小编给大家分享一下如何使用scrapy框架爬取美团网站的数据,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
最近入坑爬虫,在摸索使用scrapy框架爬取美团网站的数据
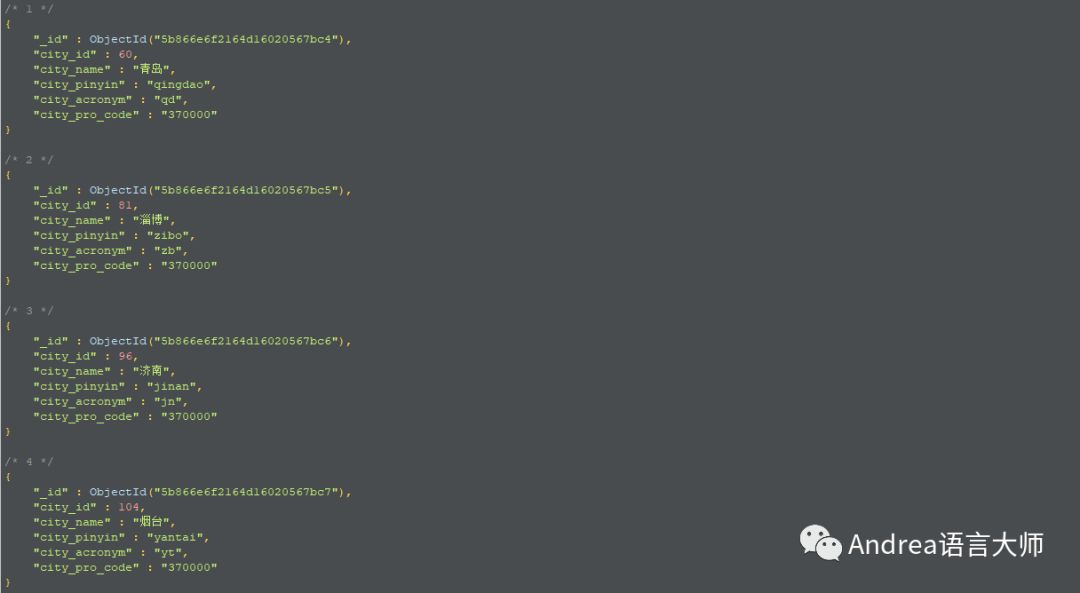
第一步,准备从地区信息开始爬,打开美团官网,点击切换地区,按F12,点击XHR,XHR会过滤出来异步请求,这样我们就看大了美团的地区信息的json数据,复制该链接http://www.meituan.com/ptapi/getprovincecityinfo/
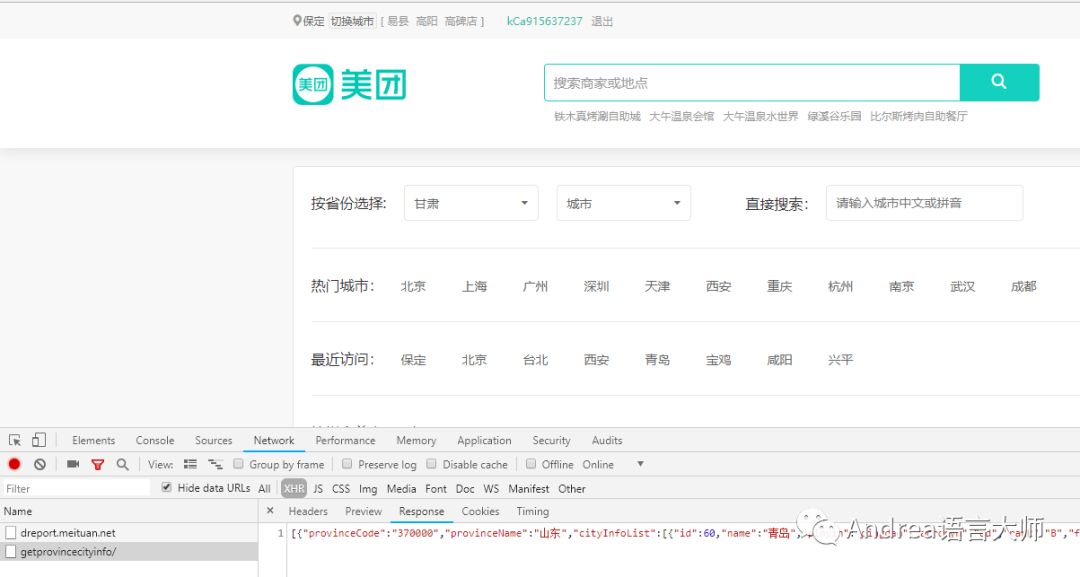

解析该json数据,会获取到部分的地区以及区县的信息,但这样不利于后面的爬取,会重复爬取。我是通过过滤出来市一级的信息,然后利用页面的中区域分类信息进行爬取。
将获取到的数据保存到MongoDB数据库
先保存省然后是市然后区县然后是街道,然后根据街道的url爬取数据
这是获取省份以及市的代码
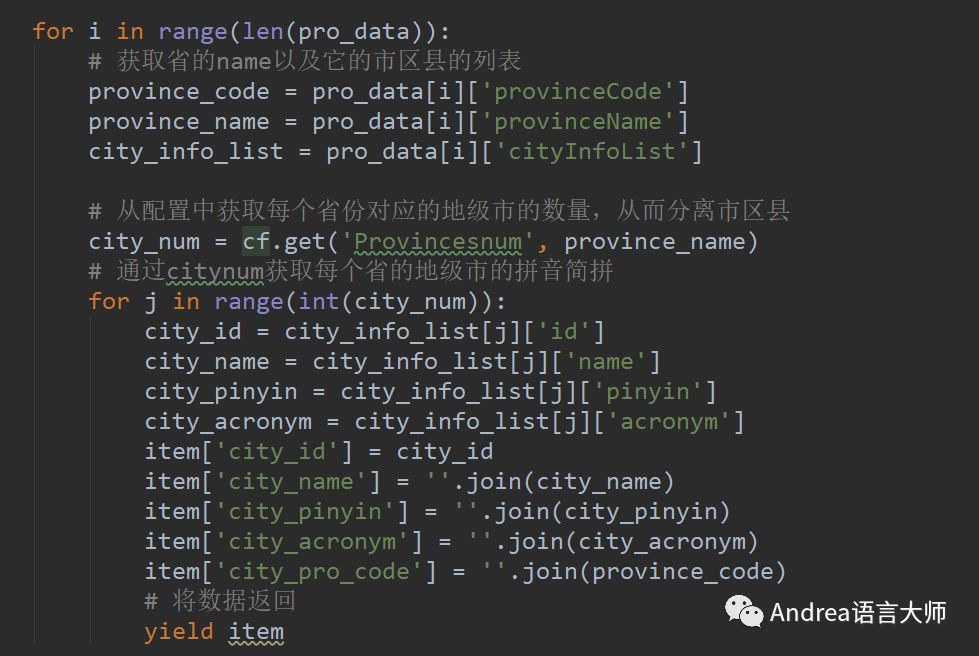
观察获取到的json数据后发现前面均为市一级的信息,所以通过每个省有多少个市来建立配置文件,通过配置文件来获取。
在通过读取配置文件的方式,过滤掉区县,留下市一级的所有信息
读取配置使用configparser模块。保存到数据库
scrapy框架遵守robot.txt规则,所以会被拒绝访问,在setting中设置
ROBOTSTXT_OBEY = False
同事为了避免出现请求403错误,继续设置setting
'''
伪造一个用户信息,防止403
'''
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
ITEM_PIPELINES = {
'Tencent.pipelines.TencentPipeline': 300,
}
'''
防止403崩溃。
'''
HTTPERROR_ALLOWED_CODES = [403]
以上是“如何使用scrapy框架爬取美团网站的数据”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4080705/blog/4419425



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



