FlinkдҪҝз”ЁеӨ§зҠ¶жҖҒж—¶зҡ„дјҳеҢ–жҳҜд»Җд№Ҳ
жң¬зҜҮж–Үз« дёәеӨ§е®¶еұ•зӨәдәҶFlinkдҪҝз”ЁеӨ§зҠ¶жҖҒж—¶зҡ„дјҳеҢ–жҳҜд»Җд№ҲпјҢеҶ…е®№з®ҖжҳҺжүјиҰҒ并且容жҳ“зҗҶи§ЈпјҢз»қеҜ№иғҪдҪҝдҪ зңјеүҚдёҖдә®пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« зҡ„иҜҰз»Ҷд»Ӣз»ҚеёҢжңӣдҪ иғҪжңүжүҖ收иҺ·гҖӮ
дёҖгҖҒдёәд»Җд№ҲиҰҒдјҳеҢ–пјҹпјҲдјҳеҢ–иғҢжҷҜпјү
Flink ж”ҜжҢҒеӨҡз§Қ StateBackendпјҢеҪ“зҠ¶жҖҒжҜ”иҫғеӨ§ж—¶зӣ®еүҚеҸӘжңү RocksDBStateBackend еҸҜдҫӣйҖүжӢ©гҖӮ
RocksDB жҳҜеҹәдәҺ LSM ж ‘еҺҹзҗҶе®һзҺ°зҡ„ KV ж•°жҚ®еә“пјҢLSM ж ‘иҜ»ж”ҫеӨ§й—®йўҳжҜ”иҫғдёҘйҮҚпјҢеӣ жӯӨеҜ№зЈҒзӣҳжҖ§иғҪиҰҒжұӮжҜ”иҫғй«ҳпјҢејәзғҲе»әи®®з”ҹдә§зҺҜеўғдҪҝз”Ё SSD дҪңдёә RocksDB зҡ„еӯҳеӮЁд»ӢиҙЁгҖӮдҪҶжҳҜжңүдәӣйӣҶзҫӨеҸҜиғҪ并没жңүй…ҚзҪ® SSDпјҢд»…д»…жҳҜжҷ®йҖҡзҡ„жңәжў°зЎ¬зӣҳпјҢеҪ“ Flink д»»еҠЎжҜ”иҫғеӨ§пјҢдё”еҜ№зҠ¶жҖҒи®ҝй—®жҜ”иҫғйў‘з№Ғж—¶пјҢжңәжў°зЎ¬зӣҳзҡ„зЈҒзӣҳ IO еҸҜиғҪжҲҗдёәжҖ§иғҪ瓶йўҲгҖӮ еңЁиҝҷз§Қжғ…еҶөдёӢпјҢиҜҘеҰӮдҪ•и§ЈеҶіжӯӨ瓶йўҲе‘ўпјҹ
дҪҝз”ЁеӨҡеқ—зЎ¬зӣҳжқҘеҲҶжӢ…еҺӢеҠӣ RocksDB дҪҝз”ЁеҶ…еӯҳеҠ зЈҒзӣҳзҡ„ж–№ејҸеӯҳеӮЁж•°жҚ®пјҢеҪ“зҠ¶жҖҒжҜ”иҫғеӨ§ж—¶пјҢзЈҒзӣҳеҚ з”Ёз©әй—ҙдјҡжҜ”иҫғеӨ§гҖӮеҰӮжһңеҜ№ RocksDB жңүйў‘з№Ғзҡ„иҜ»еҸ–иҜ·жұӮпјҢйӮЈд№ҲзЈҒзӣҳ IO дјҡжҲҗдёә Flink д»»еҠЎз“¶йўҲгҖӮ
ејәзғҲе»әи®®еңЁ flink-conf.yaml дёӯй…ҚзҪ® state.backend.rocksdb.localdir еҸӮж•°жқҘжҢҮе®ҡ RocksDB еңЁзЈҒзӣҳдёӯзҡ„еӯҳеӮЁзӣ®еҪ• гҖӮеҪ“дёҖдёӘ TaskManager еҢ…еҗ« 3 дёӘ slot ж—¶пјҢйӮЈд№ҲеҚ•дёӘжңҚеҠЎеҷЁ дёҠзҡ„дёүдёӘ并иЎҢеәҰйғҪеҜ№зЈҒзӣҳйҖ жҲҗйў‘з№ҒиҜ»еҶҷпјҢд»ҺиҖҢеҜјиҮҙдёүдёӘ并иЎҢеәҰзҡ„д№Ӣй—ҙзӣёдә’дәүжҠўеҗҢдёҖдёӘзЈҒзӣҳ ioпјҢиҝҷж ·еҝ…е®ҡеҜјиҮҙдёүдёӘ并иЎҢеәҰзҡ„еҗһеҗҗйҮҸйғҪдјҡдёӢйҷҚгҖӮ
