这期内容当中小编将会给大家带来有关Apache Flink 1.11 功能有哪些呢,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
下面将详细介绍 1.11 版本的新功能、改进、重要变化及未来的发展计划。
在集群部署方面
1.[FLIP-85] Flink 支持 Application Mode
目前 Flink 是通过一个单独的客户端来创建 JobGraph 并提交作业的,在实际使用时,会产生下载作业 jar 包占用客户端机器大量带宽、需要启动单独进程(占用不受管理的资源)作为客户端等问题。为了解决这些问题,在 Flink-1.11 中提供了一种新的 Application 模式,它将 JobGraph 的生成以及作业的提交转移到 Master 节点进行。
用户可以通过 bin/flink run-application 来使用 application 模式。目前 Application 模式支持 Yarn 和 K8s 的部署方式,Yarn Application 模式会在客户端将运行任务需要的依赖都通过 Yarn Local Resource 传递到 Flink Master,然后在 Master 端进行任务的提交。K8s Application 允许用户构建包含用户 Jar 与依赖的镜像,同时会根据 job 自动创建 TaskManager,并在结束后销毁整个 Cluster。
2. [Flink-13938] [Flink-17632] Flink Yarn 支持远程 Flink lib Jar 缓存和使用远程 Jar 创建作业
1.11 之前 Flink 在 Yarn 上每提交一个作业都需要上传一次 Flink lib 下的 Jars,从而耗费额外的存储空间和通信带宽。Flink-1.11 允许用户提供多个远程的 lib 目录,这些目录下的文件会被缓存到 Yarn 的节点上,从而避免不必要的 Jar 包上传与下载,使提交和启动更快:
./bin/flink run -m yarn-cluster -d \-yD yarn.provided.lib.dirs=hdfs://myhdfs/flink/lib,hdfs://myhdfs/flink/plugins \examples/streaming/WindowJoin.jar
此外,1.11 还允许用户直接使用远程文件系统上的 Jar 包来创建作业,从而进一步减少 Jar 包下载的开销:
./bin/flink run-application -p 10 -t yarn-application \-yD yarn.provided.lib.dirs="hdfs://myhdfs/flink/lib" \hdfs://myhdfs/jars/WindowJoin.jar
3. [Flink-14460] Flink K8s 功能增强
在 1.11 中,Flink 对 K8s 除支持 FLIP-85 提出的 Application 模式,相比于 Session 模式,它具有更好的隔离性。
此外,Flink 还新增了一些功能用以支持 K8s 的特性,例如 Node Selector,Label,Annotation,Toleration 等。为了更方便的与 Hadoop 集成,也支持根据环境变量自动挂载 Hadoop 配置的功能。
4. [FLIP-111] docker 镜像统一
之前 Flink 项目中提供了多个不同的 Dockerfile 用来创建 Flink 的 Docker 镜像,现在他们被统一到了 apache/flink-docker [1] 项目中。
5. [Flink-15911][Flink-15154] 支持分别配置用于本地监听绑定的网络接口和外部访问的地址和端口
在部分使用场景中(例如 Docker、NAT 端口映射),JM/TM 进程看到的本地网络地址、端口,和其他进程用于从外部访问该进程的地址、端口可能是不一样的。之前 Flink 不允许用户为 TM/JM 设置不同的本地和远程地址,使 Flink 在 Docker 等使用的 NAT 网络中存在问题,并且不能限制监听端口的暴露范围。
1.11 中为本地和远程的监听地址和端口引入了不同的参数。其中:
* jobmanager.rpc.address
* jobmanager.rpc.port
* taskmanager.host
* taskmanager.rpc.port
* taskmanager.data.port
用来配置远程的监听地址和端口,
* jobmanager.bind-host
* jobmanager.rpc.bind-port
* taskmanager.bind-host
* taskmanager.rpc.bind-port
* taskmanager.data.bind-port
用来配置本地的监听地址和端口。
在资源管理方面
1. [Flink-16614] 统一 JM 端内存资源配置
Flink-1.10 中的一个大的改动是重新定义了 TM 内存模型与配置规则[2]。Flink 1.11 进一步对 JM 内存模型与配置规则进行了调整,使 JM 的内存配置方式与 TM 统一:
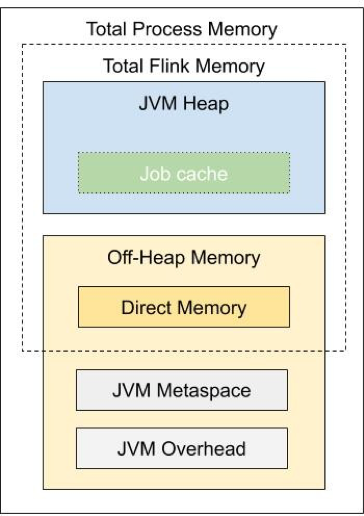
具体的内存配置方式可以参考相应的用户文档[3]。
2. [FLIP-108] 增加对扩展资源(如 GPU)的调度支持
随着机器学习和深度学习的发展,越来越多的 Flink 作业会嵌入机器学习或深度学习模型,从而产生对 GPU 资源的需求。1.11 之前 Flink 不支持对 GPU 这样的扩展资源进行管理。为了解决这一部分,在 1.11 中,Flink 提供了对扩展资源的统一管理框架,并基于这一框架内置了对 GPU 资源的支持。
关于扩展资源管理框架和 GPU 资源管理的进一步配置,可以参考相应的 FLIP 页面:https://cwiki.apache.org/confluence/display/FLINK/FLIP-108%3A+Add+GPU+support+in+Flink的Publlic interface 部分(相应的用户文档社区正在编写中,后续可以参考对应的用户文档)。
3. [FLINK-16605] 允许用户限制 Batch 作业的最大 slot 数量
为了避免 Flink Batch 作业占用过多的资源,Flink-1.11 引入了一个新的配置项:slotmanager.number-of-slots.max,它可以限定整个 Flink 集群 Slot 的最大数量。这一参数只推荐用于使用了 Blink Planner 的 Batch Table / SQL 作业。
Flink-1.11 WEB UI 的增强
1. [FLIP-103] 改善 Web UI 上 JM/TM 日志的展示
之前用户只能通过 Web UI 读取 .log 和 .out 日志,但是实际上在日志目录下可能还存在着其它文件,如 GC log 等。新版界面允许用户访问日志目录下的所有日志。此外,还增加了日志重新加载、下载和全屏展示的功能。
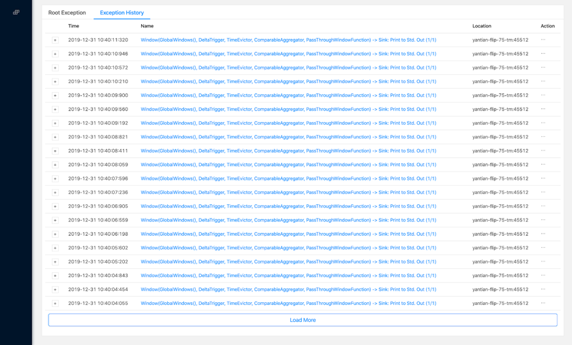
2. [FLIP-99] 允许展示更多的历史 Failover 异常
之前对于单个作业,Web UI 只能展示单个 20 条历史 Failover 异常,在作业频繁 Failover 时,最开始的异常(更有可能是 root cause)很快会被淹没,从而增加排查的难度。新版的 WEB UI 支持分页展示更多的历史异常。
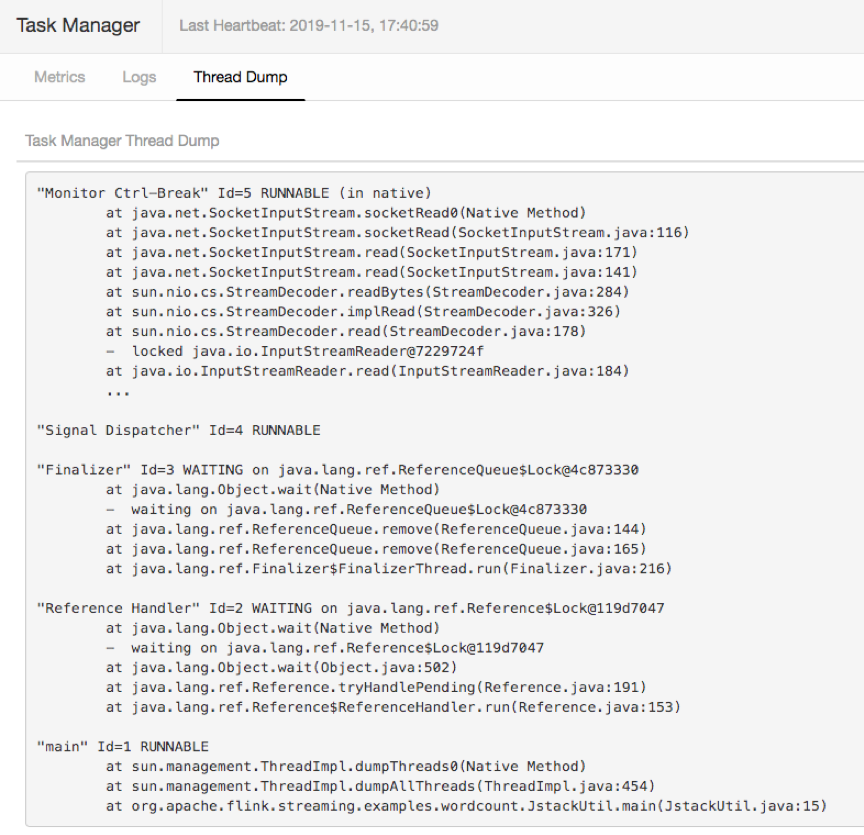
3. [Flink-14816] 允许用户直接在页面上进行 Thread Dump
Thread Dump 对一些作业的问题定位非常有帮助,1.11 之前用户必须要登录到 TM 所在机器来执行 Thread Dump 操作。1.11 的 WEB UI 集成了这一功能,它增加了 Thread dump 标签页,允许用户直接通过 WEB UI 来获得 TM 的 Thread Dump。
Source & Sink
FLIP-27 是 1.11 中一个较大的 Feature。Flink 传统的 Source 接口存在一定的问题,例如需要为流作业和批作业分别实现不同的 Source、没有统一的数据分区发现逻辑、需要 Source 实现者自己处理加锁逻辑以及没有提供公共架构使得 Source 开发者必须要手动处理多线程等问题。这些问题增加了 Flink 中实现 Source 的难度。
