如何使用scrapy-redis做简单的分布式,相信很多没有经验的人对此束手无策,为此本文总结了问题出现的原因和解决方法,通过这篇文章希望你能解决这个问题。
每次项目重新启动的时候不可能再去把相同的内容重新采集一次,所以增量爬取很重要
使用分布式scrapy-redis可以实现去重与增量爬取。因为这个库可以通过redis实现去重与增量爬取,爬虫停止以后下次运行会接着上次结束的节点继续运行.
缺点是,Scrapy-Redis调度的任务是Request对象,里面信息量比较大(不仅包含url,还有callback函数、headers等信息),可能导致的结果就是会降低爬虫速度、而且会占用Redis大量的存储空间,所以如果要保证效率,那么就需要一定硬件水平。
总结一下:
1. Scrapy-Reids 就是将Scrapy原本在内存中处理的 调度(就是一个队列Queue)、去重、这两个操作通过Redis来实现
多个Scrapy在采集同一个站点时会使用相同的redis key(可以理解为队列)添加Request 获取Request 去重Request,这样所有的spider不会进行重复采集。效率自然就嗖嗖的上去了。
3. Redis是原子性的,好处不言而喻(一个Request要么被处理 要么没被处理,不存在第三可能)
建议大家去看看崔大大的博客,干货很多。
然后就是安装redis了,
安装redis自行百度网上全是,或者点这里https://blog.csdn.net/zhao_5352269/article/details/86300221
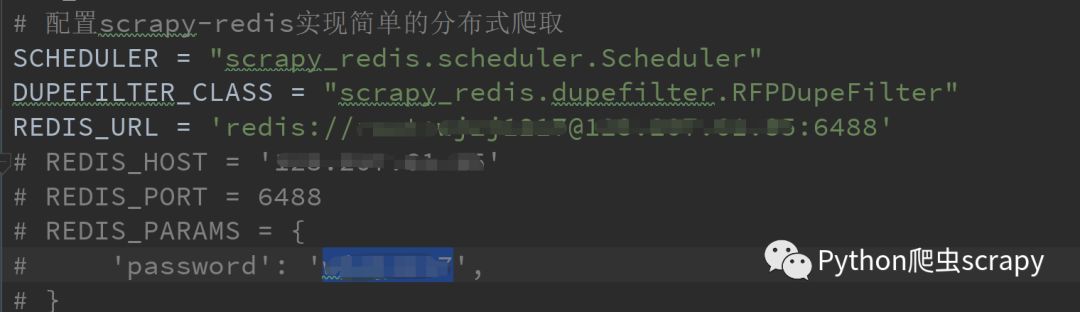
第二步就是setting.py 的配置
master的配置没密码的话去掉:后的
| # 配置scrapy-redis实现简单的分布式爬取 |
| SCHEDULER = "scrapy_redis.scheduler.Scheduler" |
| DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" |
| REDIS_URL = 'redis://root:123456@192.168.114.130:6379' |
Slave的配置
| # 配置scrapy-redis实现简单的分布式爬取 |
| SCHEDULER = "scrapy_redis.scheduler.Scheduler" |
| DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" |
| REDIS_HOST = '192.168.114.130' |
| REDIS_PORT = 6379 |
| REDIS_PARAMS = { |
| 'password': '123456', |
| } |
安装scrapy-redis
pip3 install scrapy-reids
安装完之后就可以实现简单的分布式,两个可以随意启动。
看完上述内容,你们掌握如何使用scrapy-redis做简单的分布式的方法了吗?如果还想学到更多技能或想了解更多相关内容,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4080705/blog/4419347



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