еәҶе№ёзҡ„жҳҜ Flink зҡ„ state.backend.rocksdb.localdir еҸӮж•°еҸҜд»ҘжҢҮе®ҡеӨҡдёӘзӣ®еҪ•пјҢдёҖиҲ¬еӨ§ж•°жҚ®жңҚеҠЎеҷЁйғҪдјҡжҢӮиҪҪеҫҲеӨҡеқ—зЎ¬зӣҳпјҢжҲ‘们жңҹжңӣеҗҢдёҖдёӘ TaskManager зҡ„дёүдёӘ slot дҪҝз”ЁдёҚеҗҢзҡ„зЎ¬зӣҳд»ҺиҖҢеҮҸе°‘иө„жәҗз«һдәүгҖӮе…·дҪ“еҸӮж•°й…ҚзҪ®еҰӮдёӢжүҖзӨәпјҡ
state.backend.rocksdb.localdir: /data1/flink/rocksdb,/data2/flink/rocksdb,/data3/flink/rocksdb,/data4/flink/rocksdb,/data5/flink/rocksdb,/data6/flink/rocksdb,/data7/flink/rocksdb,/data8/flink/rocksdb,/data9/flink/rocksdb,/data10/flink/rocksdb,/data11/flink/rocksdb,/data12/flink/rocksdb
жіЁж„Ҹпјҡ еҠЎеҝ…е°Ҷзӣ®еҪ•й…ҚзҪ®еҲ°еӨҡеқ—дёҚеҗҢзҡ„зЈҒзӣҳдёҠпјҢдёҚиҰҒй…ҚзҪ®еҚ•еқ—зЈҒзӣҳзҡ„еӨҡдёӘзӣ®еҪ•пјҢиҝҷйҮҢй…ҚзҪ®еӨҡдёӘзӣ®еҪ•жҳҜдёәдәҶи®©еӨҡеқ—зЈҒзӣҳжқҘеҲҶжӢ…еҺӢеҠӣгҖӮ
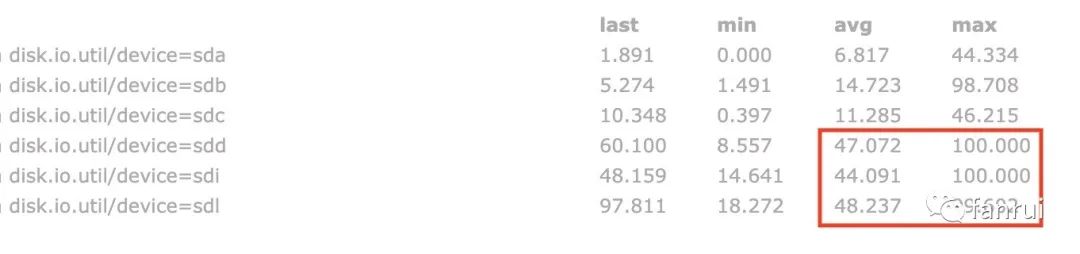
еҰӮдёӢеӣҫжүҖзӨәжҳҜ笔иҖ…жөӢиҜ•иҝҮзЁӢдёӯзЈҒзӣҳзҡ„ IO дҪҝз”ЁзҺҮпјҢеҸҜд»ҘзңӢеҮәдёүдёӘеӨ§зҠ¶жҖҒз®—еӯҗзҡ„并иЎҢеәҰеҲҶеҲ«еҜ№еә”дәҶдёүеқ—зЈҒзӣҳпјҢиҝҷдёүеқ—зЈҒзӣҳзҡ„ IO е№іеқҮдҪҝз”ЁзҺҮйғҪдҝқжҢҒеңЁ 45% е·ҰеҸіпјҢIO жңҖй«ҳдҪҝз”ЁзҺҮеҮ д№ҺйғҪжҳҜ 100%пјҢиҖҢе…¶д»–зЈҒзӣҳзҡ„ IO е№іеқҮдҪҝз”ЁзҺҮдёә 10% е·ҰеҸіпјҢзӣёеҜ№дҪҺеҫҲеӨҡгҖӮз”ұжӯӨеҸҜи§ҒдҪҝз”Ё RocksDB еҒҡдёәзҠ¶жҖҒеҗҺз«Ҝдё”жңүеӨ§зҠ¶жҖҒзҡ„йў‘з№ҒиҜ»еҶҷж“ҚдҪңж—¶пјҢеҜ№зЈҒзӣҳ IO жҖ§иғҪж¶ҲиҖ—зЎ®е®һжҜ”иҫғеӨ§гҖӮ
дёҠиҝ°еұһдәҺзҗҶжғіжғ…еҶөпјҢеҪ“и®ҫзҪ®еӨҡдёӘ RocksDB жң¬ең°зЈҒзӣҳзӣ®еҪ•ж—¶пјҢFlink дјҡйҡҸжңәйҖүжӢ©иҰҒдҪҝз”Ёзҡ„зӣ®еҪ•пјҢжүҖд»Ҙе°ұеҸҜиғҪеӯҳеңЁдёүдёӘ并иЎҢеәҰе…ұз”ЁеҗҢдёҖзӣ®еҪ•зҡ„жғ…еҶөгҖӮ
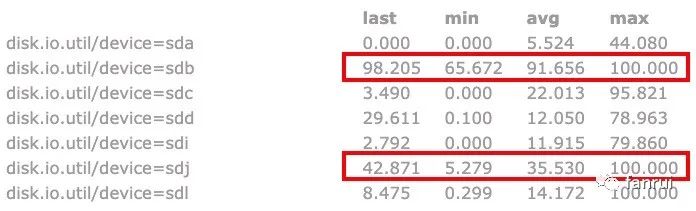
