Apache Flink 误用的是示例分析,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
1. 项目开始
a) 从一个具有挑战性的用例开始(端对端的 Exactly-once、大状态、复杂的业务逻辑、强实时SLA的组合) b) 之前没有流处理经验 c) 不对团队做相关的培训 d) 不利用社区
邮件列表:
user@flink.apache.com/user-zh@flink.apache.org
Stack Overflow:
www.stackoverflow.com
2. 设计分析
a) 不考虑数据一致性和交付保证 b) 不考虑业务升级和应用改进 c) 不考虑业务规模问题 d) 不深入思考实际业务需求
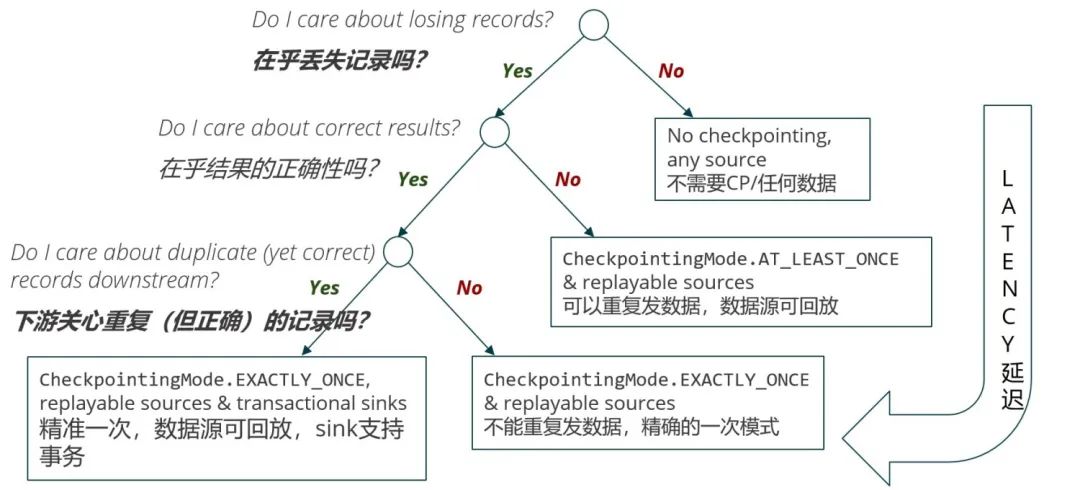
a 升级集群版本 b 业务 bug 的修复 c 业务逻辑(拓扑)的变更
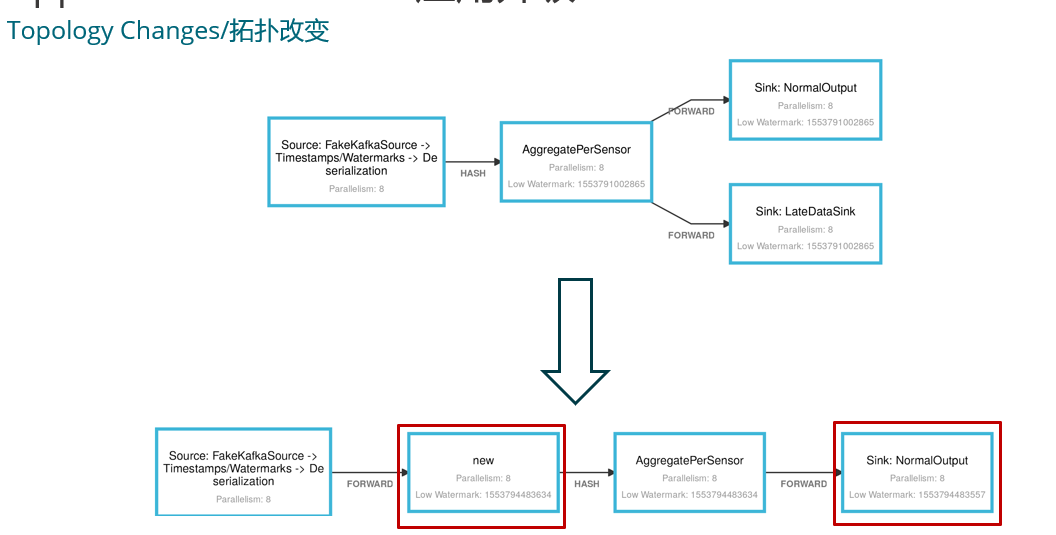
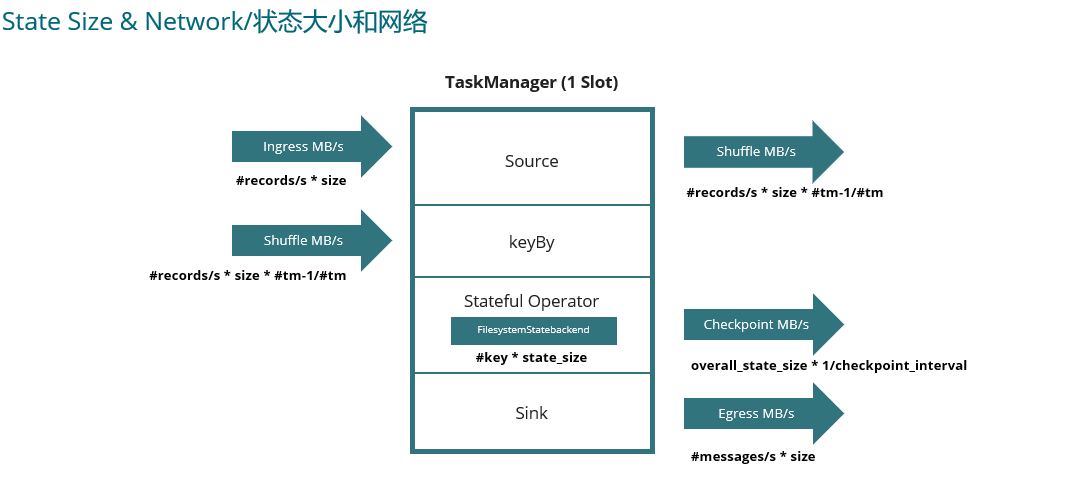
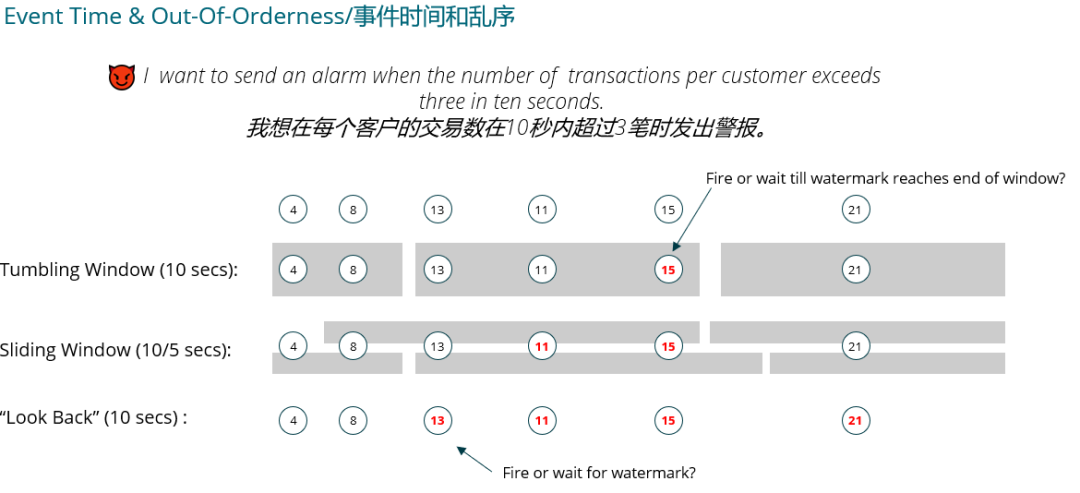
3. 开发
a) 在升级过程中要改变状态 b) 不能丢失迟到的数据 c) 在运行时更改程序的行为
3.2 数据类型
3.3 序列化

3.4 并发性
任务之间共享静态变量
在用户函数中生成线程
3.5 窗口




4. 测试
5. 上线
6. 维护
7.PyFlink/SQL/TableAPI 的补充
使用 TableEnvironment 还是 StreamTableEnvironment?推荐 TableEnvironment 。(分段优化)
State TTL 未设置,导致 State 无限增长,或者 State TTL 设置不结合业务需求,导致数据正确性问题。
不支持作业升级,例如增加一个 COUNT SUM 会导致作业 state 不兼容。
解析 JSON 时,重复调度 UDF,严重影响性能,建议替换成 UDTF。
多流 JOIN 的时候,先做小表 JOIN,再做大表 JOIN。目前,Flink 还没有表的 meta 信息,没法在 plan 优化时自动做 join reorder。
关于Apache Flink 误用的是示例分析问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





