PostgreSQLеҰӮдҪ•дҪҝз”Ёrepmgrе®һзҺ°й«ҳеҸҜз”Ё
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іPostgreSQLеҰӮдҪ•дҪҝз”Ёrepmgrе®һзҺ°й«ҳеҸҜз”ЁпјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
1 еӨ§еҺӮж”ҜжҢҒ
2 й…ҚзҪ®з®ҖеҚ•йқ и°ұпјҢжІЎжңүдј—еӨҡдҫқиө–еҢ…е®үиЈ…еҗҺпјҢиҝҳеҮәй—®йўҳи®©дҪ жңүжғіиҮӘжқҖзҡ„ж„Ҹж„ҝпјҢжҲ–иҖ…жҳҜзӣёе…ізҡ„жҠҖжңҜж–Үеӯ—е°‘пјҢи§ЈеҶій—®йўҳеӣ°йҡҫзҡ„е°ҝзӮ№гҖӮ
иҝҷдёӘй«ҳеҸҜз”Ёзҡ„ж–№жЎҲе·Із»ҸеңЁз”ҹдә§дёҠдҪҝз”ЁдәҶжңүдёҖж®өж—¶й—ҙпјҢзӣ®еүҚжІЎжңүеҮәиҝҮй—®йўҳпјҢд№ӢеүҚеҶҷиҝҮпјҢдҪҶжҳҜеңЁиҝҷдёҖж®өж—¶й—ҙзҡ„дҪҝз”Ёдёӯд№ҹеҸ‘зҺ°дәҶдёҖдәӣй—®йўҳпјҢжүҖд»ҘеҮҶеӨҮиҜҰз»Ҷзҡ„еҜ№иҝҷдёӘй«ҳеҸҜз”Ёж–№жЎҲжқҘиҜҰз»Ҷзҡ„иҜҙиҜҙпјҢд№ҹйҒҝе…ҚжҹҗдәӣжҢ‘еҲәзҡ„иҜҙ PG жІЎжңүйқ и°ұзҡ„й«ҳеҸҜз”Ёиҝҷж ·зҡ„笑иҜқпјҢ继з»ӯеӯҳеңЁгҖӮ
иҝҷдёӘй«ҳеҸҜз”Ёзҡ„ж–№ејҸе°ұжҳҜrepmgr пјҢ2иұЎйҷҗе…¬еҸёзҡ„дә§е“ҒгҖӮпјҲе…Қиҙ№зҡ„пјүпјҢд»ҘдёӢзҡ„ж–Үеӯ—дёӯзҡ„PGзҡ„зүҲжң¬жҳҜ 11.2 пјҢREPMGR жҳҜ 4.4 зүҲжң¬гҖӮз”ұдәҺеҠҹиғҪжҜ”иҫғеӨҡпјҢжүҖд»ҘдёҖж¬Ўд№ҹеҶҷдёҚе®ҢпјҢеҸӘиғҪеҲҶжңҹзҡ„еҶҷпјҢд»ҠеӨ©зҡ„ж–Үеӯ—иҰҒеҒҡеҲ°зҡ„жҳҜ дёӨеҸ° POSTGRESQL пјҢе®ҢжҲҗжүӢеҠЁеҲҮжҚўгҖӮ

