这篇文章主要介绍“Java并发编程的知识点有哪些”,在日常操作中,相信很多人在Java并发编程的知识点有哪些问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Java并发编程的知识点有哪些”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
杀死一个开发,只需要变更三次需求。
2.1-volatile的应用(wall la tai l 还是 wall lei tai l)
它在多处理器开发中保证了共享变量的“可见性”。可见性的意思是当一个线程
修改一个共享变量时,另外一个线程能读到这个修改的值,它不会引起线程上下文的切换和调度
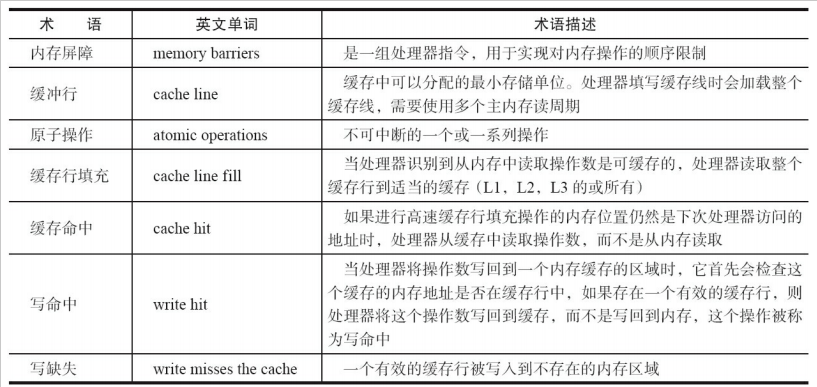
CPU术语定义
volatile是如何来保证可见性的呢?让我们在X86处理器下通过工具获取JIT编译器生成的
汇编指令来查看对volatile进行写操作时,CPU会做什么事情。
Java代码如下。
instance = new Singleton(); // instance是volatile变量转变成汇编代码,如下。
0x01a3de1d: movb $0×0,0×1104800(%esi);0x01a3de24: lock addl $0×0,(%esp);Lock前缀的指令在多核处理器下会引发了两件事情[1]。
1)将当前处理器缓存行的数据写回到系统内存。
2)这个写回内存的操作会使在其他CPU里缓存了该内存地址的数据无效。
2.volatile的使用优化
著名的Java并发编程大师Doug lea在JDK 7的并发包里新增一个队列集合类Linked-
TransferQueue,它在使用volatile变量时,用一种追加字节的方式来优化队列出队和入队的性
能。LinkedTransferQueue的代码如下。
