如何进行HashMap的部分源码剖析,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
HashMap基于哈希表的 Map 接口的实现。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。(除了不同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。)此类不保证映射的顺序,特别是它不保证该顺序恒久不变。HashMap的结构如下:
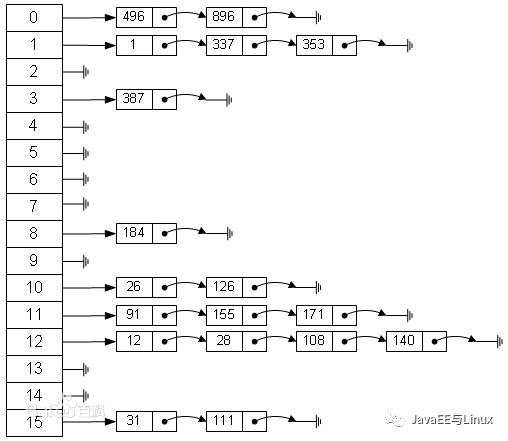
我们可以看到HashMap的结构主要分为两大部分:左侧的table和右侧的链表,下面重点分析HashMap的源码。


(1)、final int hash(Object k),此方法用来计算key的哈希值,由方法最后的几行可以看到,为了保证key的均匀散列,并没有使用hashCode%length的方法,因为移位运算符不仅可以更均匀的散列而且匀速速度也比hashCode%length更快。
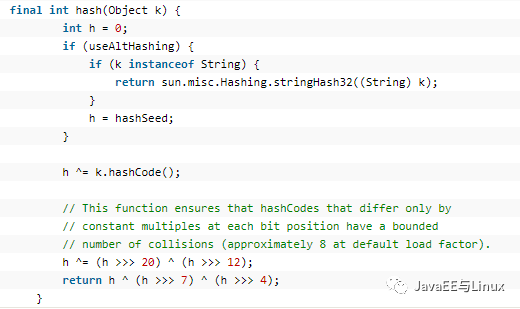
(2)、public V get(Object key)
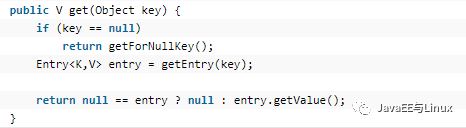
我们看到,get方法首先判断key是否为null,如果为null,则调用getForNullKey(),否则调用getEntry(key)方法获取value,让我们来继续分析getForNullKey的源码:
private V getForNullKey()
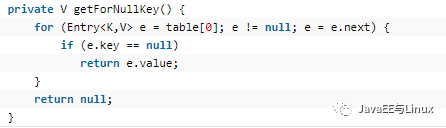
可见:循环遍历table[0]的那个链表,直到找到key==null的Entry,否则返回null;为什么是table[0]呢?因为在put的时候如果key==null,直接将entry存储在table[0]的位置,我们在后面分析put方法。接下来再分析getEntry(key)方法:
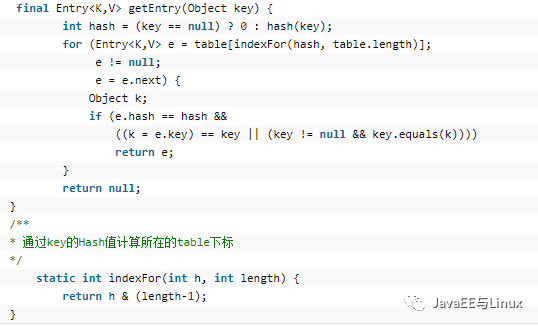
通过key的Hash值计算Entry所在table的小标,请注意计算下标的方法通过indexFor()方法得到,然后遍历Entry,直到找到hash和equals都相等的Entry后返回,否则返回null;
好了,get方法基本就是这样,接下来我们一起来分析put方法。
(3)、 public V put(K key, V value)

put方法的大致流程是:
①、首先判断key是否为null,如果为null,调用putForNullKey(value)方法,请大家注意,putForNullKey和上面的getForNullKey的逻辑是一一对应的哦。
②、计算key的Hash值,通过indexFor()方法定位到元素存储在table的位置table[i]。
③、循环遍历table[i],如果新值和旧值相等,覆盖旧值后返回旧值
④、modCount++,操作次数+1,调用addEntry将新值插入到链表。
让我们来分析putForNullKey(value)方法源码:

请看,这里又是table[0],和getForNullKey中的table[0]对称,遍历-->新值覆盖旧值-->返回旧值-->操作数+1-->插入新元素,很容易理解。
接下来重点来了,让我们来分析addEntry方法中的一系列逻辑:

首先,threshold=capacity * load factor,也就是临界值=容量*加载因子=16*0.75f, map中使用量超过threshold,会扩容为原来的2倍。resize是一个非常复杂的过程,涉及到rehash等,后面我在介绍,现在咱们重点看addEntry()。bucketIndex是元素存储在table的下标,也就是将元素存储在table[bucketIndex]。最后调用createEntry将新元素存储在HashMap中,createEntry的源码如下:

通过new Entry(hash,key,value,e),将新元素插到table[bucketIndex]中,我们来看Entry的构造方法:

重点在next = n这行,看到到插入元素到链表中使用的头插法,不用尾插的目的估计是为了节省遍历链表的开销吧。
好了,put方法就是这样,其实也特别好理解,接下来我们来分析Entry这类。
HashMap有一个变量:transient Entry<K,V>[] table,可以看到table是一个Entry的数组,并且Entry本身是一个链表的一个元素。Entry<K,V> implements Map.Entry<K,V>,而Map.Entry是一个接口。Entry包含四个元素,final K key; V value; Entry<K,V> next;int hash;hash是这个元素的hash值,其余的三个元素就不解释了。Entry类的方法基本上都很简单,大家可以通过阅读源码来理解,我重点解释一下equals和hashCode这两个方法,源码如下:
 比较连个Entry是否相等就是通过if中的条件,比较容易理解,hashCode源码:
比较连个Entry是否相等就是通过if中的条件,比较容易理解,hashCode源码:

最后,重点分析rehash方法,在分析rehash时,我先解释一下什么是rehash:当我们的HashMap的使用量超过了threshold=capacity * load factor,也就是临界值=容量*加载因子=16*0.75f,就会发生rehash,将容量扩大为原来的两倍,然后所有的元素根据新的hash规则重新散列到不同的table[i]中。但是rehash有很大的性能消耗,所以如果我们在使用HashMap时能预测到元素的个数,最好在构造时就指定HashMap的大小。rehash的源码如下:
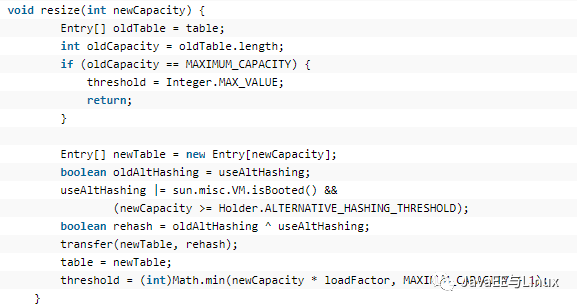
Entry[] newTable = new Entry[newCapacity],常见一个新的table,很消耗内存的!!!前面容易理解,重点看transfer方法,这个方法才是将元素重新散列的方法,源码如下:
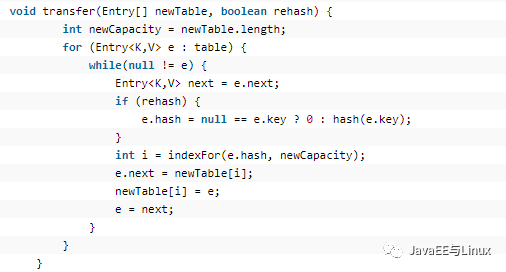
循环遍历table(旧数组),计算出newTable的下标,将旧元素e存储到newTable中,这里有一个细节要注意,在我讲put方法时提到过,插入元素的方法时头插法,就是新的元素被添加到链表的头部,但我们通过transfer方法可分析出:在rehash的时候,之前在头部的元素会先进行rehash,在尾部的元素会最后rehash,所以当rehash结束后,之前在头部的元素会沉到尾部,之前在尾部的元素会上升到头部。
关于如何进行HashMap的部分源码剖析问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