йҰ–е…ҲдҪ йңҖиҰҒе®үиЈ…2еҸ°postgresql пјҢиҝҷйҮҢеҒҮи®ҫдҪ е·Із»Ҹе®үиЈ…е®ҢжҜ•дәҶпјҲе®үиЈ…еҪ“然жҳҜзј–иҜ‘е®үиЈ…пјҢеҰӮжһңдёҚжҳҜзј–иҜ‘е®үиЈ…еҲҷжҲ‘дёҚдҝқиҜҒдёҚдјҡеҮәе…¶д»–зҡ„й—®йўҳпјҢд№ӢеүҚжңүдёҖзҜҮжҳҜе…ідәҺзј–иҜ‘е®үиЈ…зҡ„пјҢеҪ“然д№ҹеҸҜд»ҘеҺ» вҖңеҫ·е“ҘвҖқзҡ„github дёҠеҺ»жүҫдё“дёҡзҡ„ж–Үеӯ—е…ідәҺPOSTGRESQL зҡ„е®үиЈ…пјҢж°ҙдёҚжө…пјү
1 е®үиЈ…е®ҢжҜ•зҡ„POSTGRESQLйҰ–е…ҲиғҪжңүиҝӣиЎҢ replication зҡ„жқЎд»¶
2 дёӨеҸ°postgresql иҰҒй…ҚзҪ®дёҖж ·пјҢеҢ…еҗ«й…ҚзҪ®ж–Ү件пјҢд»ҘеҸҠextensionзӯүзӯү
иҝҷйҮҢдёәдәҶдҫҝдәҺдёӢйқўзҗҶи§ЈдёӨеҸ°жңәеҷЁзҡ„
192.168.198.21 дё»еә“
192.168.198.22 еӨҮеә“
е…¶е®һжҲ‘们й…ҚзҪ®дёҖеҸ°жңәеҷЁе°ұеҸҜд»ҘдәҶпјҢжҲ‘们еңЁдёҖеҸ°жңәеҷЁпјҲдё»жңәпјү
ж“ҚдҪңд»ҘдёӢзҡ„е‘Ҫд»Ө
create database repmgr;
create user repmgr with password 'repmgr'; пјҲеҜҶз ҒжӮЁйҡҸж„Ҹпјү
alter user repmgr superuser login;
alter database repmgr owner to repmgr;
еҜ№ repmgr и§ЈеҢ…иҝӣиЎҢзј–иҜ‘

еңЁзЎ®и®Өе·Із»Ҹзј–иҜ‘еҘҪrepmgr еҗҺпјҢйңҖиҰҒеҜ№дёӨеҸ°жңәеҷЁиҝӣиЎҢssh е…ҚеҜҶзҡ„е·ҘдҪң
иҝҷйҮҢзҡ„е…ҚеҜҶе»әи®®жҳҜеҹәдәҺдҪ ж“ҚжҺ§postgresql зҡ„иҙҰжҲ·пјҢиҖҢдёҚжҳҜroot
пјҲжіЁпјҡе…ҚеҜҶзҡ„е·ҘдҪңиҝҷйҮҢеҰӮжҳҜMYSQLзҡ„DBA иҝҷе°ҶдёҚжҳҜеҫҲйҡҫзҗҶи§Јзҡ„е·ҘдҪңпјҢеӣ дёәMHAе°ұжҳҜиҝҷд№Ҳе№Ізҡ„пјү
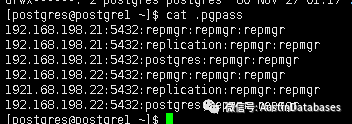
еҸҰеӨ–иҝҳйңҖиҰҒй…ҚзҪ®repmgr й«ҳеҸҜз”ЁдҪҝз”Ёзҡ„йҖҡи®ҜиҙҰжҲ·пјҢд№ҹйңҖиҰҒиҝӣиЎҢе…ҚеҜҶзҡ„е·ҘдҪңпјҢйңҖиҰҒеңЁдҪ ж“ҚдҪңpostgresqlзҡ„иҙҰжҲ·дёӯзӣ®еҪ•дҪҚзҪ®и®ҫзҪ®.pgpass пјҢеҶ…е®№иҜ·еҸӮи§ҒдёӢеӣҫ