/** 队列中的头部节点 */private transient f?inal PaddedAtomicReference<QNode> head;/** 队列中的尾部节点 */private transient f?inal PaddedAtomicReference<QNode> tail;static f?inal class PaddedAtomicReference <T> extends AtomicReference T> {// 使用很多4个字节的引用追加到64个字节 Object p0, p1, p2, p3, p4, p5, p6, p7, p8, p9, pa, pb, pc, pd, pe; PaddedAtomicReference(T r) {super(r); }}public class AtomicReference <V> implements java.io.Serializable {private volatile V value;// 省略其他代码}追加字节能优化性能?这种方式看起来很神奇,但如果深入理解处理器架构就能理解其中的奥秘。让我们先来看看LinkedTransferQueue这个类,它使用一个内部类类型来定义队列的头节点(head)和尾节点(tail),而这个内部类PaddedAtomicReference相对于父类AtomicReference只做了一件事情,就是将共享变量追加到64字节。我们可以来计算下,一个对象的引用占4个字节,它追加了15个变量(共占60个字节),再加上父类的value变量,一共64个
字节。
为什么追加64字节能够提高并发编程的效率呢?因为对于英特尔酷睿i7、酷睿、Atom和NetBurst,以及Core Solo和Pentium M处理器的L1、L2或L3缓存的高速缓存行是64个字节宽,不支持部分填充缓存行,这意味着,如果队列的头节点和尾节点都不足64字节的话,处理器会将它们都读到同一个高速缓存行中,在多处理器下每个处理器都会缓存同样的头、尾节点,当一个处理器试图修改头节点时,会将整个缓存行锁定,那么在缓存一致性机制的作用下,会导致其他处理器不能访问自己高速缓存中的尾节点,而队列的入队和出队操作则需要不停修改头节点和尾节点,所以在多处理器的情况下将会严重影响到队列的入队和出队效率。Doug lea使用追加到64字节的方式来填满高速缓冲区的缓存行,避免头节点和尾节点加载到同一个缓存行,使头、尾节点在修改时不会互相锁定。
那么是不是在使用volatile变量时都应该追加到64字节呢?不是的。在两种场景下不应该
使用这种方式。
·缓存行非64字节宽的处理器。如P6系列和奔腾处理器,它们的L1和L2高速缓存行是32个字节宽。
·共享变量不会被频繁地写。因为使用追加字节的方式需要处理器读取更多的字节到高速缓冲区,这本身就会带来一定的性能消耗,如果共享变量不被频繁写的话,锁的几率也非常小,就没必要通过追加字节的方式来避免相互锁定。
不过这种追加字节的方式在Java 7下可能不生效,因为Java 7变得更加智慧,它会淘汰或重新排列无用字段,需要使用其他追加字节的方式。
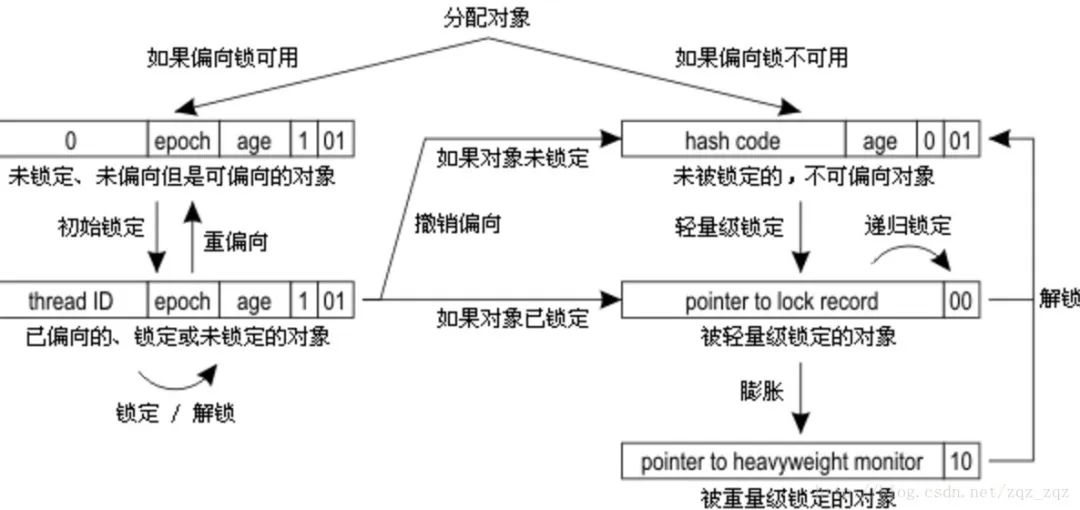
2.2.1Java对象头
synchronized用的锁是存在Java对象头里的。如果对象是数组类型,则虚拟机用3个字宽(Word)存储对象头,如果对象是非数组类型,则用2字宽存储对象头。在32位虚拟机中,1字宽等于4字节,即32bit
Java对象头里的Mark Word里默认存储对象的HashCode、分代年龄和锁标记位

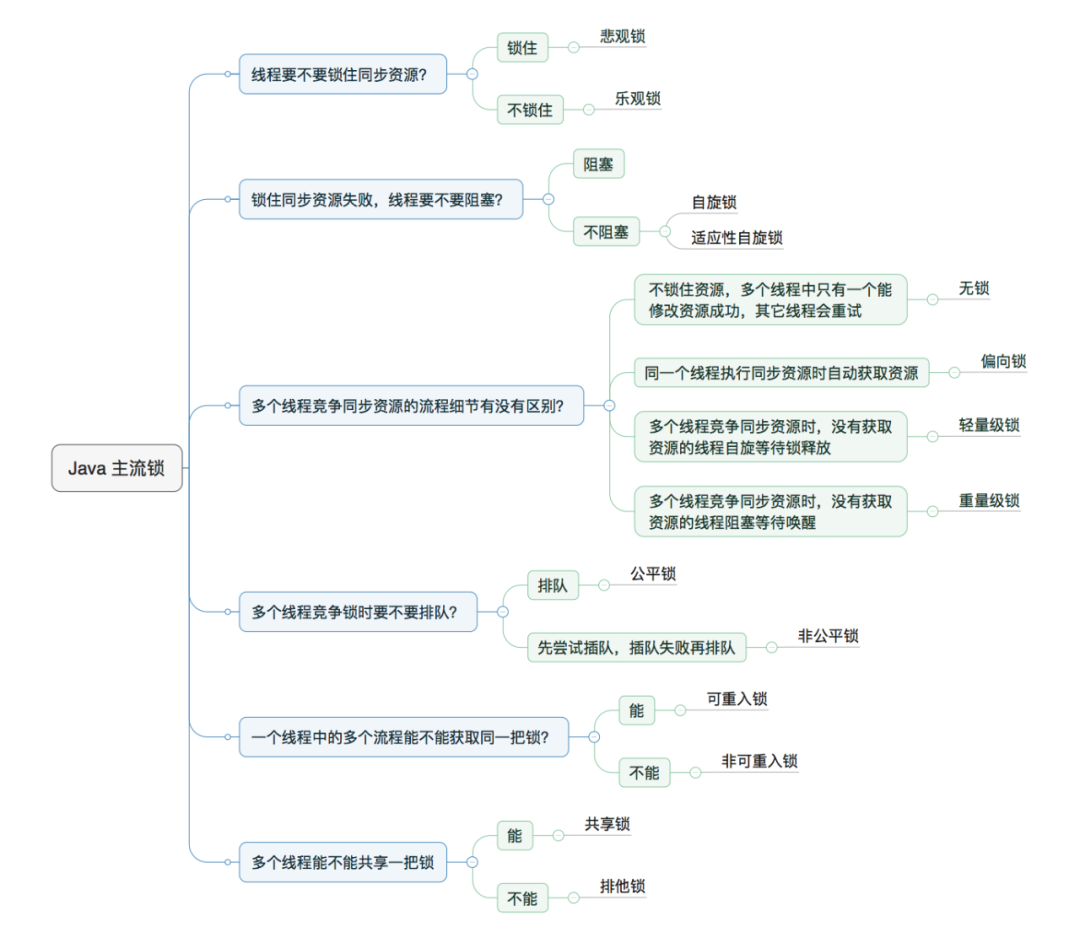
2.2.2 锁的升级与对比
Java SE 1.6中,锁一共有4种状态,级别从低到高依次是:无锁状态、偏向锁状态、轻量级锁状
态和重量级锁状态
锁可以升级,但不可降级
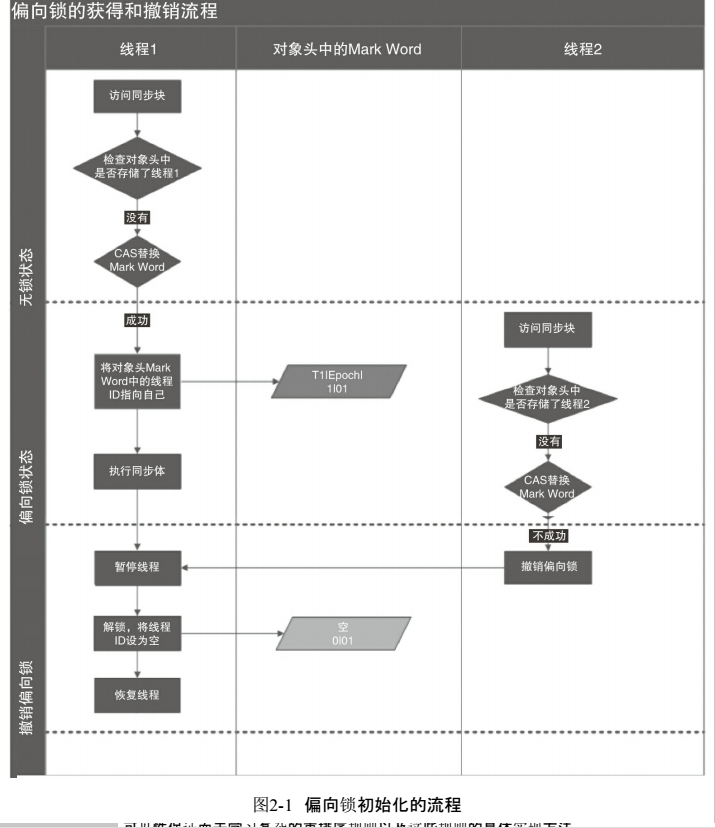
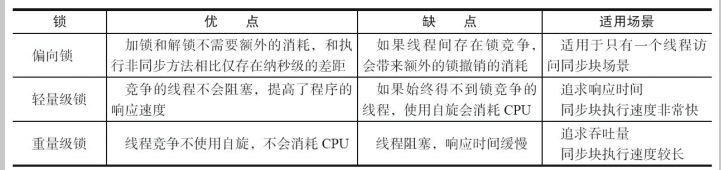
1.偏向锁(Biased Locking)
个人理解:偏向,偏心,如果在运行过程中,遇到了其他线程抢占锁,则持有偏向锁的线程会被挂起,此时会设置偏向锁的标识
在大多数情况下,锁总是由同一线程多次获得,不存在多线程竞争,所以出现了偏向锁。其目标就是在只有一个线程执行同步代码块时能够提高性能。
锁的撤销以及锁的关闭都是会产生开销的
偏向锁的适用场景
始终只有一个线程在执行同步块,在它没有执行完释放锁之前,没有其它线程去执行同步块,在锁无竞争的情况下使用,一旦有了竞争就升级为轻量级锁,升级为轻量级锁的时候需要撤销偏向锁,撤销偏向锁的时候会导致stop the word操作;
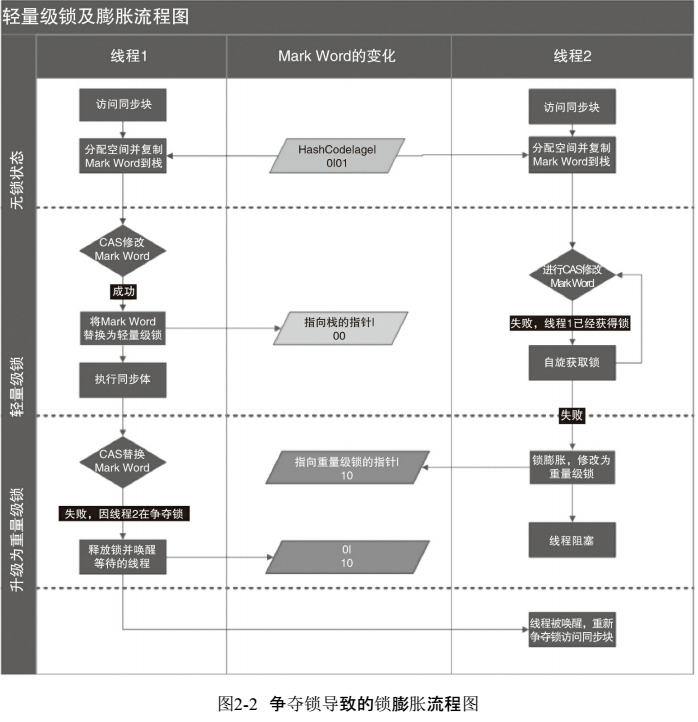
2.轻量级锁
偏向锁运行在一个线程进入同步块的情况下,当第二个线程加入锁争用的时候,偏向锁就会升级为轻量级锁;
(1)轻量级锁加锁
线程在执行同步块之前,JVM会先在当前线程的栈桢中创建用于存储锁记录的空间,并
将对象头中的Mark Word复制到锁记录中,官方称为Displaced Mark Word。然后线程尝试使用
CAS将对象头中的Mark Word替换为指向锁记录的指针。如果成功,当前线程获得锁,如果失
败,表示其他线程竞争锁,当前线程便尝试使用自旋来获取锁。
(2)轻量级锁解锁
轻量级解锁时,会使用原子的CAS操作将Displaced Mark Word替换回到对象头,如果成
功,则表示没有竞争发生。如果失败,表示当前锁存在竞争,锁就会膨胀成重量级锁
锁的优缺点的对比
重量级锁Synchronized
特别记录一下
当作用于静态方法时,锁住的是Class实例,又因为Class的相关数据存储在永久带PermGen(jdk1.8则是metaspace),永久带是全局共享的,因此静态方法锁相当于类的一个全局锁,会锁所有调用该方法的线程;
从JVM规范中可以看到Synchonized在JVM里的实现原理,JVM基于进入和退出Monitor对象来实现方法同步和代码块同步,但两者的实现细节不一样。代码块同步是使用monitorenter和monitorexit指令实现的,而方法同步是使用另外一种方式实现的
总结
以下摘抄博客
https://blog.csdn.net/xiaobaixiongxiong/article/details/100933396在所有的锁都启用的情况下线程进入临界区时会先去获取偏向锁,如果已经存在偏向锁了,则会尝试获取轻量级锁,如果以上两种都失败,则启用自旋锁,如果自旋也没有获取到锁,则使用重量级锁,没有获取到锁的线程阻塞挂起,直到持有锁的线程执行完同步块唤醒他们;
偏向锁是在无锁争用的情况下使用的,也就是同步开在当前线程没有执行完之前,没有其它线程会执行该同步块,一旦有了第二个线程的争用,偏向锁就会升级为轻量级锁,一点有两个以上线程争用,就会升级为重量级锁;
如果线程争用激烈,那么应该禁用偏向锁。
锁优化
以上介绍的锁不是我们代码中能够控制的,但是借鉴上面的思想,我们可以优化我们自己线程的加锁操作;
减少锁的时间
不需要同步执行的代码,能不放在同步快里面执行就不要放在同步快内,可以让锁尽快释放;
减少锁的粒度
它的思想是将物理上的一个锁,拆成逻辑上的多个锁,增加并行度,从而降低锁竞争。它的思想也是用空间来换时间;
---------摘抄完毕
自旋锁 VS 适应性自旋锁
阻塞或唤醒一个Java线程需要操作系统切换CPU状态来完成,这种状态转换需要耗费处理器时间。如果同步代码块中的内容过于简单,状态转换消耗的时间有可能比用户代码执行的时间还要长。
在许多场景中,同步资源的锁定时间很短,为了这一小段时间去切换线程,线程挂起和恢复现场的花费可能会让系统得不偿失。如果物理机器有多个处理器,能够让两个或以上的线程同时并行执行,我们就可以让后面那个请求锁的线程不放弃CPU的执行时间,看看持有锁的线程是否很快就会释放锁。
而为了让当前线程“稍等一下”,我们需让当前线程进行自旋,如果在自旋完成后前面锁定同步资源的线程已经释放了锁,那么当前线程就可以不必阻塞而是直接获取同步资源,从而避免切换线程的开销。这就是自旋锁。
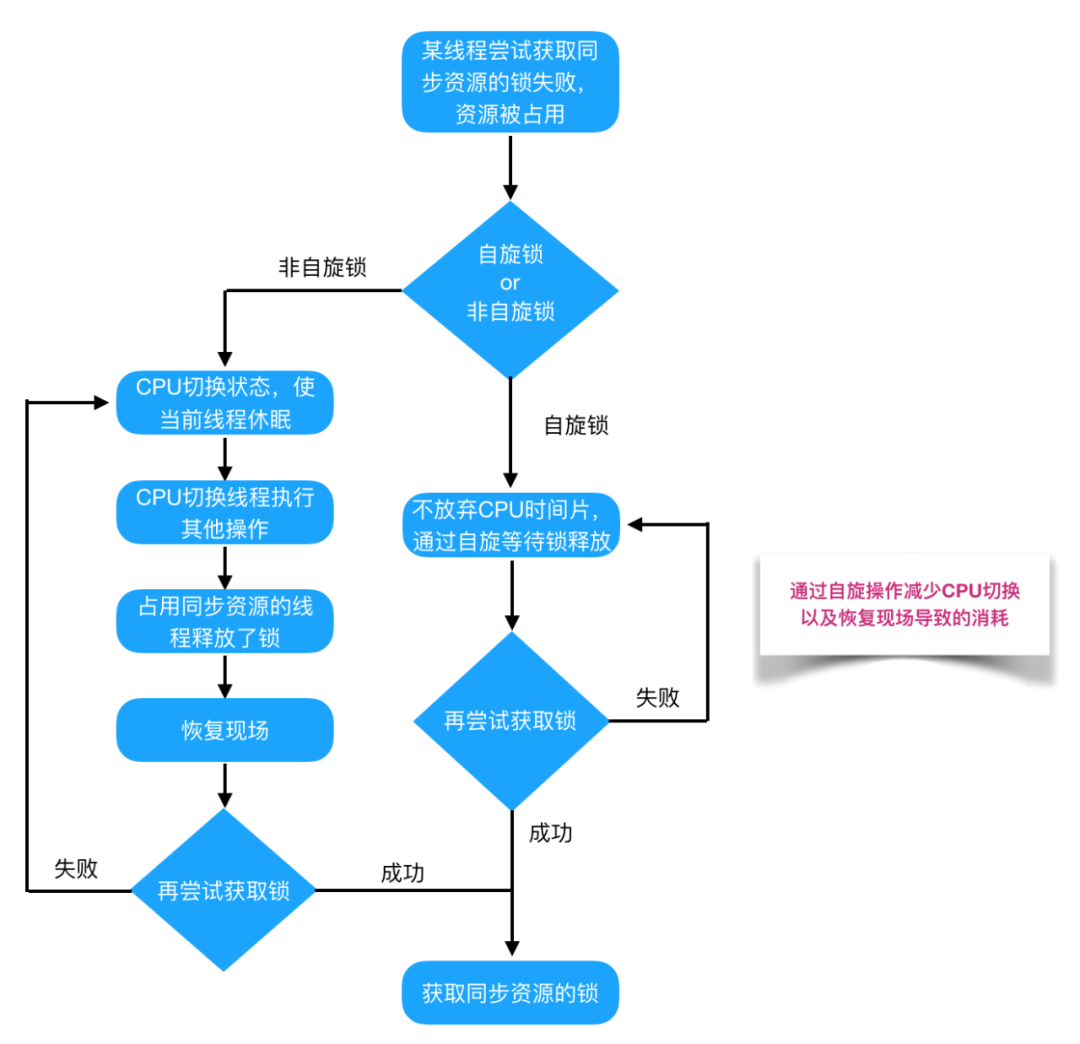
自旋锁本身是有缺点的,它不能代替阻塞。自旋等待虽然避免了线程切换的开销,但它要占用处理器时间。如果锁被占用的时间很短,自旋等待的效果就会非常好。反之,如果锁被占用的时间很长,那么自旋的线程只会白浪费处理器资源。所以,自旋等待的时间必须要有一定的限度,如果自旋超过了限定次数(默认是10次,可以使用-XX:PreBlockSpin来更改)没有成功获得锁,就应当挂起线程。
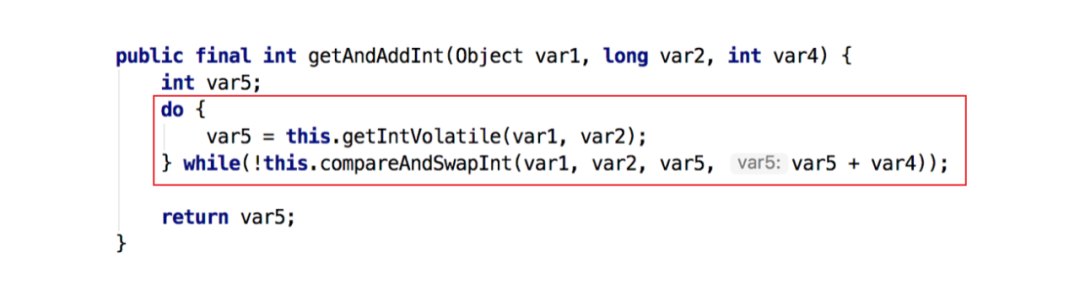
自旋锁的实现原理同样也是CAS,AtomicInteger中调用unsafe进行自增操作的源码中的do-while循环就是一个自旋操作,如果修改数值失败则通过循环来执行自旋,直至修改成功。
自旋锁在JDK1.4.2中引入,使用-XX:+UseSpinning来开启。JDK 6中变为默认开启,并且引入了自适应的自旋锁(适应性自旋锁)。
自适应意味着自旋的时间(次数)不再固定,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也是很有可能再次成功,进而它将允许自旋等待持续相对更长的时间。如果对于某个锁,自旋很少成功获得过,那在以后尝试获取这个锁时将可能省略掉自旋过程,直接阻塞线程,避免浪费处理器资源。
在自旋锁中 另有三种常见的锁形式:TicketLock、CLHlock和MCSlock,本文中仅做名词介绍,不做深入讲解,感兴趣的同学可以自行查阅相关资料。
---以上来源于美团技术博客
请解释偏向锁对 synchronized 与 ReentrantLock 的价值?
偏向锁?
对synchronize有用
Java偏向锁(Biased Locking)是Java6引入的一项多线程优化。
偏向锁,顾名思义,它会偏向于第一个访问锁的线程,如果在运行过程中,同步锁只有一个线程访问,不存在多线程争用的情况,则线程是不需要触发同步的,这种情况下,就会给线程加一个偏向锁。
如果在运行过程中,遇到了其他线程抢占锁,则持有偏向锁的线程会被挂起,JVM会消除它身上的偏向锁,将锁恢复到标准的轻量级锁。
它通过消除资源无竞争情况下的同步原语,进一步提高了程序的运行性能。
ReentrantLock已经实现了偏向锁
synchronized实际也是可重入的只不过是jvm层次的
到此,关于“Java并发编程的知识点有哪些”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4217373/blog/4449540



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



