这篇文章给大家介绍CNN网络层的知识有哪些,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
卷积神经网络(CNN)由输入(Inputs)、卷积层(Convolutions layer)、激活层(Activation)、池化层(Pooling layer)和全连接层(Fully Connected, FC)成。这句话的意思是CNN里面可以有这些层,但是每种网络层(Layer)的个数理论上是可以任意多个的。这也就有了后来的AlexNet,GoogLeNet,ResNet等著名的网络结构,后面我会选择一两个介绍下吧。他们的主要区别就在于Layer的深度不一样,也就是Layer的数量。一般来说Layer越深,能学习到的特征就越多。但是Layer越多需要的数据量就越大,需要的计算资源也就更多。但是近几年大量可获得的数据的出现(ImageNet Datasets),更牛皮的GPU (NVIDIA),促进了Layer向更深的方向发展。
今天呢我还是会再举个栗子,通过下面这张图,把CNN涉及到的网络层的一些细节逐一介绍。
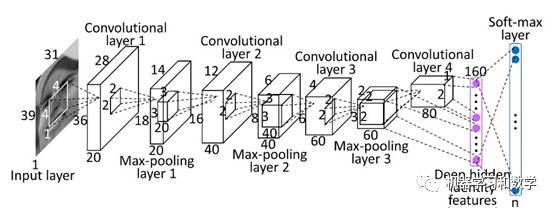
图1:卷积神经网络细节图(来源于网络)
我们从左往右逐个先大概浏览一下,首先是一张31x39x1大小的一张灰度图,然后通过4个Convolution layer,3个Pooling layer, 一个FC,最后是一个用于分类的SoftMax layer。如果换做彩色图,也是可以的,对于灰度图和彩色图处理上的区别,可能就在于最开始的通道数(channel number)不一样,其实并不影响什么,通过卷积之后得到的特征图(FeatureMaps),其实就是通道(channel)。
1. Inputs-->Convolutional layer1-->max-Pooling1
输入是一张图片,然后对他做一系列的处理计算,最后就能知道它是什么,比如说可以知道它是一个人头像的照片。
然后我们看一下细节的东西,图片的中间有一个4x4x1大小的卷积核。通过Convolutional layer 1得到一个28x36x20大小的Feature Maps。这里有个公式之前提到过,就是(31-4+1)x(39-4+1)=28x36。如果图片大小和卷积核大小变了,还是一样的计算方法哈。这里是没有加边缘的,就是之前提到过得Zero Padding,后面遇到了再说细节。为什么是20个Feature Maps呢?是因为它用了20个4x4大小的卷积核对图像做卷积处理。为什么要用20个呢?是因为特征图越多,可以学习到的特征就越多。那可不可以用更大的数字?可以的。但是不保证效果一定就好。
还是那句话,deep learning是一门实验性极强的学科,参数的设置都是要通过具体的问题,经过多次实验最终得到的。所以说做deep learning是一个很费时间,资源的工作。还记得我刚开始要学deep learning的时候,有人就说不建议一个人去搞这个,最好有个团队,因为无论从硬件和软件,都是一个挑战,我敢说国内很多大学的实验室,是没有相关的计算资源的。当时我就不明白为啥一个人不行,所以我傻乎乎的坚持学,哎,想想那个过程,都是泪!!!如果你现在的状态和我开始的时候是一样的,我建议keep going,you can do it better ! 打好基础,问题会一步步解决的!卷积层就说到这,下面再看一下Pooling。
你可能也注意到了,这张图写的Max-Pooling,也叫最大值池化。那有没有别的Pooling?有。还有一种但没有Max更常用的叫做均值Pooling,Mean-Pooling。从名称上应该就能体会到他们的区别,MaxPooling呢就是取池化窗口(Pooling Window)中最大的那个值最为新的值,MeanPooling呢就是取平均值。上图的Pooling Window的池化大小(Pooling size)是2x2,也就是一个window里面有4个值,对吧,然后max一下,就是把最大的取出来。先别想整幅图,就看这个2x2大小的图,Pooling之后相当于把长和宽都取了一半,对不对?2x2取最大值,那不就剩下1个数了,1个就是1x1大小。那么对于整副图来说,图片的大小也就变为原来的一半。那么问题来了,为什么要做Pooling?不做行不行?
一般来说,Pooling可以减小输入的大小,加速模型的训练过程。但是这样做会不会造成信息的损失呢?损失肯定是有的,但是相比如训练时间以及最后的准确度,这点损失几乎可以忽略。为什么可以忽略?那是因为图片具有“静态性”的属性,简单说就是一副图片相邻区域的特征几乎一样,想想实际生活中的图片正是这样的,你懂的!
然后说了这么多,貌似没有提到Activation,Activation一般是加在Convolutional后面,Activation的作用呢就是激活。怎么理解激活呢,从神经学的角度来说,有些神经元通过卷积之后可能就died了,所以激活一下,让他活过来。好了别闹了,我们处理的是图片,明显是无生命的东西。从数学的角度讲,Activation就是为了把一些丢失的值给变回来,来弥补Convolutional造成的信息的损失, Activation通常有很多种做法,不同的做法对应不同的激活函数(Activationfunction)。常见的之前提到过,比如softmax,relu,Leak relu,tanh,sigmoid等。区别是什么呢?这个各位看官自己去查一下吧,不难,就是几个数学公式,我举个栗子吧,不想单独讲一次了。比如我们的relu,公式是
F(x) = max(0, x)
是不是很简单!relu就是把输入x和0比较一下,取最大值,说白了就是把正数保留,负数变为0。函数图像就不画了,但是各位要去看一下哦~。
图2: (./copy图1.sh )(方便看)
2. Convolutional layer 4--> Deephidden identity features
在这个之前把1 Inputs-->Convolutional layer1-->max-Pooling1再double一下就可以了,计算方法完全一样,其实你也可以triple kill,quadruple kill,甚至 penta kill一下。都是没得问题的。只不过需要注意的是,不论你用什么框架,TensorFlow,Keras,还是Caffe,还是别的,都要注意他们先后的参数设置,要保证正确。如果不正确就会导致前一个Layer的输出无法作为后一个Layer的输入,说白了就是要匹配。如果不懂,可以去尝试写n个这样的循环,先不考虑最后分类的结果怎么样,n你自己定,然后你就明白了。(为了让大家动手写,我也是操碎了心呐!)
到了Convolutional 4的时候,原始图片变为了80个1x2的Feature Maps。最后这个FC稍微有点特殊,特殊之处在于他的一部分是Convolutional layer 4,一部分是Max-Pooling layer 3。暂且可以不考虑那么多,就说Convolutionallayer 4,他经过FC之后,变为80x2x1=160维特征的一个特征向量。Deep hidden identity features就是经过前面这一系列完美(乱七八糟)的计算得到的深层的关于输入图像的特征。到这里应该明白了什么是FC,简单说就是把上一个layer的特征全部铺平(Dense)了。
关于特征(Features)其实坑点也挺多的,在Machine Learning里面Feature selection 也是一个重要的课题,后面再讲吧。最后面的那个Soft-max layer,就是把FC做一个多分类回归,关于soft-max分类呢,他是sigmoid的一个推广,sigmoid一般解决二分类问题,而soft-max呢是多分类。细节请关注后续分享!
关于CNN网络层的知识有哪些就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/alvinpy/blog/4392379



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



