这篇文章主要讲解了“PostgreSQL pg_qualstats 解决索引缺失的方法”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“PostgreSQL pg_qualstats 解决索引缺失的方法”吧!
商业数据库中,很多新版本都可以自动创建索引,给出索引创建的建议,并且以此作为卖点,ORACLE ,SQL SERVER 均有类似的功能,实际上通过查询语句,与全表扫描的语句,与谓词的比对,做出这样的系统其实不不是一件很难的事情。
我们下面采用PG11 的版本来进行相关的工作,(安装中遇到很多问题,最终还算解决了)
1 需要安装 PGDG的repo 环境,这样能节省你很多的安装中的麻烦以及依赖包问题。具体请移步PGDG中查看对应你版本的安装信息,并且安装 pg-devel环境
2 可以通过下载rpm包的方式安装
https://download.postgresql.org/pub/repos/yum/11/redhat/rhel-7-x86_64/pg_qualstats11-1.0.9-1.rhel7.x86_64.rpm
也可以下载源码包,进行编译安装,这里就省略了安装的过程。


最终的效果应该在配置文件中,添加pg_stat_statements 和 pg_qualstats 以及创建 extension pg_qualstats pg_stat_statements 这2个插件。
首先我们要知道 pg_qualstats 到底能做什么,pg_qualstats是一个PostgreSQL扩展,用于保存“WHERE”语句和“JOIN”子句中谓词的统计信息。

看上图可以看到相关 pg_qualstats 的变量
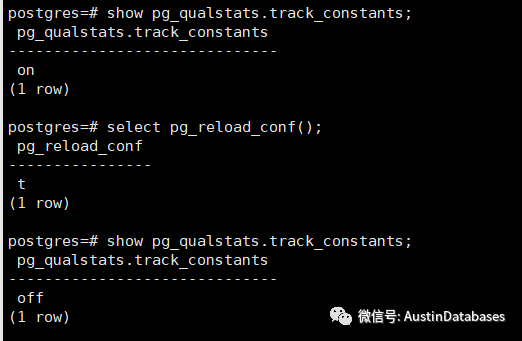
另外需要将pg_qualstats.track_constants 关掉,否则会收集很多类似的查询占用相关的存储位置。
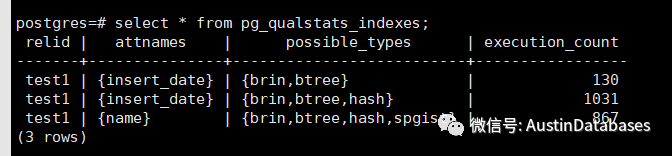
我们可以写一个存储过程,批量运行一些查询语句,在执行完毕后,我们可以通过 pg_qualstats_indexes来查看当前查询中的谓词,并且这些谓词是没有索引的,以及查询的次数。
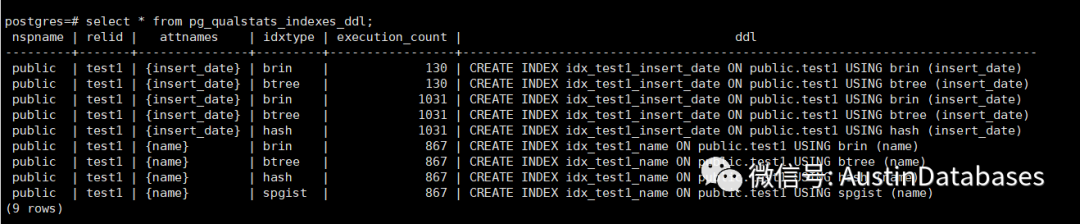
同时根据 pg_qualstats_indexes_ddl 表可以看到 pg_qualstats 推荐你需要建立的索引,(因为PG支持的索引多,所以提供了一种索引需求的多种建立方案)
故事到这里看似完了,其实不然。我们先的说说这个插件是从何而来,去往何处,在哪里打间,在哪里住店.....
