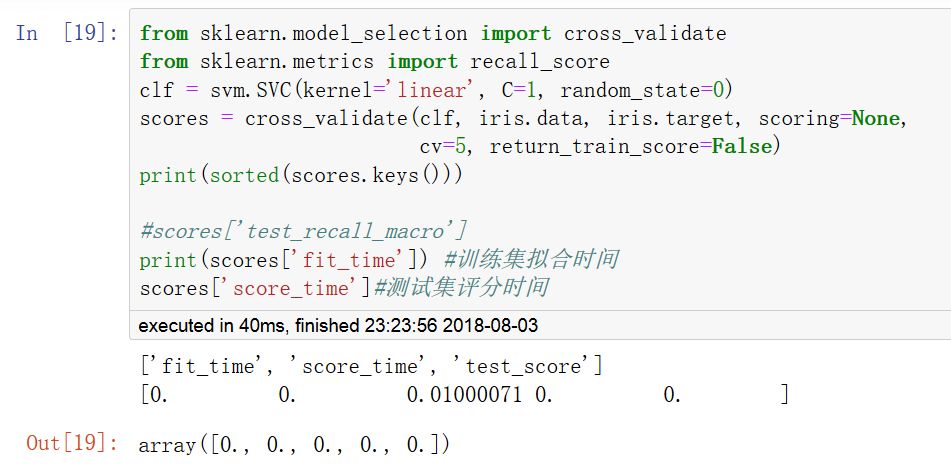
cross_validate函数和cross_val_score函数类似,但功能更为强大,它允许指定多个指标进行评估,并且除返回指定的指标外,还会返回一个fit_time和score_time即训练时间和评分时间。
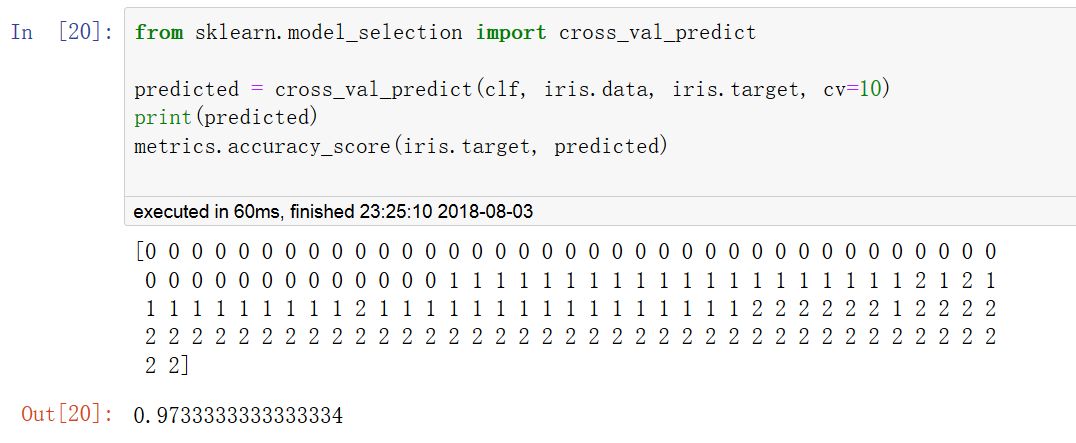
使用cross_val_predict可以返回每条样本作为CV中的测试集时,对应的模型对该样本的预测结果。
这就要求使用的CV策略能保证每一条样本都有机会作为测试数据,否则会报异常。
关于“python模型的评估实例分析”这篇文章的内容就介绍到这里,感谢各位的阅读!相信大家对“python模型的评估实例分析”知识都有一定的了解,大家如果还想学习更多知识,欢迎关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4592076/blog/4414003



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