е…¶е®һеҰӮжһңй…ҚзҪ®иҝҮmha пјҢеҜ№иҝҷж ·зҡ„дәӢжғ…д№ҹжҳҜеҫҲе®№жҳ“зҗҶи§Јпјү
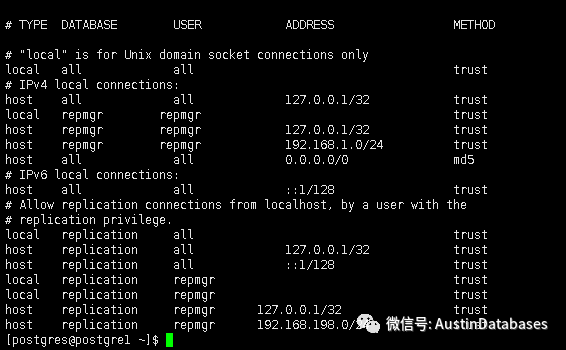
еҸҰеӨ–д№ҹйңҖиҰҒеҜ№ pg_hba.conf иҝӣиЎҢй…ҚзҪ®пјҢй…ҚзҪ®ж–№жі•и§ҒдёӢеӣҫ пјҲеҸҜиғҪжҮӮзҡ„дјҡеңЁиҝҷйҮҢжңүз–‘й—®пјҢдҪҶиҝҷйҮҢзҡ„зЎ®жҳҜйңҖиҰҒиҝҷж ·и®ҫзҪ®пјҢе®ҳзҪ‘зҡ„ж–ҮжЎЈпјү
https://repmgr.org/docs/4.4/quickstart-authentication.html
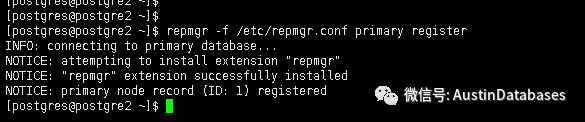
еңЁеҒҡе®ҢиҝҷдёҖеҲҮеҗҺпјҢжҲ‘们йңҖиҰҒй…ҚзҪ® repmgr.conf ж–Ү件 пјҲе…¶е®һиҝҷиҝҳжҳҜе’ҢMHA зҡ„й…ҚзҪ®ж–№ејҸзұ»дјјпјҢжүҖд»ҘеҰӮжһңдҪ жҳҜMYSQL DBA еҲҷPGзҡ„й«ҳеҸҜз”Ёж–№ејҸзҡ„еӯҰд№ жҲҗжң¬дјҡеҫҲдҪҺпјү
node_id=1 йӣҶзҫӨдёӯзҡ„ж ҮиҜҶ жіЁж„ҸиҝҷдёӘдёҖдёӘйӣҶзҫӨдёҚиғҪжңүйҮҚеӨҚпјҢдёҖиҲ¬з”Ёж•°еӯ—жқҘ
node_name='192.168.198.21' йңҖиҰҒз»ҷиҠӮзӮ№дёҖдёӘжіЁеҶҢзҡ„еҗҚеӯ—пјҢиҝҷйҮҢеҸҜд»ҘдҪҝз”ЁIP д№ҹеҸҜд»ҘдҪҝз”ЁжңәеҷЁеҗҚзӯүзӯү
conninfo='host=192.168.198.21 dbname=repmgr user=repmgr connect_timeout=2'
жң¬ең°иҝһжҺҘдҝЎжҒҜпјҢrepmgr ж“ҚдҪңжң¬ең°ж—¶зҡ„иҝһжҺҘдҝЎжҒҜ
data_directory='/pgdata/data' жҢҮе®ҡеҪ“еүҚдё»жңәзҡ„ж•°жҚ®зӣ®еҪ•
replication_user='repmgr' иҝӣиЎҢеӨҚеҲ¶зҡ„ж“ҚдҪңзҡ„иҙҰжҲ·
replication_type='physical' еӨҚеҲ¶зҡ„ж–№ејҸ