实际上是有一个程序的组建,powa ,通过这个组建本身是可以动态,WEB化查询系统中缺失的索引,并给出相关信息的。这里我们仅仅是借用了这个软件的一部分,也可以说叫 client。我们使用的这个插件仅仅是负责收集信息使用的。但其实对我们来说,已经足够了,如果你有几十台的PG 到是可以进一步的安装这个软件,来讲所有的PG 囊获其中。软件的名字叫 PostgreSQL Workload Analyzer。
使用了这个插件后能回答你对系统的几个问题
平时系统是怎么进行查询的,经常查询的语句是什么,查询中同一个查询不同的值的分布式怎样的,那些列会经常在一起查询。
实际上我们可以问自己几个问题,我为什么要用这个软件,会使用这个插件,并且通过他来建立一些索引,自然是好的,但这也透露出一个问题,开发在开发系统的时候,并不知道自己的SQL 语句,或无法提供,并且DBA 也在系统上线前对此一无所知,这其实就是一个BUG,而通过这个工具来弥补,那只能是虎狼の药。另外的就是不要迷信这个软件,认为头痛医头,脚痛医脚,其实病根在心。(以上啰嗦几句,不感兴趣的客官可以移步 NEXT STATION)
我们回来看看这个插件里面的一些表
1 pg_qualstats 这个表本身包含了执行语句的用户,表所处的数据库是那个,以及表名(可以通过和其他表连接后获得相关信息),另外关键的execution_count 和 nbfiltered 这里面的意思是这个语句执行了多少次,并且多少次是重复的,另外也包含的queryid, 可以追溯你的查询语句。
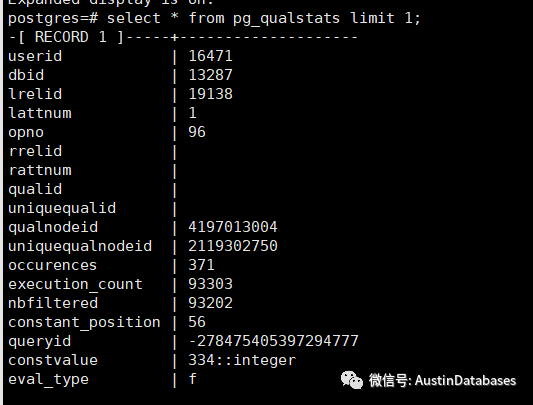
2
select * from pg_qualstats_by_query ;
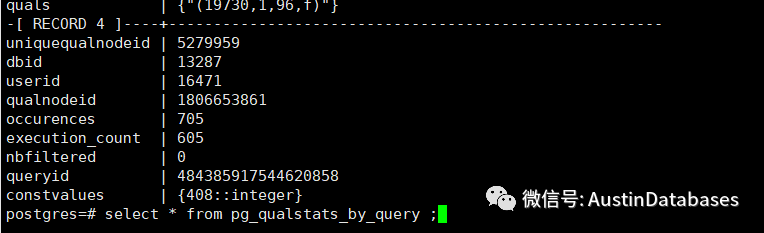
这个表重要的地方在于queryid 通过这个表才能关联你要的查询语句,最后通过关联其他表将其显示出来
3
select * from pg_qualstats_indexes 这个表也是关键,他给出了你查询中需要建立索引的建议
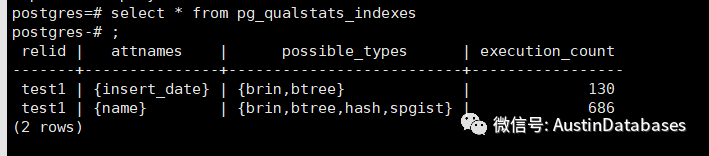
另外还有一些其他的表,这里就不在介绍了,直接给一些自己写的列子来阐述一下这个工具到底可以解决实际什么问题
1 如何确认语句运行的时间,下面这个SQL 可以定期的运行,来获取系统中运行的SQL 以及每条SQL的平均运行时间。
with table_info as (select pc.relname,pgq.execution_count,pgq.uniquequalnodeid
from pg_qualstats as pgq
left join pg_class as pc on pgq.lrelid = pc.relfilenode),
query_info as (
select pss.total_time/calls as average_time,pss.query,pgb.uniquequalnodeid
from pg_qualstats_by_query as pgb
left join pg_stat_statements as pss on pgb.queryid = pss.queryid)
select *
from table_info as t
right join query_info as q on t.uniquequalnodeid = q.uniquequalnodeid
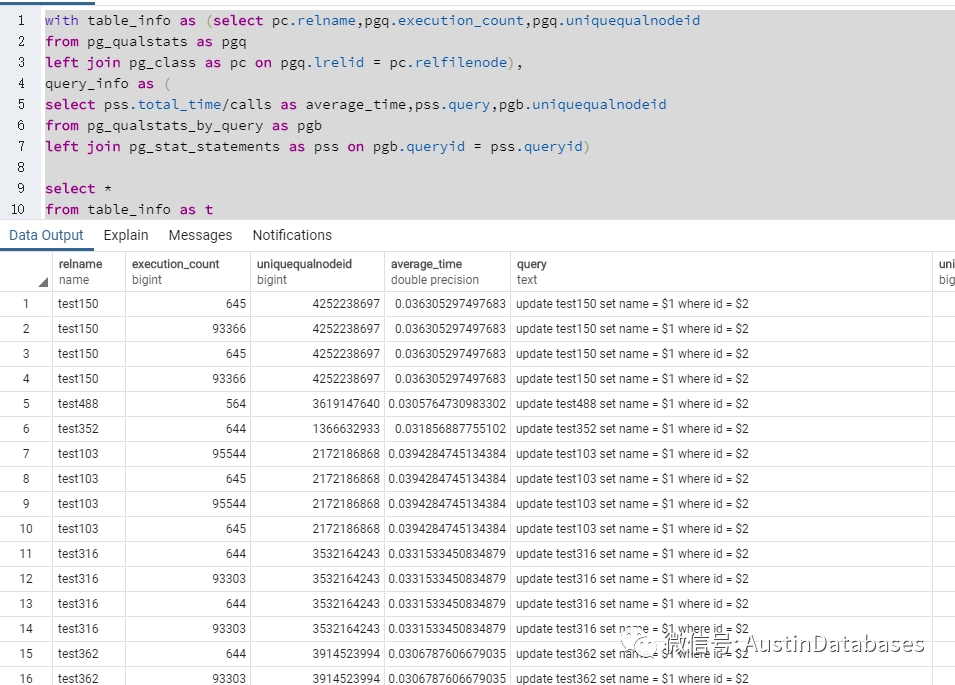
2
select pqi.relid,pqi.attnames,pqi.execution_count,pqd.idxtype,pqd.ddl
from pg_qualstats_indexes_ddl as pqd
left join pg_qualstats_indexes as pqi on pqd.relid = pqi.relid and pqd.attnames = pqi.attnames
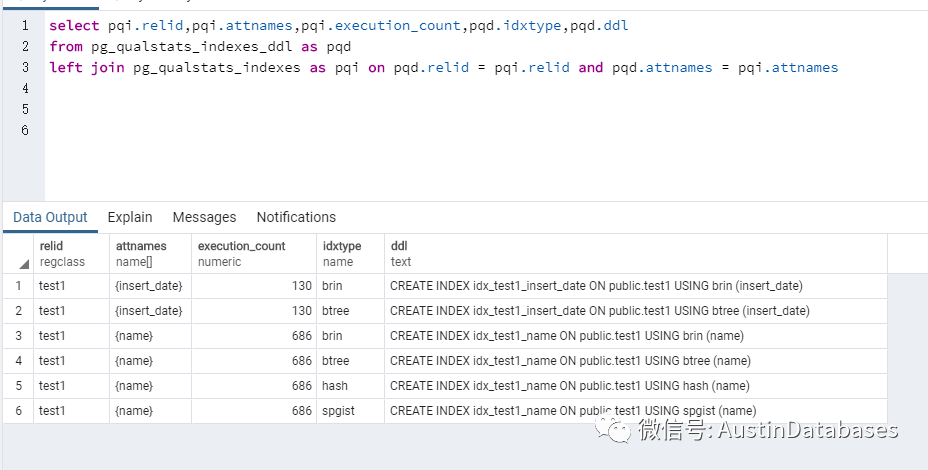
上面这个SQL 可以查看到底那个表上需要建立什么样的索引,配合上面的表可以通过查询语句来确认添加索引的正确性。
最后说说他的想法是什么
第一步是获取查询中所有的谓词,并分析这个查询中提取的谓词是否有益于查询,这个信息存储在pg_qualstats中,在这其中会去重一些同样的语句,但会记录相关的次数,当然这其中也和查询的方式有关,如果你是多个条件加and的操作,则这些条件会进行记录。根据查询的次数,和频繁度,查询数据的分布,等推荐需要建立的索引的方式。最终生成相关的DDL 语句。
感谢各位的阅读,以上就是“PostgreSQL pg_qualstats 解决索引缺失的方法”的内容了,经过本文的学习后,相信大家对PostgreSQL pg_qualstats 解决索引缺失的方法这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4582201/blog/4378062



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



