本篇内容介绍了“Python中如何用PyPDF2模块拆分PDF文档”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
安装PyPDF2模块
# 这个模块严格区分大小写,y是小写,其余大写
pip3 install PyPDF2
安装完成之后呢,在本地硬盘创建一个专门存放本项目的文件夹,我这里在的存放路径是 F:\Python\PyPDF2,在F盘有个Python文件夹,在其中又创建了一个以这个模块命名的文件夹,来单独存放和与别的项目区分。
创建文件,准备PDF文档
找一个练手的比较大的PDF文档,我在Django官网下载了他的文档,这个文档足够大,1900多页,对于练手绝对够了,有需要的去官网下载,或者在我的公众号直接回复‘pdf’ 获取下载链接,然后再创建一个PDFCF.py 的项目文件。
开始写
程序开始两行,写上下边这两句,第一句的意思是指定这个文件的运行程序,第二句是对这个文件的说明,这个的作用现在还看不出来,但如果你知道怎么批量化快速执行程序,你就知道了它的作用,这里不做赘述。
#! python# PDFCF.py - pdf文件拆分程序
文档的拆分思路
不固定拆分成多少份,但固定每一份由多少页组成,然后来动态的计算拆分的份数,拆分思路有了,那么下来就是列出计算公式。
拆分的份数= 文档总页数 / 拆份每个pdf组成的页数
举个例子:
假如我们要拆分一个总页数为35页的pdf文档,按照每10页组成一个新文档,那么能拆分成多少份的计算公式如下:
3.5 = 35 / 10
这时候大家注意了,除不尽有余数0.5,说明什么?用这个例子来说就是拆分成3份还余下5页,那么遇到这种情况不管余数是几都得向前进1,才能完成整个拆分,这个文档拆分的结果就是,前3个文档每个由10页组成,第四个文档则由最后5页组成,能整除则结果直接就是拆分的份数。
python拆分计算公式:
if 35 % 10: # 判断是否有余数 35 // 10 + 1 # 取余数整数部分加1else: 0 # 能整除则直接返回0 # 将这个循环写到一行4 = 35 // 10 + 1 if 35 % 10 else 0
具体怎么拆?
还是以这个35页的文档拆分为例:
循环遍历每一页数据 for num in range(35),得到每一页的数据,之后再指定拆分页数范围进行拆分:
第一个文档从0--10,不包含10
第二个文档从10--20 ,不包含20
第三个文档从 20 -30,不包含30
第四个文档从30--35,不包含35
我们发现规律,每次遍历第一个数字的规律是 一个文档的页数,乘以自己属于第几个便可以得到。第二个数我们发现没规律了,其实仔细观察也有规律,假如我们对拆分个数排序,这个例子就是1--4,第二个数字就是当前属于第几个拆分数乘以每个文档组成的页数(页数是固定的10)。
可是我们第一次遍历的时候从0开始,就让num变得不通用,那么我们改造一下从1开始遍历,range(1,35),从一开始遍历,基于range不包含本身最后一个的特性,这样遍历出来就少了一页文档,那么我们给他加1,变成
for num in range(1,35+1)
第一个文档从10*(1-1)--10*1,不包含10
第二个文档从10*(2-1)--10*2 ,不包含20
第三个文档从 10*(3-1) -10*3, 不包含30
第四个文档从10(4-1)--35
具体遍历代码如下:
for num in range(1,35+1): pass for i in range(10 * (num-1), 10 * num if num != 4 else 35): pass
注意:当遍历到 num = 4(最后一个文档排序数时),直接返回 总页数35就可以了,到这里遍历就结束了。这里为什么是总页数35 而不是35+1呢?是因为此次遍历我们是从0开始遍历的,页码从0开始,所以不需要加1了。
完整拆分程序:
import PyPDF2# 打开一个可读的pdf对象pdfReader = PyPDF2.PdfFileReader('django.pdf')# 获取pdf总页数pdfnums = pdfReader.numPages# 每个拆分文档由多少页组成innumber = 100# 计算拆分份数outnums = pdfnums // innumber + 1 if pdfnums % innumber else 0for num in range(1,pdfnums):# 创建空白的pdfpdfWriter = PyPDF2.PdfFileWriter()# 提取指定页面范围for pageNum in range(innumber * (num - 1), innumber * num if num != outnums else pdfnums):# 获取到每一页的内容pageObj = pdfReader.getPage(pageNum)# 将每一页的内容添加到第一次循环创建的空白文档对象中pdfWriter.addPage(pageObj)# 保存并写入本地文件,并对每个文档重命名with open('PDFREAD %s' % num + '.pdf', 'wb') as pdfOutputFile:pdfWriter.write(pdfOutputFile)
注意:上边这种拆分思路我个人感觉比较绕,如果你对Python列表的切边以及步长概念理解透彻的话,我觉得不需要这么复杂,只需要把总页码生成一个大列表,再把这个列表利用切片的方法拆分成多个小列表,之后每个拆分的pdf页码范围就是每个小列表第一个数--最后一个数+1,我把我用列表方法实现的代码也贴出来供大家参考。
拆分列表方法实现拆分PDF:
#! python# PDFCF.py - pdf文件拆分程序import PyPDF2# import LISTCF# 打开一个可读的pdf对象pdfReader = PyPDF2.PdfFileReader('django.pdf')# 获取pdf总页数pdfnums = pdfReader.numPages# 将总页码循环到一个列表中pagenum_list = list(range(pdfnums))n = 100# 将总页码按照指定的个数分为多个小列表page_list = [pagenum_list[i:i + n] for i in range(0, len(pagenum_list), n)]for i in range(len(page_list)):# 创建一个空白的pdfpdfWriter = PyPDF2.PdfFileWriter()# 提取指定页面for pageNum in range(page_list[i][1], page_list[i][-1]+1):pageObj = pdfReader.getPage(pageNum)pdfWriter.addPage(pageObj)with open('PDFREAD %s' % i + '.pdf', 'wb') as pdfOutputFile:pdfWriter.write(pdfOutputFile)
怎么用?
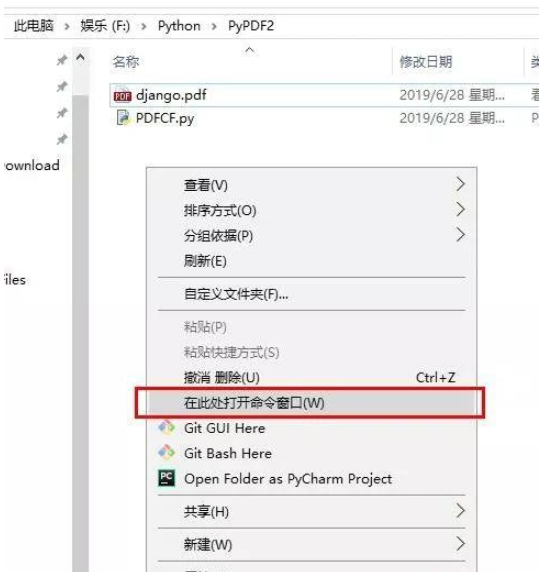
在项目文件夹内部按住Shift键,点击鼠标右键,选择在此处打开命令窗口,输入PDFCF.py,回车即可,根据自己的需求去更改 n 的值。
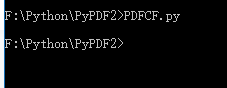
“Python中如何用PyPDF2模块拆分PDF文档”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