еҰӮдёӢеӣҫжүҖзӨәпјҢе…¶дёӯдёӨдёӘ并иЎҢеәҰе…ұз”ЁдәҶ sdb зЈҒзӣҳпјҢдёҖдёӘ并иЎҢеәҰдҪҝз”Ё sdj зЈҒзӣҳгҖӮеҸҜд»ҘзңӢеҲ° sdb зЈҒзӣҳзҡ„ IO е№іеқҮдҪҝз”ЁзҺҮе·Із»ҸиҫҫеҲ°дәҶ 91.6%пјҢжӯӨж—¶ sdb зҡ„зЈҒзӣҳ IO иӮҜе®ҡдјҡжҲҗдёәж•ҙдёӘ Flink д»»еҠЎзҡ„瓶йўҲпјҢдјҡеҜјиҮҙ sdb зЈҒзӣҳеҜ№еә”зҡ„дёӨдёӘ并иЎҢеәҰеҗһеҗҗйҮҸеӨ§еӨ§йҷҚдҪҺпјҢд»ҺиҖҢдҪҝеҫ—ж•ҙдёӘ Flink д»»еҠЎеҗһеҗҗйҮҸйҷҚдҪҺгҖӮ
еҰӮжһңжңҚеҠЎеҷЁжҢӮиҪҪзҡ„зЎ¬зӣҳж•°йҮҸиҫғеӨҡпјҢдёҖиҲ¬дёҚдјҡеҮәзҺ°иҜҘжғ…еҶөпјҢдҪҶжҳҜеҰӮжһңд»»еҠЎйҮҚеҗҜеҗҺеҗһеҗҗйҮҸиҫғдҪҺпјҢеҸҜд»ҘжЈҖжҹҘжҳҜеҗҰеҸ‘з”ҹдәҶеӨҡдёӘ并иЎҢеәҰе…ұз”ЁеҗҢдёҖеқ—зЈҒзӣҳзҡ„жғ…еҶөгҖӮ
Flink еҸҜиғҪдјҡеҮәзҺ°еӨҡдёӘ并иЎҢеәҰе…ұз”ЁеҗҢдёҖеқ—зЈҒзӣҳзҡ„й—®йўҳпјҢйӮЈиҜҘеҰӮдҪ•и§ЈеҶіе‘ўпјҹ
д»ҺзҺ°иұЎжқҘзңӢпјҢдёә RocksDB еҲҶй…ҚдәҶ 12 еқ—зЈҒзӣҳпјҢд»…д»…жңү 3 дёӘ并иЎҢеәҰйңҖиҰҒдҪҝз”Ё 3 еқ—зЈҒзӣҳпјҢдҪҶжҳҜжңүдёҖе®ҡеҮ зҺҮ 2 дёӘ并иЎҢеәҰе…ұз”ЁеҗҢдёҖеқ—зЈҒзӣҳпјҢз”ҡиҮіеҸҜиғҪдјҡжңүеҫҲе°Ҹзҡ„еҮ зҺҮ 3 дёӘ并иЎҢеәҰе…ұз”ЁеҗҢдёҖеқ—зЈҒзӣҳгҖӮиҝҷж ·жҲ‘们зҡ„ Flink д»»еҠЎеҫҲе®№жҳ“еӣ дёәзЈҒзӣҳ IO жҲҗдёә瓶йўҲгҖӮ
дёҠиҝ°еҲҶй…ҚзЈҒзӣҳзҡ„зӯ–з•ҘпјҢе®һйҷ…дёҠе°ұжҳҜдёҡз•Ңзҡ„иҙҹиҪҪеқҮиЎЎзӯ–з•ҘгҖӮйҖҡз”Ёзҡ„иҙҹиҪҪеқҮиЎЎзӯ–з•Ҙжңү hashгҖҒйҡҸжңәд»ҘеҸҠиҪ®еҫӘзӯүзӯ–з•ҘгҖӮ
Hash зӯ–з•Ҙ д»»еҠЎжң¬иә«з»ҸиҝҮжҹҗз§Қ hash зӯ–з•ҘеҗҺпјҢе°ҶеҺӢеҠӣеҲҶжӢ…еҲ°еӨҡдёӘ Worker дёҠгҖӮеҜ№еә”еҲ°дёҠиҝ°еңәжҷҜпјҢе°ұжҳҜе°ҶеӨҡдёӘ slot дҪҝз”Ёзҡ„ RocksDB зӣ®еҪ•еҺӢеҠӣеҲҶжӢ…еҲ°еӨҡеқ—зЈҒзӣҳдёҠгҖӮдҪҶжҳҜ hash еҸҜиғҪдјҡжңүеҶІзӘҒзҡ„жғ…еҶөпјҢhash еҶІзӘҒиЎЁзӨәеӨҡдёӘдёҚеҗҢзҡ„ Flink 并иЎҢеәҰпјҢз»ҸиҝҮ hash еҗҺеҫ—еҲ°зҡ„ hashCode дёҖж ·пјҢжҲ–иҖ… hashCode еҜ№зЎ¬зӣҳж•°йҮҸжұӮдҪҷеҗҺиў«еҲҶй…ҚеҲ°еҗҢдёҖеқ—зЎ¬зӣҳгҖӮ
Random зӯ–з•Ҙ йҡҸжңәзӯ–з•ҘжҳҜжҜҸжқҘдёҖдёӘ Flink д»»еҠЎпјҢз”ҹжҲҗдёҖдёӘйҡҸжңәж•°пјҢе°ҶеҺӢеҠӣйҡҸжңәеҲҶй…ҚеҲ°жҹҗдёӘ Worker дёҠпјҢд№ҹе°ұжҳҜе°ҶеҺӢеҠӣйҡҸжңәеҲҶй…ҚеҲ°жҹҗеқ—зЈҒзӣҳгҖӮдҪҶжҳҜйҡҸжңәж•°д№ҹдјҡеӯҳеңЁеҶІзӘҒзҡ„жғ…еҶөгҖӮ