FLIP-27 引入了一套全新的 Source 的接口。这套接口提供了统一的数据分区发现和管理等功能,用户只需要集中在分区信息读取和数据读取等逻辑,而不需要再处理复杂线程同步问题,从而极大的简化了 Source 实现的负担,也为后续为 Source 提供更多内置功能提供了基础。
2. [FLINK-11395][Flink-10114] Streaming File Sink 新增对 Avro 和 ORC 格式的支持
对于常用的 StreamingFileSink,1.11 新增了对 Avro 和 ORC 两种常用文件格式的支持。
Avro:
stream.addSink(StreamingFileSink.forBulkFormat( Path.fromLocalFile(folder), AvroWriters.forSpecificRecord(Address.class)).build());
ORC:
OrcBulkWriterFactory<Record> factory = new OrcBulkWriterFactory<>( new RecordVectorizer(schema), writerProps, new Configuration());Stream.addSink(StreamingFileSink .forBulkFormat(new Path(outDir.toURI()), factory) .build());
State 管理
Flink-1.11 将 Savepoint 中的文件绝对路径替换为相对路径,从而使用户可以直接移动 Savepoint 的位置,而不需要再手动修改 meta 中的路径(注:在 S3 文件系统中启用 Entropy Injection 后不支持该功能)。
2. [FLINK-8871] 增加 Checkpoint 失败的回调并通知 TM 端
Flink 1.11之前提供了Checkpoint成功的通知。在1.11中新增了Checkpoint失败时通知TM端的机制,一方面可以取消正在进行中的Checkpoint,另外用户通过CheckpointListener新增的notifyCheckpointAborted接口也可以收到对应的通知。
3. [FLINK-12692] heap keyed Statebackend 支持溢出数据到磁盘
(该功能实际并未合并到 Flink 1.11 代码,但是用户可以从 https://flink-packages.org/packages/spillable-state-backend-for-flink下载试用。)
对于 Heap Statebackend,由于它将 state 直接以 Java 对象的形式维护,因此它可以获得较好的性能。但是,之前它 Heap State backend 占用的内存是不可控的,因引可以导致严重的 GC 问题。
为了解决这一问题,SpillableKeyedStateBackend 支持将数据溢出到磁盘,从而允许 Statebackend 限制所使用的内存大小。关于 SpillableKeyedStateBackend 的更多信息,可以参考 https://flink-packages.org/packages/spillable-state-backend-for-flink。
4. [Flink-15507] 对 Rocksdb Statebackend 默认启用 Local Recovery
默认启用 Local Recovery 后可以加速 Failover 的速度。
5. 修改 state.backend.fs.memory-threshold 参数默认值到 20k
(这部分工作还在进行中,但是应该会包含在 1.11 中)
state.backend.fs.memory-threshold 决定了 FS Statebackend 中什么时候需要将 State 数据写出去内存中。之前默认的 1k 在许多情况下会导致大量小文件的问题并且会影响 State 访问的性能,因此在 1.11 中该值被提高到了 20k。需要特别注意的是,这一改动可能会提高JM内存的使用量,尤其是在算子并发较大或者使用了UnionState的情况下。[4]
