本篇文章为大家展示了scrapy实战中怎样爬取表情包,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
一、爬取表情包思路(http://www.doutula.com)
1、打开网站,点击最新套图
2、之后我们可以看到没有套图,我们需要提取每个套图的连接
3、获取连接之后,进入页面提取图片就好了
4、我们可以发现该网站还穿插有广告,我们需要过滤点广告
二、实战
关于新建项目我们就不再多说了。不知道的可以看看以前文章。。。
1、首先我们提取第一页的url
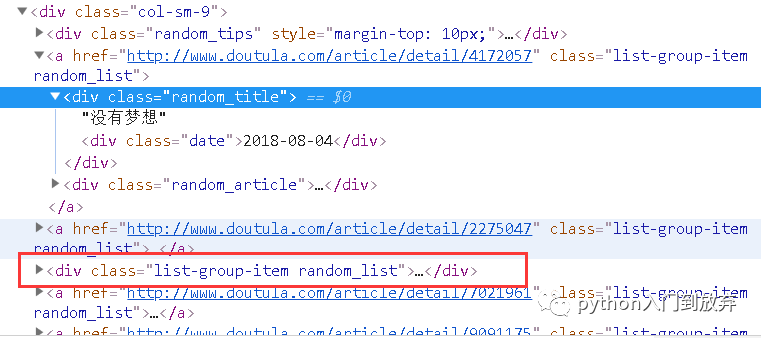
通过上图我们可以发现我们想要的url全在class名为col-sm-9的div下,
红色框的部分为广告。不是a标签,所以我们就不用过滤了。我们直接选取col-sm-9下的直接子节点即可
写下如下代码:
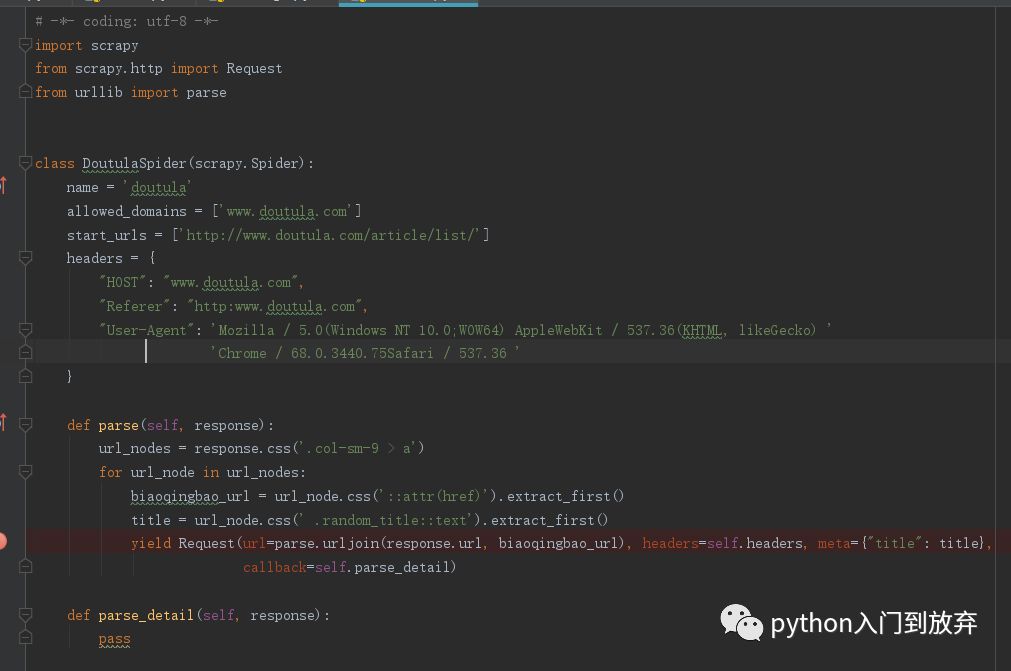
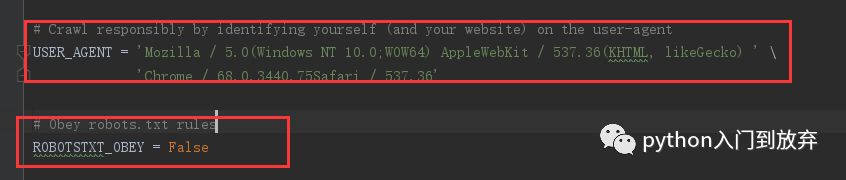
值得注意的是在settings.py中需要添加头信息和将robots.txt协议修改为False
我们打上断点调试一下:
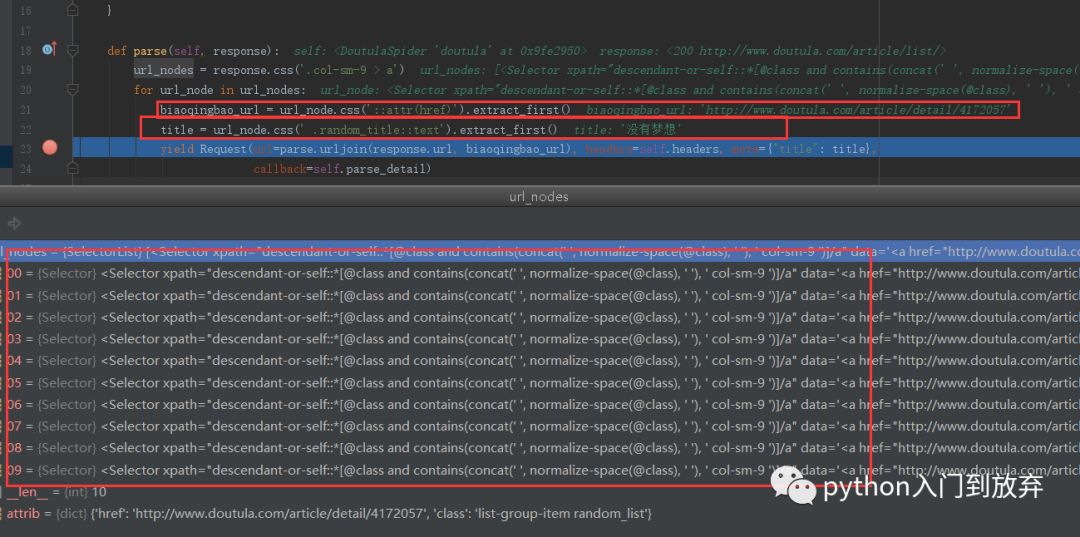
我们发现我们想要的信息已经提取出来了。
注意:在Request中的mate参数,是用来传递参数的,传递给下一个方法使用。使用方法和字典相似。
2、完善item
我们只需要三个字段,什么系列,图片url,图片名称。
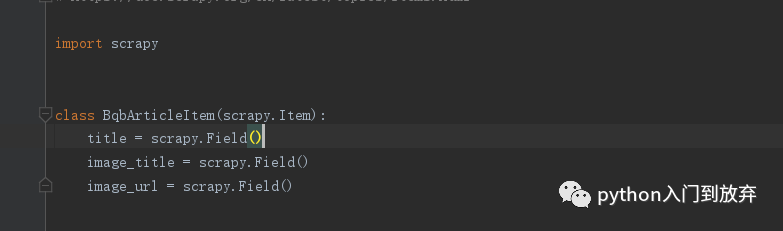
3、提取item中我们需要的字段

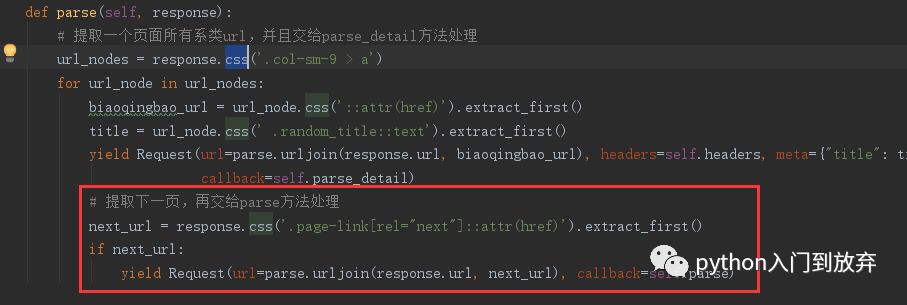
4、下一页
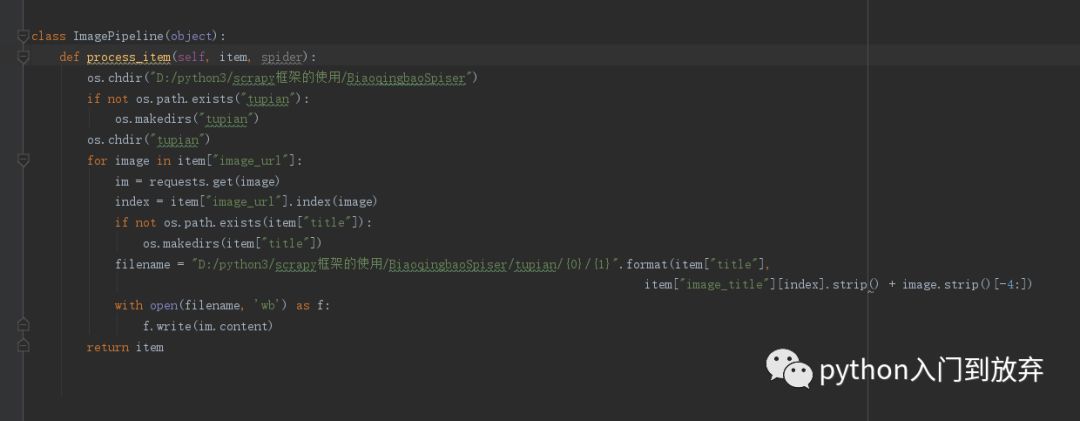
5、保存
因为对scrapy保存图片没有研究,所以就自己写保存图片的方法。
在pipelines.py种添加如下代码:
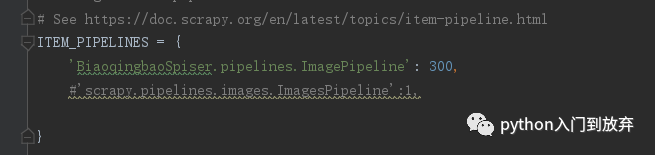
 并且在settings.py中添加:
并且在settings.py中添加:
6、运行
直接报错,因为有反扒机制,所以我们在settings.py添加头信息
运行一段时候后又报错了,看来需要随机更换表头信息。
这里我们使用第三方库很方便,pip3 install fake_useragent
安装成功后我们在middlewares.py中导入:from fake_useragent import UserAgent
添加如下代码:
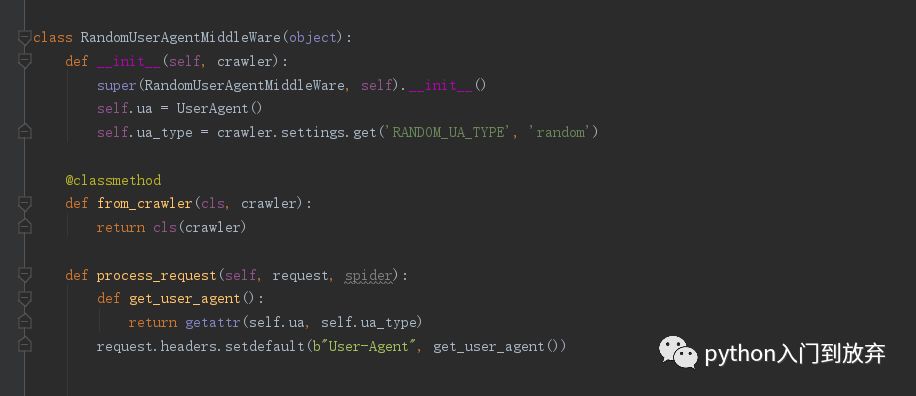
在settings.py文件中添加
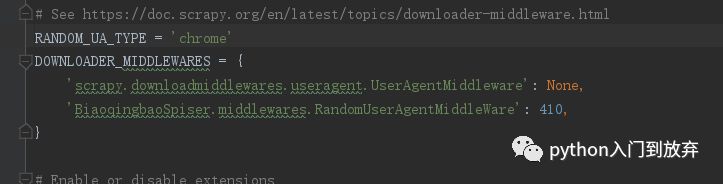
即可
运行main文件:
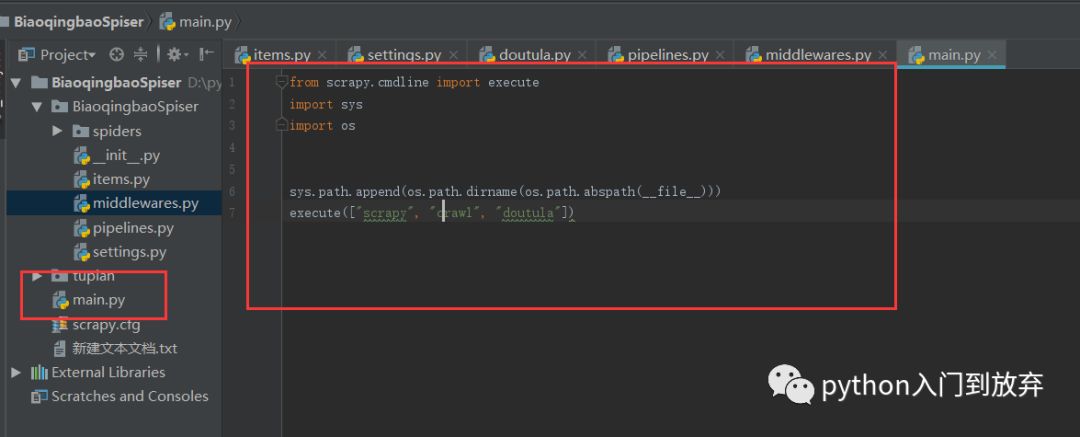
即可。
小结:
效果图:
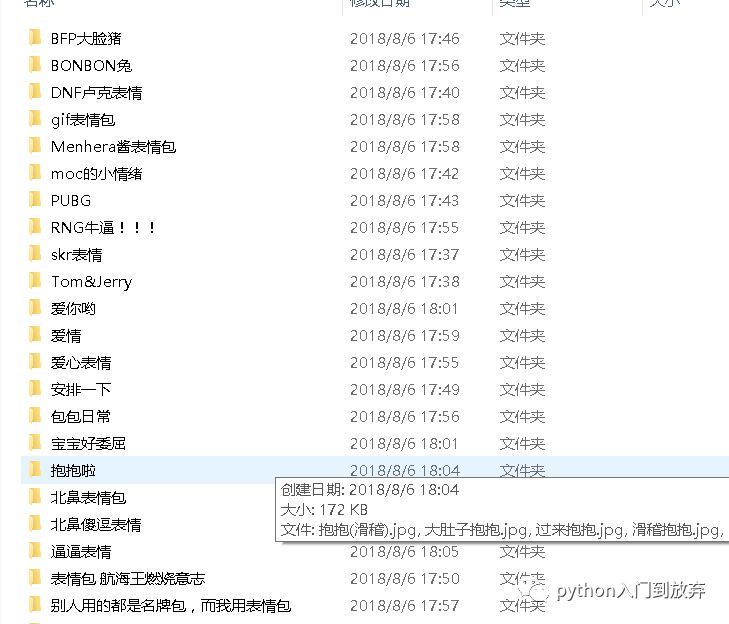
问题:
在运行过程中遇到了四个问题:
1、没有获取大到图片连接:
可能这个网站有两个版本获取的css方式不一样。
解决方法:可以使用xpath中的|(或)来解决
2、没有获取到图片名称
解决方法:同上
3、图片名称相同
解决方法:可以使用md5加密后添加,你也可以使用你自己的方法
4、在图片名中含有?/\等非法字符
解决方法:可以通过正则过滤,如果md5加密,那么一下解决两个问题。
虽然有些图片没有获取到,但是还是爬取了很多。
上述内容就是scrapy实战中怎样爬取表情包,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