Round Robin зӯ–з•Ҙ иҪ®еҫӘзӯ–з•ҘжҜ”иҫғе®№жҳ“зҗҶи§ЈпјҢеӨҡдёӘ Worker иҪ®жөҒжҺҘ收数жҚ®еҚіеҸҜпјҢFlink д»»еҠЎз¬¬дёҖж¬Ўз”іиҜ· RocksDB зӣ®еҪ•ж—¶дҪҝз”Ёзӣ®еҪ•1пјҢ第дәҢж¬Ўз”іиҜ·зӣ®еҪ•ж—¶дҪҝз”Ёзӣ®еҪ•2пјҢдҫқж¬Ўз”іиҜ·еҚіеҸҜгҖӮиҜҘзӯ–з•ҘжҳҜеҲҶй…Қд»»еҠЎж•°жңҖеқҮеҢҖзҡ„зӯ–з•ҘпјҢеҰӮжһңдҪҝз”ЁиҜҘзӯ–з•ҘдјҡдҝқиҜҒжүҖжңүзЎ¬зӣҳеҲҶй…ҚеҲ°зҡ„д»»еҠЎж•°зӣёе·®жңҖеӨ§дёә 1гҖӮ
жңҖдҪҺиҙҹиҪҪзӯ–з•Ҙ / Least Response TimeпјҲжңҖзҹӯе“Қеә”ж—¶й—ҙ пјүзӯ–з•Ҙ ж №жҚ® Worker зҡ„е“Қеә”ж—¶й—ҙжқҘеҲҶй…Қд»»еҠЎпјҢе“Қеә”ж—¶й—ҙзҹӯиҜҙжҳҺиҙҹиҪҪиғҪеҠӣејәпјҢеә”иҜҘеӨҡеҲҶй…ҚдёҖдәӣд»»еҠЎгҖӮеҜ№еә”еҲ°дёҠиҝ°еңәжҷҜе°ұжҳҜжЈҖжөӢеҗ„дёӘзЈҒзӣҳзҡ„ IO дҪҝз”ЁзҺҮпјҢдҪҝз”ЁзҺҮдҪҺиЎЁзӨәзЈҒзӣҳ IO жҜ”иҫғз©әй—ІпјҢеә”иҜҘеӨҡеҲҶй…Қд»»еҠЎгҖӮ
жҢҮе®ҡжқғйҮҚзӯ–з•Ҙ дёәжҜҸдёӘ Worker еҲҶй…ҚдёҚеҗҢзҡ„жқғйҮҚеҖјпјҢжқғйҮҚеҖјй«ҳзҡ„д»»еҠЎеҲҶй…ҚжӣҙеӨҡзҡ„д»»еҠЎпјҢдёҖиҲ¬еҲҶй…Қзҡ„д»»еҠЎж•°дёҺжқғйҮҚеҖјжҲҗжӯЈжҜ”гҖӮ
дҫӢеҰӮ Worker0 жқғйҮҚеҖјдёә 2пјҢWorker1 жқғйҮҚдёә 1пјҢеҲҷеҲҶй…Қд»»еҠЎж—¶ Worker0 еҲҶй…Қзҡ„д»»еҠЎж•°е°ҪйҮҸеҲҶй…ҚжҲҗ Worker1 д»»еҠЎж•°зҡ„дёӨеҖҚгҖӮиҜҘзӯ–з•ҘеҸҜиғҪ并дёҚйҖӮеҗҲеҪ“еүҚдёҡеҠЎеңәжҷҜпјҢдёҖиҲ¬зӣёеҗҢжңҚеҠЎеҷЁдёҠжҜҸдёӘзЎ¬зӣҳзҡ„иҙҹиҪҪиғҪеҠӣзӣёе·®дёҚдјҡеҫҲеӨ§пјҢйҷӨйқһ RocksDB зҡ„ local dir ж—ўеҢ…еҗ« SSD д№ҹеҢ…еҗ« HDDгҖӮ
дёүгҖҒжәҗз ҒдёӯеҰӮдҪ•еҲҶй…ҚзЈҒзӣҳпјҹ
笔иҖ…зәҝдёҠдҪҝз”Ё Flink 1.8.1 зүҲжң¬пјҢеҮәзҺ°дәҶжңүдәӣзЎ¬зӣҳеҲҶй…ҚдәҶеӨҡдёӘ并иЎҢеәҰпјҢжңүдәӣзЎ¬зӣҳдёҖдёӘ并иЎҢеәҰйғҪжІЎжңүеҲҶй…ҚгҖӮеҸҜд»ҘеӨ§иғҶзҡ„зҢңжөӢдёҖдёӢпјҢжәҗз ҒдёӯдҪҝз”Ё hash жҲ–иҖ… random зҡ„жҰӮзҺҮжҜ”иҫғй«ҳпјҢеӣ дёәеӨ§еӨҡж•°жғ…еҶөдёӢпјҢжҜҸдёӘзЎ¬зӣҳеҸӘеҲҶеҲ°дёҖдёӘд»»еҠЎпјҢе°ҸеҮ зҺҮеҲҶй…ҚеӨҡдёӘд»»еҠЎпјҲиҰҒи§ЈеҶізҡ„е°ұжҳҜиҝҷдёӘе°ҸеҮ зҺҮеҲҶй…ҚеӨҡдёӘд»»еҠЎзҡ„й—®йўҳпјүгҖӮ