Table & SQL
相对于之前的类型推断机制,新版的类型推断机制可以提供关于输入参数的更多类型信息,从而允许用户实现更灵活的处理逻辑。目前这一功能提供了对 UDF 和 UTF 的支持,但暂时还不支持 UDAF。
2. [FLIP-84] 优化 TableEnvironment 的接口
Flink-1.11 对于 TableEnv 在以下方面进行了增强:
3. [FLIP-93] 支持基于 JDBC 和 Postgres的Catalog
1.11 之前用户使用Flink读取/写入关系型数据库或读取 Change Log 时,需要手动将数据库的表模式复制到 Flink 中。这一过程枯燥乏味且容易错,从而较大的的提高了用户的使用成本。1.11 提供了基于 JDBC 和 Postgres 的 Catalog 管理,使 Flink 可以自动读取表模式,从而减少了用户的手工操作。
4. [FLIP-105] 增加对 ChangeLog 源的支持
通过 Change Data Capture 机制(CDC)来将外部系统的动态数据(如 Mysql BinLog,Kafka Compacted Topic)导入 Flink,以及将 Flink 的 Update/Retract 流写出到外部系统中是用户一直希望的功能。Flink-1.11 实现了对 CDC 数据读取和写出的支持。目前 Flink 可以支持 Debezium 和 Canal 两种 CDC 格式。
5. [FLIP-95] 新的 TableSource 和 TableSink 接口
简化了当前 Table Source/Sink 的接口结构,为支持 CDC 功能提供了基础,避免了对 DataStream API 的依赖以及解决只有 Blink Planner 可以支持高效的 Source/Sink 实现的问题。
更具体接口变化可以参考:
https://cwiki.apache.org/confluence/display/FLINK/FLIP-95%3A+New+TableSource+and+TableSink+interfaces
6. [FLIP-122] 修改 Connector 配置项
FLIP-122 重新整理了 Table/SQL Connector 的”With”配置项。由于历史原因,With 配置项有一些冗余或不一致的地方,例如所有的配置项都以 connector. 开头以及不同的配置项名称模式等。修改后的配置项解决了这些冗余和不一致的问题。(需要强调的是,现有的配置项仍然可以正常使用)。
关于新的配置项的列表,可以参考:
https://cwiki.apache.org/confluence/display/FLINK/FLIP-122%3A+New+Connector+Property+Keys+for+New+Factory
7. [FLIP-113] Flink SQL 支持动态 Table 属性
动态 Table 属性允许用户在使用表时动态的修改表的配置项,从而避免用户由于配置项变化而需要重新声明表的 DDL 的麻烦。如下所示,动态属性允许用户在执行查询时通过 /*+ OPTIONS(‘k1’=’v1’)*/ 的语法来覆盖 DDL 中的属性值。
SELECT *FROM EMP /*+ OPTIONS('k1'='v1', 'k2'='v2') */ JOIN DEPT /*+ OPTIONS('a.b.c'='v3', 'd.e.f'='v4') */ON EMP.deptno = DEPT.deptno
8. [FLIP-115] 增加 Flink SQL 对 Hive 的支持
对于 FileSystem Connector 提供了对 csv/orc/parquet/json/avro 五种格式的支持,以及对 Batch 和 Streaming FileSystem Connector 的完整支持。
提供了对 Hive Streaming Sink 的支持。
9. [FLIP-123] 支持兼容 Hive 的 DDL 和 DML 语句
FLIP-123 提供了对 Hive 方言的支持,它使用户可以使用 Hive 的 DDL 和 DML 来进行操作。
DataStream API
(注意这部分工作已经完成,但是是否要包括在 1.11 中仍在讨论中)
新的 WatermarkAssigner 接口将之前的 AssignerWithPunctuatedWatermarks 和 AssignerWithPeriodicWatermarks 的两类 Watermark 的接口进行了整合,从而简化了后续开发支持插入 Watermark 的 Source 实现复杂度。
2. [FLIP-92] 支持超过两个输入的 Operator
Flink 1.11 提供了对多输入 Operator 的支持。但是,目前这一功能并没有提供完整的 DataStream API 的接口,用户如果想要使用的话,需要通过手动创建 MultipleInputTransformation 与 MultipleConnectedStreams 的方式进行:
MultipleInputTransformation<Long> transform = new MultipleInputTransformation<>("My Operator",new SumAllInputOperatorFactory(),BasicTypeInfo.LONG_TYPE_INFO,1);env.addOperator(transform.addInput(source1.getTransformation()).addInput(source2.getTransformation()).addInput(source3.getTransformation()));new MultipleConnectedStreams(env).transform(transform).addSink(resultSink);
PyFlink & ML
1. [FLINK-15636] 在 Flink Planner 的 batch 模式下支持 Python UDF 的运行
在此之前,Python UDF 可以运行在 Blink Planner 的流、批和 Flink Planner 的流模式下。支持后,两个 Planner 的流批模式都支持 Python UDF 的运行。
2. [FLINK-14500] Python UDTF 的支持
UDTF 支持单条写入多条输出。两个 Planner 的流批模式都支持 Python UDTF 的运行。
3. [FLIP-121] 通过 Cython 来优化 Python UDF 的执行效率
用 Cython 优化了 Coder(序列化、反序列化)和 Operation 的计算逻辑,端到端的性能比 1.10 版本提升了数十倍。
4. [FLIP-97] Pandas UDF 的支持
Pandas UDF 以 pandas.Series 作为输入和输出类型,支持批量处理数据。一般而言,Pandas UDF 比普通 UDF 的性能要更好,因为减少了 Java 和 Python 进程之间数据交互的序列化和反序列化开销,同时由于可以批量处理数据,也减少了 Python UDF 调用次数和调用开销。除此之外,用户使用 Pandas UDF 时,可以更方便自然地使用 Pandas 相关的 Python 库。
5. [FLIP-120] 支持 PyFlink Table 和 Pandas DataFrame 之间的转换
用户可以使用 Table 对象上的 to_pandas() 方法返回一个对应的 Pandas DataFrame 对象,或通过 from_pandas() 方法将一个 Pandas DataFrame 对象转换成一个 Table 对象。
import pandas as pdimport numpy as np# Create a PyFlink Tablepdf = pd.DataFrame(np.random.rand(1000, 2))table = t_env.from_pandas(pdf, ["a", "b"]).filter("a > 0.5")# Convert the PyFlink Table to a Pandas DataFramepdf = table.to_pandas()
6. [FLIP-112] 支持在 Python UDF 里定义用户自定义 Metric
目前支持 4 种自定义的 Metric 类型,包括:Counter, Gauges, Meters 和 Distributions。同时支持定义 Metric 相应的 User Scope 和 User Variables。
7. [FLIP-106][FLIP-114] 在 SQL DDL 和 SQL client 里支持 Python UDF 的使用
在此之前,Python UDF 只能在 Python Table API 里使用。支持 DDL 的方式注册 Python UDF 后,SQL 用户也能方便地使用 Python UDF。除此之外,也对 SQL Client 进行了 Python UDF 的支持,支持 Python UDF 注册及对 Python UDF 的依赖进行管理。
8. [FLIP-96] 支持 Python Pipeline API
Flink 1.9 里引入了一套新的 ML Pipeline API 来增强 Flink ML 的易用性和可扩展性。由于 Python 语言在 ML 领域的广泛使用,FLIP-96 提供了一套相应的 Python Pipeline API,以方便 Python 用户。
运行时优化
Flink 现有的 Checkpoint 机制下,每个算子需要等到收到所有上游发送的 Barrier 对齐后才可以进行 Snapshot 并继续向后发送 barrier。在反压的情况下,Barrier 从上游算子传送到下游可能需要很长的时间,从而导致 Checkpoint 超时的问题。
针对这一问题,Flink 1.11 增加了 Unaligned Checkpoint 机制。开启 Unaligned Checkpoint 后当收到第一个 barrier 时就可以执行 checkpoint,并把上下游之间正在传输的数据也作为状态保存到快照中,这样 checkpoint 的完成时间大大缩短,不再依赖于算子的处理能力,解决了反压场景下 checkpoint 长期做不出来的问题。
可以通过 env.getCheckpointConfig().enableUnalignedCheckpoints();开启unaligned Checkpoint 机制。
2. [FLINK-13417] 支持 Zookeeper 3.5
支持 Flink 与 ZooKeeper 3.5 集成。这将允许用户使用一些新的 Zookeeper 功能,如 SSL 等。
3. [FLINK-16408] 支持 Slot 级别的 Classloder 复用
Flink 1.11 修改了 TM 端 ClassLoader 的加载逻辑:与之前每次 Failover 后都会创建新的 ClassLoader 不同,1.11 中只要有这个作业占用的 Slot,相应的 ClassLoader 就会被缓存。这一修改对作业 Failover 的语义有一定的影响,因为 Failover 后 Static 字段不会被重新加载,但是它可以避免大量创建 ClassLoader 导致 JVM meta 内存耗尽的问题。
4. [FLINK-15672] 升级日志系统到 log4j 2
Flink 1.11 将日志系统 Log4j 升级到 2.x,从而可以解决 Log4j 1.x 版本存在的一些问题并使用 2.x 的一些新功能。
5. [FLINK-10742] 减少 TM 接收端的数据拷贝次数和内存占用
Flink-1.11 在下游网络接收数据时,通过复用 Flink 自身的 buffer 内存管理,减少了 netty 层向 Flink buffer 的内存拷贝以及因此带来的 direct memory 的额外开销,从而减少了线上作业发生 Direct Memory OOM 或者 Container 因为内存超用被 Kill 的机率。
上述就是小编为大家分享的Apache Flink 1.11 功能有哪些呢了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





