这期内容当中小编将会给大家带来有关Google工程师的大数据处理方法论是什么,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
毫无疑问,Google是公认的大数据鼻祖。如今很多人提起大数据,还停留在 Google 开启的“三驾马车”时代:Google FS、MapReduce、BigTable。其实,“三驾马车”早已不是浪潮之巅。
近年来,大数据技术的发展,不论是技术迭代,还是生态圈的繁荣,都远超我们的想象。从 Spark 成为 Hadoop 生态的一部分,到 Flink 横空出世挑战 Spark 成为大数据处理领域的新星,再到如今 Google 又决心用 Apache Beam 一统天下。大数据技术的发展可谓跌宕起伏,波澜壮阔。
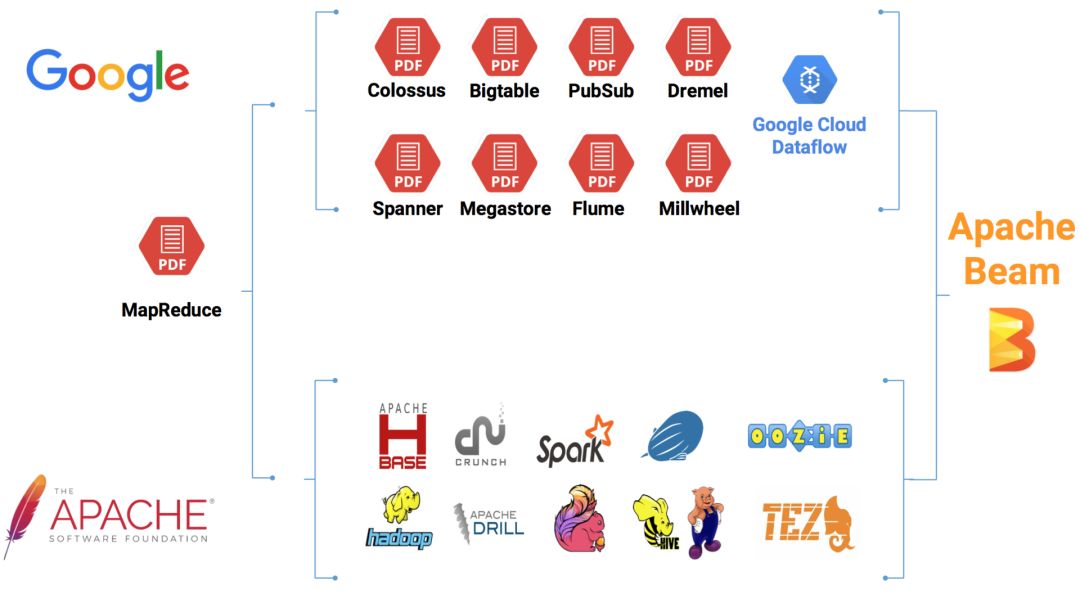
丰富的工具,繁荣的生态,也增加了开发者选择合适工具的难度。把开源框架,工具,类库,平台整合到一起,所需要的工作量以及复杂度,可想而知。技术的选择与使用,也是大数据开发者非常头疼的问题。
之前和 Google Brain 的工程师交流的时候,他提到在大数据领域,能把技术想明白,用明白的开发者太少了,一些中小型公司的技术 VP ,往往也是在“赶技术的时髦”的状态中,更别说普通的开发者。对大数据处理,比较常见的误区有下面几种:
1.低估了数据处理的重要性。
没有高质量的数据处理,人工智能只有人工没有智能。例如在语义理解上,Google 就曾犯过这样的错误,直到被一家德国的小公司超过,才认识到高质量的数据标注和处理的重要性。
2.低估了数据处理工程师在组织架构上的重要性。
大数据领域泰斗级人物Jesse Anderson曾做过一项研究,一个人工智能团队的合理组织架构,需要4/5的数据处理工程师。其实,即使是一个写前端的工程师,很多工作还是数据处理。很不幸,很多团队没有认识到这一点。
3.低估了数据处理规模变大带来的复杂度。
很多人还没有遇到过“大规模”的问题,因此容易把问题想的过于简单。Google有很多优秀的候选人,他们对常见的编程问题可以很好的解决,但只要追问数据规模变大时怎么设计系统,回答却常常不尽人意。
4.高估了上手数据处理的难度。
一方面我们需要认识到大规模的数据处理是有复杂的因素的。但另一方面,有了正确的工具和技术理念,现在上手数据处理并不困难。在Google,很多应届生入职半年后也能轻松应对上亿的数据量。
为了帮你比别人更准确深入地掌握实用的大规模数据处理技术,甚至达到硅谷一线系统架构师的水平。
简单提下 Google Brain(谷歌大脑):这个团队的项目包括使用神经网络的图像增强系统、谷歌神经机器翻译的学习框架以及通过机器学习自动学习获取新技能的机器人。在Android操作系统的语音识别系统,Google+的照片搜索和YouTube中的视频推荐系统中,都用到了Google Brain的技术。
上述就是小编为大家分享的Google工程师的大数据处理方法论是什么了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