repmgr_bindir='/usr/local/postgres/bin' repmgr зҡ„жү§иЎҢж–Ү件зҡ„зӣ®еҪ•
pg_bindir='/usr/local/postgres' й…ҚзҪ®PGзҡ„жү§иЎҢж–Ү件
еҸҰдёҖеҸ°жңәеҷЁпјҢйңҖиҰҒеңЁ node_id , node_name , conninfo зӯүдҪҚзҪ®еҒҡж”№еҸҳпјҢ
жҲ‘们еҲ°зӣ®еүҚе°Ҹз»“дёҖдёӢеҪ“еүҚзҡ„дёӨеҸ°жңәеҷЁзҡ„зҠ¶еҶө
дё»жңәпјҢе·Із»ҸжіЁеҶҢrepmgr пјҢжңҚеҠЎеҷЁејҖеҗҜзҡ„зҠ¶жҖҒпјҢеҸҜд»ҘжҺҘеҸ—repmgr зҡ„иҝңзЁӢиҝһжҺҘе…ҚеҜҶзҡ„ж–№ејҸпјҢеӨҮеә“е…іжңәпјҢеӨҮеә“зҡ„ж•°жҚ®зӣ®еҪ•жҳҜжё…з©әзҡ„зҠ¶жҖҒпјҲеӣ дёәиҰҒејҖе§ӢиҝӣиЎҢдё»еә“жӢүж•°жҚ®зҡ„ж“ҚдҪңпјү
дёӢйқўжҲ‘们е°ұиҰҒдҪҝз”ЁдёҖдёӢзҡ„е‘Ҫд»ӨжқҘиҝӣиЎҢ --dry-run (mysqlзҡ„DBA жҳҜдёҚжҳҜеҫҲжғҠе–ң е’Ңpt е·Ҙе…·дёҖи·Ҝиҙ§)
repmgr -h 192.168.198.21 -U repmgr -d repmgr -f /etc/repmgr.conf standby clone --dry-run
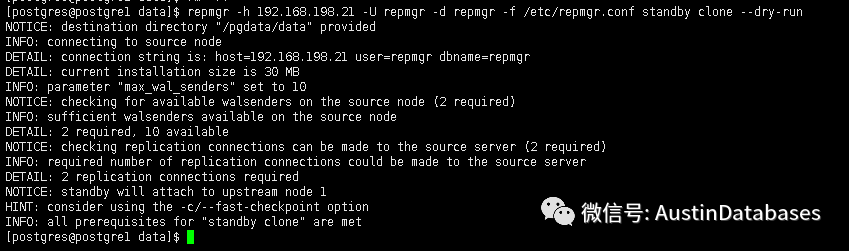
еҸҜд»ҘзңӢеҲ°--dry-run жІЎжңүй—®йўҳзӣҙжҺҘжү§иЎҢе‘Ҫд»ӨиҝӣиЎҢ clone
repmgr -h 192.168.198.21 -U repmgr -d repmgr -f /etc/repmgr.conf standby clone
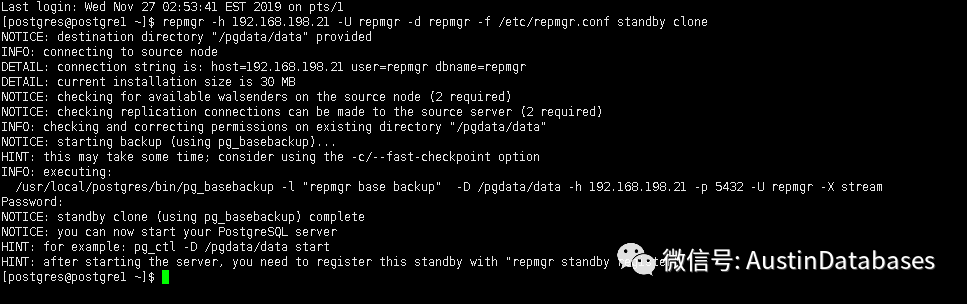
然еҗҺеңЁclone жҲҗеҠҹеҗҺпјҢе…¶е®һе°ұжҳҜpg_basebackup пјҢеңЁиҝҷд»ҘеҗҺйңҖиҰҒдҝ®ж”№standby жңәеҷЁдёӯзҡ„postgresql,conf ж–Ү件дёӯзҡ„ listen ең°еқҖж”№дёәжң¬жңәзҡ„ең°еқҖ
