本篇内容主要讲解“linux的时间管理和定时器原理”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“linux的时间管理和定时器原理”吧!
linux初始化的时候,初始化了定时相关的代码。
void sched_init(void){ ... // 43是控制字端口,0x36=0x00110110,即二进制,方式3,先读写低8位再读写高8位,选择计算器0 outb_p(0x36,0x43); /* binary, mode 3, LSB/MSB, ch 0 */ /* 写入初始值,40端口是计数通道0,初始值 的含义是,8253每一个波动,初始值会减一,减到0则输出一个通知, LATCH = (1193180/100),1193180是8253的工作频率, 一秒钟波动1193180次。(1193180/100)就是(1193180/1000)*10,即 (1193180/1000)减到0的时候,过去了1毫秒。乘以10即过去10毫秒。 */ outb_p(LATCH & 0xff , 0x40); /* LSB */ // 再写8位 outb(LATCH >> 8 , 0x40); /* MSB */ // 设置定时中断处理函数,中断号是20,8253会触发该中断 set_intr_gate(0x20,&timer_interrupt); ...}_timer_interrupt: push %ds # save ds,es and put kernel data space push %es # into them. %fs is used by _system_call push %fs pushl %edx # we save %eax,%ecx,%edx as gcc doesn't pushl %ecx # save those across function calls. %ebx pushl %ebx # is saved as we use that in ret_sys_call pushl %eax movl $0x10,%eax mov %ax,%ds mov %ax,%es movl $0x17,%eax mov %ax,%fs incl _jiffies movb $0x20,%al # EOI to interrupt controller #1 outb %al,$0x20 movl CS(%esp),%eax andl $3,%eax # %eax is CPL (0 or 3, 0=supervisor) pushl %eax call _do_timer # 'do_timer(long CPL)' does everything from addl $4,%esp # task switching to accounting ... jmp ret_from_sys_call
AI代码助手复制代码我们看到中断的时候执行了do_timer函数,该函数就是处理定时器和进程调度的。在此之前我们先看看怎么新增一个定时器。
#define TIME_REQUESTS 64// 定时器数组,其实是个链表static struct timer_list { long jiffies; void (*fn)(); struct timer_list * next;} timer_list[TIME_REQUESTS], * next_timer = NULL;void add_timer(long jiffies, void (*fn)(void)){ struct timer_list * p; if (!fn) return; // 关中断,防止多个进程”同时“操作 cli(); // 直接到期,直接执行回调 if (jiffies <= 0) (fn)(); else { // 遍历定时器数组,找到一个空项 for (p = timer_list ; p < timer_list + TIME_REQUESTS ; p++) if (!p->fn) break; // 没有空项了 if (p >= timer_list + TIME_REQUESTS) panic("No more time requests free"); // 给空项赋值 p->fn = fn; p->jiffies = jiffies; // 在数组中形成链表 p->next = next_timer; // next_timer指向第一个节点,即最早到期的 next_timer = p; /* 修改链表,保证超时时间是从小到大的顺序 原理: 每个节点都是以前面一个节点的到时时间为坐标,节点里的jiffies即超时时间 是前一个节点到期后的多少个jiffies后该节点到期。 */ while (p->next && p->next->jiffies < p->jiffies) { // 前面的节点比后面节点大,则前面节点减去后面节点的值,算出偏移值,下面准备置换位置 p->jiffies -= p->next->jiffies; // 先保存一下 fn = p->fn; // 置换两个节点的回调 p->fn = p->next->fn; p->next->fn = fn; jiffies = p->jiffies; // 置换两个节点是超时时间 p->jiffies = p->next->jiffies; p->next->jiffies = jiffies; /* 到这,第一个节点是最快到期的,还需要更新后续节点的值,其实就是找到一个合适的位置 插入,因为内核是用数组实现的定时器队列,所以是通过置换位置实现插入, 如果是链表,则直接找到合适的位置,插入即可,所谓合适的位置, 就是找到第一个比当前节点大的节点,插入到他前面。 */ p = p->next; } /* 内核这里实现有个bug,当当前节点是最小时,需要更新原链表中第一个节点的值,, 否则会导致原链表中第一个节点的过期时间延长,修复代码如下: if (p->next && p->next->jiffies > p->jiffies) { p->next->jiffies = p->next->jiffies - p->jiffies; } 即更新原链表中第一个节点相对于新的第一个节点的偏移,剩余的节点不需要更新,因为他相对于 他前面的节点的偏移不变,但是原链表中的第一个节点之前前面没有节点,所以偏移就是他自己的值, 而现在在他前面插入了一个节点,则他的偏移是相对于前面一个节点的偏移 */ } sti();}
AI代码助手复制代码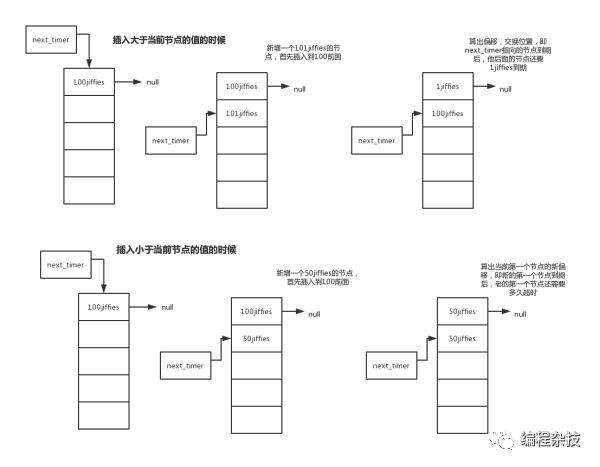
上面是示例图。这样就完成了定时节点的插入。我们再回头看一下do_timer的代码,即系统由定时中断时执行的代码。
void do_timer(long cpl){ ... // 当前在用户态,增加用户态的执行时间,否则增加该进程的系统执行时间 if (cpl) current->utime++; else current->stime++; // next_timer为空说明还没有定时节点 if (next_timer) { // 第一个节点减去一个jiffies,因为其他节点都是相对第一个节点的偏移,所以其他节点的值不需要变 next_timer->jiffies--; // 当前节点到期,如果有多个节点超时时间一样,即相对第一个节点偏移是0,则会多次进入while循环 while (next_timer && next_timer->jiffies <= 0) { void (*fn)(void); fn = next_timer->fn; next_timer->fn = NULL; next_timer = next_timer->next; (fn)(); } } ... // 进程调度 schedule();}
AI代码助手复制代码我们发现,add_timer的时候已经算好了定时器的顺序是从先到期到后到期的,并且后面的节点是相对前面节点的偏移,所以判断超时的时候,只需要从前往后判断,如果第一节点没到期则后面的也不会到期,如果第一个到期,则继续判断下一个节点。把耗时的操作放到新增节点的时候,因为新增定操作是很少且不频繁的,但是定时中断是频繁的操作。所以这样就保证了性能。最后我们还发现,操作系统就是在这里通过schedule函数处理进程调度的。即没10毫秒,系统进程一次进程调度。
到此,相信大家对“linux的时间管理和定时器原理”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4217331/blog/4379838



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