еҰӮжһңдҪҝз”ЁиҪ®еҫӘзӯ–з•ҘпјҢиӮҜе®ҡдјҡдҝқиҜҒжҜҸдёӘзЎ¬зӣҳйғҪеҲҶй…ҚдёҖдёӘ并иЎҢеәҰд»ҘеҗҺпјҢжүҚдјҡеҮәзҺ°еҚ•зЎ¬зӣҳеҲҶй…ҚдёӨдёӘд»»еҠЎзҡ„жғ…еҶөгҖӮиҖҢдё”иҪ®еҫӘзӯ–з•ҘеҸҜд»ҘдҝқиҜҒеҲҶй…Қзҡ„зЎ¬зӣҳжҳҜиҝһз»ӯзҡ„гҖӮ
зӣҙжҺҘзңӢ RocksDBStateBackend зұ»зҡ„йғЁеҲҶжәҗз Ғпјҡ
/** Base paths for RocksDB directory, as initialized.иҝҷйҮҢе°ұжҳҜжҲ‘们дёҠиҝ°и®ҫзҪ®зҡ„ 12 дёӘ rocksdb local dir */private transient File[] initializedDbBasePaths;/** The index of the next directory to be used from {@link #initializedDbBasePaths}.дёӢдёҖж¬ЎиҰҒдҪҝз”Ё dir зҡ„ indexпјҢеҰӮжһң nextDirectory = 2пјҢеҲҷдҪҝз”Ё initializedDbBasePaths дёӯдёӢж Үдёә 2 зҡ„йӮЈдёӘзӣ®еҪ•еҒҡдёә rocksdb зҡ„еӯҳеӮЁзӣ®еҪ• */private transient int nextDirectory;// lazyInitializeForJob ж–№жі•дёӯпјҢ йҖҡиҝҮиҝҷдёҖиЎҢд»Јз ҒеҶіе®ҡдёӢдёҖж¬ЎиҰҒдҪҝз”Ё dir зҡ„ indexпјҢ// ж №жҚ® initializedDbBasePaths.length з”ҹжҲҗйҡҸжңәж•°пјҢ// еҰӮжһң initializedDbBasePaths.length = 12пјҢз”ҹжҲҗйҡҸжңәж•°зҡ„иҢғеӣҙдёә 0-11nextDirectory = new Random().nextInt(initializedDbBasePaths.length);
еҲҶжһҗе®Ңз®ҖеҚ•зҡ„жәҗз ҒеҗҺпјҢжҲ‘们зҹҘйҒ“дәҶжәҗз ҒдёӯдҪҝз”ЁдәҶ random зҡ„зӯ–з•ҘжқҘеҲҶй…Қ dirпјҢи·ҹжҲ‘们жүҖзңӢеҲ°зҡ„зҺ°иұЎиғҪеӨҹеҢ№й…ҚгҖӮйҡҸжңәеҲҶй…Қжңүе°ҸжҰӮзҺҮдјҡеҮәзҺ°еҶІзӘҒгҖӮпјҲеҶҷиҝҷзҜҮж–Үз« ж—¶пјҢFlink жңҖж–°зҡ„ master еҲҶж”Ҝд»Јз Ғд»Қ然жҳҜдёҠиҝ°зӯ–з•ҘпјҢе°ҡжңӘеҒҡд»»дҪ•ж”№еҠЁпјү
еӣӣгҖҒдҪҝз”Ёе“Әз§Қзӯ–з•ҘжӣҙеҗҲзҗҶпјҹ
пјҲеҗ„з§Қзӯ–з•ҘеёҰжқҘзҡ„жҢ‘жҲҳпјү
random е’Ң hash зӯ–з•ҘеңЁд»»еҠЎж•°йҮҸжҜ”иҫғеӨ§ж—¶пјҢеҸҜд»ҘдҝқиҜҒжҜҸдёӘ Worker жүҝжӢ…зҡ„д»»еҠЎйҮҸеҹәжң¬дёҖж ·пјҢдҪҶжҳҜеҰӮжһңд»»еҠЎйҮҸжҜ”иҫғе°ҸпјҢдҫӢеҰӮе°Ҷ 20 дёӘд»»еҠЎйҖҡиҝҮйҡҸжңәз®—жі•еҲҶй…Қз»ҷ 10 дёӘ Worker ж—¶пјҢе°ұдјҡеҮәзҺ°жңүзҡ„ Worker еҲҶй…ҚдёҚеҲ°д»»еҠЎпјҢжңүзҡ„ Worker еҸҜиғҪеҲҶй…ҚеҲ° 3 жҲ– 4 дёӘд»»еҠЎгҖӮжүҖд»Ҙ random е’Ң hash зӯ–з•ҘдёҚиғҪи§ЈеҶі rocksdb еҲҶй…ҚзЈҒзӣҳдёҚеқҮзҡ„з—ӣзӮ№пјҢйӮЈиҪ®еҫӘзӯ–з•Ҙе’ҢжңҖдҪҺиҙҹиҪҪзӯ–з•Ҙе‘ўпјҹ
иҪ®еҫӘзӯ–з•Ҙ иҪ®еҫӘзӯ–з•ҘеҸҜд»Ҙи§ЈеҶідёҠиҝ°й—®йўҳпјҢи§ЈеҶіж–№ејҸеҰӮдёӢпјҡ
// еңЁ RocksDBStateBackend зұ»дёӯе®ҡд№үдәҶprivate static final AtomicInteger DIR_INDEX = new AtomicInteger(0);// nextDirectory зҡ„еҲҶй…Қзӯ–з•ҘеҸҳжҲҗдәҶеҰӮдёӢд»Јз ҒпјҢжҜҸж¬Ўе°Ҷ DIR_INDEX + 1пјҢ然еҗҺеҜ№ dir зҡ„жҖ»ж•°жұӮдҪҷnextDirectory = DIR_INDEX.getAndIncrement() % initializedDbBasePaths.length;
йҖҡиҝҮдёҠиҝ°еҚіеҸҜе®һзҺ°иҪ®еҫӘзӯ–з•ҘпјҢз”іиҜ·зЈҒзӣҳж—¶пјҢд»Һ 0 еҸ·зЈҒзӣҳејҖе§Ӣз”іиҜ·пјҢжҜҸж¬ЎдҪҝз”ЁдёӢдёҖеқ—зЈҒзӣҳеҚіеҸҜгҖӮ
в– еёҰжқҘзҡ„й—®йўҳпјҡ
Java дёӯйқҷжҖҒеҸҳйҮҸеұһдәҺ JVM зә§еҲ«зҡ„пјҢжҜҸдёӘ TaskManager еұһдәҺеҚ•зӢ¬зҡ„ JVMпјҢжүҖд»Ҙ TaskManager еҶ…йғЁдҝқиҜҒдәҶиҪ®еҫӘзӯ–з•ҘгҖӮеҰӮжһңеҗҢдёҖеҸ°жңҚеҠЎеҷЁдёҠиҝҗиЎҢеӨҡдёӘ TaskManagerпјҢйӮЈд№ҲеӨҡдёӘ TaskManager йғҪдјҡд»Һ index дёә 0 зҡ„зЈҒзӣҳејҖе§ӢдҪҝз”ЁпјҢжүҖд»ҘеҜјиҮҙ index иҫғе°Ҹзҡ„зЈҒзӣҳдјҡиў«з»ҸеёёдҪҝз”ЁпјҢиҖҢ index иҫғеӨ§зҡ„зЈҒзӣҳеҸҜиғҪз»ҸеёёдёҚдјҡиў«дҪҝз”ЁеҲ°гҖӮ
в– и§ЈеҶіж–№жЎҲ 1пјҡ
DIR_INDEX еҲқе§ӢеҢ–ж—¶пјҢдёҚиҰҒжҜҸж¬ЎеҲқе§ӢеҢ–дёә 0пјҢеҸҜд»Ҙз”ҹжҲҗдёҖдёӘйҡҸжңәж•°пјҢиҝҷж ·еҸҜд»ҘдҝқиҜҒдёҚдјҡжҜҸж¬ЎдҪҝз”Ё index иҫғе°Ҹзҡ„зЈҒзӣҳпјҢе®һзҺ°д»Јз ҒеҰӮдёӢжүҖзӨәпјҡ
// еңЁ RocksDBStateBackend зұ»дёӯе®ҡд№үдәҶprivate static final AtomicInteger DIR_INDEX = new AtomicInteger(new Random().nextInt(100));
дҪҶжҳҜдёҠиҝ°ж–№жЎҲдёҚиғҪе®Ңе…Ёи§ЈеҶізЈҒзӣҳеҶІзӘҒзҡ„й—®йўҳпјҢеҗҢдёҖеҸ°жңәеҷЁдёҠ 12 еқ—зЈҒзӣҳпјҢTaskManager0 дҪҝз”Ё index дёә 0гҖҒ1гҖҒ2 зҡ„дёүеқ—зЈҒзӣҳпјҢTaskManager1 еҸҜиғҪдҪҝз”Ё index дёә 1гҖҒ2гҖҒ3 зҡ„дёүеқ—зЈҒзӣҳгҖӮз»“жһңе°ұжҳҜ TaskManager еҶ…йғЁжқҘзңӢпјҢе®һзҺ°дәҶиҪ®еҫӘзӯ–з•ҘдҝқиҜҒиҙҹиҪҪеқҮиЎЎпјҢдҪҶжҳҜе…ЁеұҖжқҘзңӢпјҢиҙҹиҪҪ并дёҚеқҮиЎЎгҖӮ
в– и§ЈеҶіж–№жЎҲ 2пјҡ
дёәдәҶе…ЁеұҖиҙҹиҪҪеқҮиЎЎпјҢжүҖд»ҘеӨҡдёӘ TaskManager д№Ӣй—ҙеҝ…йЎ»йҖҡдҝЎжүҚиғҪеҒҡеҲ°з»қеҜ№зҡ„иҙҹиҪҪеқҮиЎЎпјҢеҸҜд»ҘеҖҹеҠ©з¬¬дёүж–№зҡ„еӯҳеӮЁиҝӣиЎҢйҖҡдҝЎпјҢдҫӢеҰӮеңЁ Zookeeper дёӯпјҢдёәжҜҸдёӘжңҚеҠЎеҷЁз”ҹжҲҗдёҖдёӘ znodeпјҢznode е‘ҪеҗҚеҸҜд»ҘжҳҜ host жҲ–иҖ… ipгҖӮдҪҝз”Ё Curator зҡ„ DistributedAtomicInteger жқҘз»ҙжҠӨ DIR_INDEX еҸҳйҮҸпјҢеӯҳеӮЁеңЁеҪ“еүҚжңҚеҠЎеҷЁеҜ№еә”зҡ„ znode дёӯпјҢж— и®әжҳҜе“ӘдёӘ TaskManager з”іиҜ·зЈҒзӣҳпјҢйғҪеҸҜд»ҘдҪҝз”Ё DistributedAtomicInteger е°ҶеҪ“еүҚжңҚеҠЎеҷЁеҜ№еә”зҡ„ DIR_INDEX + 1пјҢд»ҺиҖҢе°ұеҸҜд»Ҙе®һзҺ°е…ЁеұҖзҡ„иҪ®еҫӘзӯ–з•ҘгҖӮ
DistributedAtomicInteger зҡ„ increment зҡ„жҖқи·Ҝ пјҡе…ҲдҪҝз”Ё Zookeeper зҡ„ withVersion api иҝӣиЎҢ +1 ж“ҚдҪңпјҲд№ҹе°ұжҳҜ Zookeeper жҸҗдҫӣзҡ„ CAS apiпјүпјҢеҰӮжһңжҲҗеҠҹеҲҷжҲҗеҠҹпјӣеҰӮжһңеӨұиҙҘпјҢеҲҷдҪҝз”ЁеҲҶеёғејҸдә’ж–Ҙй”ҒиҝӣиЎҢ +1 ж“ҚдҪңгҖӮ
еҹәдәҺдёҠиҝ°жҸҸиҝ°пјҢжҲ‘们еҫ—еҲ°дёӨз§Қзӯ–з•ҘжқҘе®һзҺ°иҪ®еҫӘпјҢAtomicInteger еҸӘиғҪдҝқиҜҒ TaskManager еҶ…йғЁзҡ„иҪ®еҫӘпјҢдёҚиғҪдҝқиҜҒе…ЁеұҖиҪ®еҫӘгҖӮеҰӮжһңиҰҒеҹәдәҺе…ЁеұҖиҪ®еҫӘпјҢйңҖиҰҒеҖҹеҠ© Zookeeper жҲ–其他组件жқҘе®һзҺ°гҖӮеҰӮжһңеҜ№иҪ®еҫӘзӯ–з•ҘиҰҒжұӮжҜ”иҫғиӢӣеҲ»пјҢеҸҜд»ҘдҪҝз”ЁеҹәдәҺ Zookeeper зҡ„иҪ®еҫӘзӯ–з•ҘпјҢеҰӮжһңдёҚжғідҫқиө–еӨ–йғЁз»„件еҲҷеҸӘиғҪдҪҝз”Ё AtomicInteger жқҘе®һзҺ°гҖӮ
жңҖдҪҺиҙҹиҪҪзӯ–з•Ҙ жҖқжғіе°ұжҳҜ TaskManager еҗҜеҠЁж—¶пјҢзӣ‘жөӢжүҖжңү rocksdb local dir еҜ№еә”зҡ„зЈҒзӣҳжңҖиҝ‘ 1 еҲҶй’ҹжҲ– 5 еҲҶй’ҹзҡ„ IO е№іеқҮдҪҝз”ЁзҺҮпјҢзӯӣжҺү IO дҪҝз”ЁзҺҮиҫғй«ҳзҡ„зЈҒзӣҳпјҢдјҳе…ҲйҖүжӢ© IO е№іеқҮдҪҝз”ЁзҺҮиҫғдҪҺзҡ„зЈҒзӣҳпјҢеҗҢж—¶еңЁ IO е№іеқҮдҪҝз”ЁзҺҮиҫғдҪҺзҡ„зЈҒзӣҳдёӯпјҢдҫқ然иҰҒдҪҝз”ЁиҪ®еҫӘзӯ–з•ҘжқҘе®һзҺ°гҖӮ
в– йқўдёҙзҡ„й—®йўҳ Flink д»»еҠЎеҗҜеҠЁж—¶пјҢеҸӘиғҪжӢҝеҲ°зЈҒзӣҳеҪ“еүҚзҡ„ IO дҪҝз”ЁзҺҮпјҢжҳҜдёҖдёӘзһ¬ж—¶еҖјпјҢдјҡдёҚдјҡдёҚйқ и°ұпјҹ
Flink д»»еҠЎеҗҜеҠЁпјҢдёҚеҸҜиғҪзӯүеҫ…д»»еҠЎе…ҲйҮҮйӣҶ 1 еҲҶй’ҹ IO дҪҝз”ЁзҺҮд»ҘеҗҺпјҢеҶҚеҺ»еҗҜеҠЁгҖӮ
еҒҮи®ҫе·Із»ҸжӢҝеҲ°дәҶжүҖжңүзЎ¬зӣҳжңҖиҝ‘ 1 еҲҶй’ҹзҡ„ IO дҪҝз”ЁзҺҮпјҢиҜҘеҰӮдҪ•еҺ»еҶізӯ–е‘ўпјҹ
еҜ№дәҺ IO е№іеқҮдҪҝз”ЁзҺҮиҫғдҪҺзҡ„зЈҒзӣҳдёӯпјҢдҫқ然иҰҒдҪҝз”ЁиҪ®еҫӘзӯ–з•ҘжқҘе®һзҺ°гҖӮ
IO е№іеқҮдҪҝз”ЁзҺҮиҫғдҪҺпјҢиҝҷйҮҢзҡ„иҫғдҪҺдёҚеҘҪиҜ„еҲӨпјҢзӣёе·® 10% з®—дҪҺпјҢиҝҳжҳҜ 20%гҖҒ30%гҖӮ
иҖҢдё”дёҚеҗҢзҡ„ж–°д»»еҠЎеҜ№дәҺзЈҒзӣҳзҡ„дҪҝз”ЁзҺҮиҰҒжұӮд№ҹжҳҜдёҚдёҖж ·зҡ„пјҢжүҖд»ҘиҜ„еҲӨйҡҫеәҰиҫғеӨ§гҖӮ
в– ж–°жҖқи·ҜпјҲdiscussingпјү еҗҜеҠЁйҳ¶ж®өдёҚйҮҮйӣҶзЎ¬зӣҳзҡ„иҙҹиҪҪеҺӢеҠӣпјҢдҪҝз”Ёд№ӢеүҚзҡ„ DistributedAtomicInteger еҹәжң¬е°ұеҸҜд»ҘдҝқиҜҒжҜҸдёӘзЎ¬зӣҳиҙҹиҪҪеқҮиЎЎгҖӮдҪҶжҳҜд»»еҠЎеҗҜеҠЁеҗҺдёҖж®өж—¶й—ҙпјҢеҰӮжһңеӣ дёә Flink д»»еҠЎеҜјиҮҙжҹҗдёӘзЈҒзӣҳ IO зҡ„е№іеқҮдҪҝз”ЁзҺҮзӣёеҜ№е…¶д»–зЈҒзӣҳиҖҢиЁҖйқһеёёй«ҳгҖӮжҲ‘们еҸҜд»ҘйҖүжӢ©иҝҒ移й«ҳиҙҹиҪҪзЎ¬зӣҳзҡ„ж•°жҚ®еҲ°дҪҺиҙҹиҪҪзЎ¬зӣҳгҖӮ
дёҠиҝ°еҶ…е®№е°ұжҳҜFlinkдҪҝз”ЁеӨ§зҠ¶жҖҒж—¶зҡ„дјҳеҢ–жҳҜд»Җд№ҲпјҢдҪ 们еӯҰеҲ°зҹҘиҜҶжҲ–жҠҖиғҪдәҶеҗ—пјҹеҰӮжһңиҝҳжғіеӯҰеҲ°жӣҙеӨҡжҠҖиғҪжҲ–иҖ…дё°еҜҢиҮӘе·ұзҡ„зҹҘиҜҶеӮЁеӨҮпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