пјҲиҝҷдәӣе·ҘдҪңе…¶е®һд№ҹжҳҜеҒҡ primary standby зҡ„е·ҘдҪңпјҢе’Ңй«ҳеҸҜз”Ёжң¬иә«жҳҜжІЎжңүе…ізі»зҡ„пјҢзҹҘиҜҶ repmgr её®еҠ©дҪ еҒҡдәҶиҝҷ件дәӢпјү
еҗҜеҠЁжңҚеҠЎеҷЁпјҢжӯЈеёёпјҢ并ејҖе§ӢеӨҚеҲ¶

еҰӮжһңеҲ°иҝҷйҮҢеҮәдәҶй—®йўҳпјҢеҸҜиғҪзҡ„еҺҹеӣ
1 pg_hba.conf и®ҫзҪ®зҡ„жңүй—®йўҳ
2 postgresql.conf д»Һеә“ жІЎжңүж”№ postgresql,conf зӣ‘еҗ¬ең°еқҖ
пјҲиҜ·иЎҘе……POSTGRESQL еҹәзЎҖзҹҘиҜҶпјү
дёӢдёҖжӯҘжҲ‘们е°ұйңҖиҰҒеҜ№еӨҚеҲ¶иҝӣиЎҢдёҖдёӘйӘҢиҜҒпјҲеҰӮжһңжңүиҮӘдҝЎе°ұи·іиҝҮжӯӨжӯҘйӘӨпјү
еңЁд»Һеә“жҲ‘们жҹҘзңӢзӣ®еүҚзҡ„еӨҚеҲ¶жҳҜеҗҰOK пјҢдёӢеӣҫжҳҫзӨәOK

然еҗҺеңЁд»Һеә“жү§иЎҢ
repmgr -f /etc/repmgr.conf standby register
жіЁеҶҢжҲҗеҠҹеҗҺ

зӣ®еүҚеӨ§йғЁеҲҶзҡ„й«ҳеҸҜз”ЁпјҲжүӢеҠЁеҲҮжҚўпјүзҡ„е·ҘдҪңе·Із»Ҹе®ҢжҲҗдәҶзҷҫеҲҶд№Ӣ80%
repmgr -f /etc/repmgr.conf cluster show

йҖҡиҝҮдёҠйқўзҡ„еӣҫе’Ңе‘Ҫд»ӨеҸҜд»ҘеҫҲйЎәеҲ©жҹҘзңӢпјҢдёӨеҸ°жңәеҷЁзҡ„дё»д»ҺзҠ¶жҖҒгҖӮ
еҶҷеҲ°дёӢйқўпјҢеҸҜиғҪжңүдәәиҰҒеҗҗж§ҪжҲ‘дәҶпјҢдәә家йғҪиҮӘеҠЁпјҢдҪ жүӢеҠЁпјҢдҪ и„‘еӯҗиҝӣж°ҙдәҶгҖӮ
1 POSTGRESQL зҡ„repmgr дё»д»ҺеҲҮжҚўпјҢжҳҜеҸҜд»ҘиҮӘеҠЁзҡ„пјҢдҪҶиҝҷжңҹеҶҷдёҚе®Ң
2 еҰӮжһңдҪҝз”Ёmysql жҜ”иҫғйЎәжәңзҡ„пјҢеҲ°иҝҷйҮҢ马дёҠе°ұеҸҜд»ҘеҸҚжҳ еҮәдёҖдёӘй—®йўҳпјҢMHA жҲ‘еҲҮжҚўжҲ‘д№ҹжІЎжңүз”Ё MHA еҺ»дҫҰжөӢпјҢжҲ‘д№ҹжҳҜйҖҡиҝҮе…¶д»–зҡ„ж–№ејҸжқҘжЈҖжөӢпјҢ然еҗҺдҪҝз”Ё MHA е‘Ҫд»ӨеҲҮжҚўж–№ејҸжқҘиҝӣиЎҢй«ҳеҸҜз”Ёзҡ„еҲҮжҚўгҖӮ
