如何理解R语言中的KNN算法,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
k最临近(KNN)算法是最简单的分类算法之一,属于有监督的机器学习算法。
算法流程
KNN的核心思想是:找出特征空间中距离待分类点最近的k个点,如果这k个点大多数属于某一个类别,则该样本也属于这个类别。
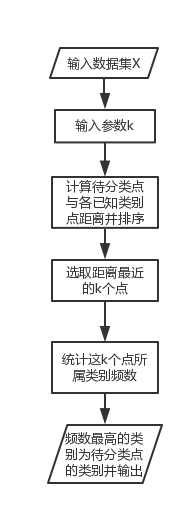
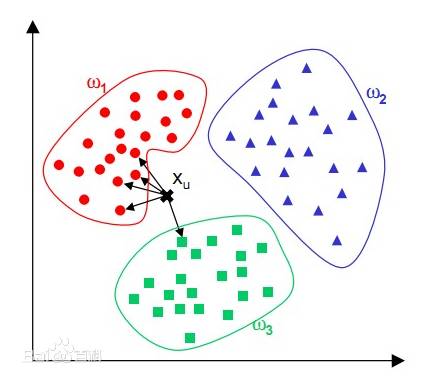
k值一般取20以下的整数。下图为从网上截取的图片,可以直观看到与点x最临近的5个点里,有4个为红色圆点,因此将点x的类别判断为红色圆点一类。
R语言实现
在R中实现knn聚类,可以使用class包中点knn()函数。在下面的例子中,我们使用UCI的[乳腺癌特征数据集]进行演示。首先,读入网上的数据:
#读取网上的数据并设置变量名
url <- 'http://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/wdbc.data'
wdbc.data <- read.csv(url,header = F)
names(wdbc.data) <- c('ID','Diagnosis','radius_mean','texture_mean','perimeter_mean', 'area_mean','smoothness_mean','compactness_mean','concavity_mean',
'concave points_mean','symmetry_mean','fractal dimension_mean','radius_sd','texture_sd','perimeter_sd','area_sd','smoothness_sd','compactness_sd','concavity_sd','concave points_sd','symmetry_sd','fractal dimension_sd','radius_max_mean','texture_max_mean','perimeter_max_mean','area_max_mean','smoothness_max_mean','compactness_max_mean','concavity_max_mean','concavepoints_max_mean','symmetry_max_mean','fractal dimension_max_mean')
因为有的变量取值大,有的变量取值小,所以我们在使用knn进行分类前,要先对数据通过归一化来进行无量纲处理。
#编写归一化函数
normalize <- function(x)
{
return ((x-min(x))/(max(x)-min(x)))
}
#对数据进行归一化
wdbc.data.min_max <- as.data.frame(lapply(wdbc.data[3:length(wdbc.data)],normalize))
wdbc.data.min_max$Diagnosis <- wdbc.data$Diagnosis
区分训练集和测试集,并纪录相应的分类标签。
m<-(dim(wdbc.data.min_max))[1]
val<-sample(1:m,size=round(m/3),replace=FALSE,prob=rep(1/m,m))
data.train<-wdbc.data.min_max[-val,]
data.test<-wdbc.data.min_max[val,]
data.train.label<-data.train$Diagnosis
data.test.label<-data.test$Diagnosis
data.train<-wdbc.data.min_max[-val,- length(wdbc.data.min_max)]
data.test<-wdbc.data.min_max[val,- length(wdbc.data.min_max)]
用knn算法进行分类,并用实际的分类标签与预测出的分类结果进行效果检测。
library(class)
test.pre.labels <- knn(data.train,data.test,data.train.label,k=7)
library(gmodels)
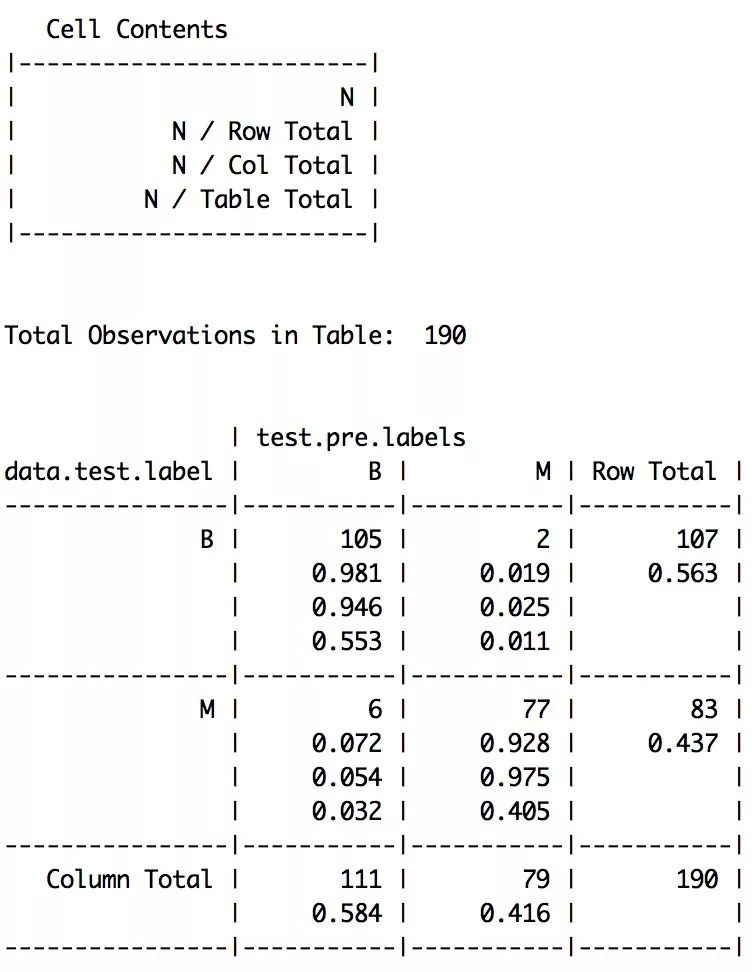
CrossTable(x = data.test.label, y = test.pre.labels, prop.chisq = F)
检测结果为:
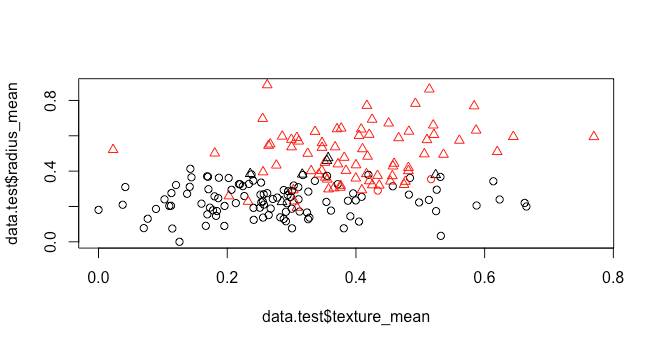
选取两个变量作为横纵坐标进行画图,观察实际类别与预测的分类结果。
plot(data.test$texture_mean,data.test$radius_mean,col=test.pre.labels,pch=as.integer(data.test.label))
颜色代表分类后得到的结果,形状代表真实的类别。从检测结果和图上都可以看出,分类结果基本与真实结果一致。
KNN优缺点
优点:
(1)算法原理简单,无需估计参数和训练。
(2)适合稀有事件的分类问题。
缺点:
(1)计算量太大,需要计算与每个点的距离。
(2)可解释性不强。
(3)样本不平衡时,k个最近的点中,大容量类别的点占据了大多数,但大容量类别不一定为待分类点的真实类别。
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4582480/blog/4385696



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



