这篇文章给大家介绍BiLSTM上的CRF层是如何工作,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
看了许多的CRF的介绍和讲解,这个感觉是最清楚的,结合实际的应用场景,让你了解CRF的用处和用法。
你需要知道的惟一的事情是什么是命名实体识别。如果你不知道神经网络,CRF或任何其他相关知识,请不要担心。我会尽可能直观地解释一切。
对于命名实体识别任务,基于神经网络的方法非常普遍。我将以文中的模型为例来解释CRF层是如何工作的。
如果你不知道BiLSTM和CRF的细节,请记住它们是命名实体识别模型中的两个不同的层。
我们假设,我们有一个数据集,其中有两个实体类型,Person和Organization。但是,事实上,在我们的数据集中,我们有5个实体标签:
此外,x是一个包含5个单词的句子,w0,w1,w2,w3,w4。更重要的是,在句子x中,[w0,w1]是一个Person实体,[w3]是一个Organization实体,其他都是“O”。
我将对这个模型做一个简单的介绍。
如下图所示:
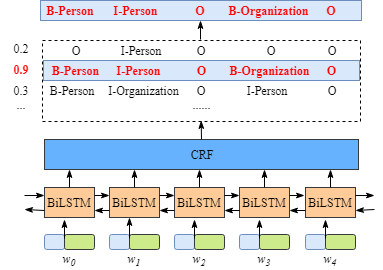
虽然不需要知道BiLSTM层的细节,但是为了更容易的理解CRF层,我们需要知道BiLSTM层输出的意义是什么。
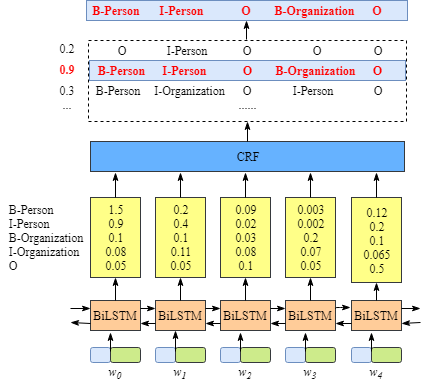
上图说明BiLSTM层的输出是每个标签的分数。例如,对于w0, BiLSTM节点的输出为1.5 (B-Person)、0.9 (I-Person)、0.1 (B-Organization)、0.08 (I-Organization)和0.05 (O),这些分数将作为CRF层的输入。
然后,将BiLSTM层预测的所有分数输入CRF层。在CRF层中,选择预测得分最高的标签序列作为最佳答案。
你可能已经发现,即使没有CRF层,也就是说,我们可以训练一个BiLSTM命名实体识别模型,如下图所示。
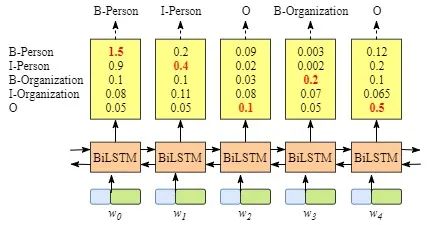
因为每个单词的BiLSTM的输出是标签分数。我们可以选择每个单词得分最高的标签。
例如,对于w0,“B-Person”得分最高(1.5),因此我们可以选择“B-Person”作为其最佳预测标签。同样,我们可以为w1选择“I-Person”,为w2选择“O”,为w3选择“B-Organization”,为w4选择“O”。
虽然在这个例子中我们可以得到正确的句子x的标签,但是并不总是这样。再试一下下面图片中的例子。
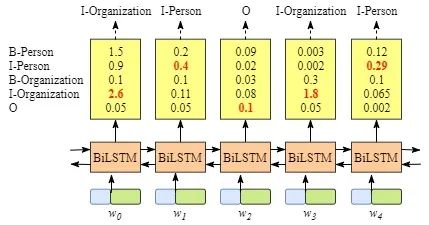
显然,这次的输出是无效的,“I-Organization I-Person”和“B-Organization I-Person”。
CRF层可以向最终的预测标签添加一些约束,以确保它们是有效的。这些约束可以由CRF层在训练过程中从训练数据集自动学习。
约束条件可以是:
有了这些有用的约束,无效预测标签序列的数量将显著减少。
关于BiLSTM上的CRF层是如何工作就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