иҜқиҜҙеҲ°иҝҷйҮҢе·Із»ҸиҜҙзҡ„еҫҲжҳҺдәҶпјҢдҪ иҰҒжҳҜжңүMYSQLзҡ„й«ҳеҸҜз”ЁMHAзҡ„и§ЈеҶіж–№жЎҲпјҢеҲ°иҝҷйҮҢдҪ иҮӘе·ұе·Із»Ҹжңүдё»ж„ҸдәҶпјҢиҝҳжңүеҝ…иҰҒзңӢдёӢеҺ»зҡ„еҺҹеӣ е°ұжҳҜпјҢжҖҺд№ҲжүӢеҠЁеҲҮжҚўгҖӮ然еҗҺдҪ е°ұеҸҜд»Ҙж”ҫйЈһиҮӘжҲ‘дәҶгҖӮ
жғіиҜҙ POSTGRESQL жІЎжңүйқ и°ұй«ҳеҸҜз”Ёж–№ејҸзҡ„пјҢжү“и„ёдёҚ
дёӢйқўе°ұејҖе§ӢжүӢеҠЁеҲҮжҚў
repmgr -f /etc/repmgr.conf standby switchover -U repmgr --verbose
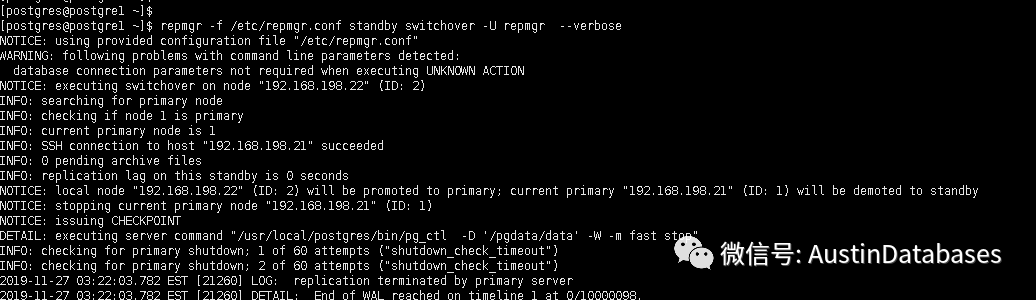
еҘҪдәҶеңЁеҲҮжҚўе‘Ҫд»ӨејҖе§ӢеҗҺпјҢдё»д»ҺејҖе§ӢеҲҮжҚўпјҢеҸӮи§ҒдёӢеӣҫ

еҲҮжҚўеҗҺпјҢжҲ‘们еңЁдё»жңәдёҠжҹҘзңӢзҠ¶жҖҒ

дё»жңәе·Із»ҸеҸҳжҲҗд»Һеә“пјҢд»Һеә“е·Із»ҸеҚҮзә§дёәдё»еә“

еңЁд»Һеә“дёҠжҹҘзңӢпјҢеҫҲжё…жҷ°зҡ„е‘ҠиҜүдҪ пјҢдё»еә“е·Із»ҸжҳҜ 22 пјҢд»Һеә“еҸҳжҲҗдәҶ21

иҝҷд№ҹжҳҜе’ҢMHA дёҚдёҖж ·зҡ„ең°ж–№пјҢеҰӮжһңдҪ зҡ„еӨұиҙҘзҡ„дё»еә“иҝҳжңүжҢҪж•‘зҡ„дҪҷең°пјҢеҲҷиҝҳжҳҜеҸҜд»Ҙи®©д»–еҸҳжҲҗд»Һеә“пјҢ继з»ӯжңҚеҠЎзҡ„пјҢеҪ“然д№ҹжҳҜжңүж—¶й—ҙйҷҗеҲ¶зҡ„пјҢй»ҳи®ӨдёҖеҲҶй’ҹзҡ„е°қиҜ•пјҢеҗҰеҲҷе°ұж”ҫејғдәҶгҖӮ
е…ідәҺвҖңPostgreSQLеҰӮдҪ•дҪҝз”Ёrepmgrе®һзҺ°й«ҳеҸҜз”ЁвҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢдҪҝеҗ„дҪҚеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢиҜ·жҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ





