еҰӮдҪ•иҝӣиЎҢScrapyзҡ„е®үиЈ…дёҺеҹәжң¬дҪҝз”Ё
еҰӮдҪ•иҝӣиЎҢScrapyзҡ„е®үиЈ…дёҺеҹәжң¬дҪҝз”ЁпјҢй’ҲеҜ№иҝҷдёӘй—®йўҳпјҢиҝҷзҜҮж–Үз« иҜҰз»Ҷд»Ӣз»ҚдәҶзӣёеҜ№еә”зҡ„еҲҶжһҗе’Ңи§Јзӯ”пјҢеёҢжңӣеҸҜд»Ҙеё®еҠ©жӣҙеӨҡжғіи§ЈеҶіиҝҷдёӘй—®йўҳзҡ„е°ҸдјҷдјҙжүҫеҲ°жӣҙз®ҖеҚ•жҳ“иЎҢзҡ„ж–№жі•гҖӮ
дёҖгҖҒз®ҖеҚ•е®һдҫӢпјҢдәҶи§Јеҹәжң¬гҖӮ
1гҖҒе®үиЈ…ScrapyжЎҶжһ¶
иҝҷйҮҢеҰӮжһңзӣҙжҺҘpip3 install scrapyеҸҜиғҪдјҡеҮәй”ҷгҖӮ
жүҖд»ҘдҪ еҸҜд»Ҙе…Ҳе®үиЈ…lxmlпјҡpip3 install lxml(е·Іе®үиЈ…иҜ·еҝҪз•Ҙ)гҖӮ
е®үиЈ…pyOpenSSLпјҡеңЁе®ҳзҪ‘дёӢиҪҪwheelж–Ү件гҖӮ
е®үиЈ…TwistedпјҡеңЁе®ҳзҪ‘дёӢиҪҪwheelж–Ү件гҖӮ
е®үиЈ…PyWin32пјҡеңЁе®ҳзҪ‘дёӢиҪҪwheelж–Ү件гҖӮ
дёӢиҪҪең°еқҖпјҡhttps://www.lfd.uci.edu/~gohlke/pythonlibs/
й…ҚзҪ®зҺҜеўғеҸҳйҮҸпјҡе°ҶscrapyжүҖеңЁзӣ®еҪ•ж·»еҠ еҲ°зі»з»ҹзҺҜеўғеҸҳйҮҸеҚіеҸҜгҖӮ
ctrl+fжҗңзҙўеҚіеҸҜгҖӮ
жңҖеҗҺе®үиЈ…scrapyпјҢpip3 install scrapy
2гҖҒеҲӣе»әдёҖдёӘscrapyйЎ№зӣ®
ж–°еҲӣе»әдёҖдёӘзӣ®еҪ•пјҢжҢүдҪҸshift-еҸій”®-еңЁжӯӨеӨ„жү“ејҖе‘Ҫд»ӨзӘ—еҸЈ
иҫ“е…Ҙпјҡscrapy startproject tutorialеҚіеҸҜеҲӣе»әдёҖдёӘtutorialж–Ү件еӨ№
ж–Ү件еӨ№зӣ®еҪ•еҰӮдёӢпјҡ
|-tutorial
|-scrapy.cfg
|-__init__.py
|-items.py
|-middlewares.py
|-pipelines.py
|-settings.py
|-spiders
|-__init__.py
ж–Ү件зҡ„еҠҹиғҪпјҡ
scrapy.cfgпјҡй…ҚзҪ®ж–Ү件
spidersпјҡеӯҳж”ҫдҪ Spiderж–Ү件пјҢд№ҹе°ұжҳҜдҪ зҲ¬еҸ–зҡ„pyж–Ү件
items.pyпјҡзӣёеҪ“дәҺдёҖдёӘе®№еҷЁпјҢе’Ңеӯ—е…ёиҫғеғҸ
middlewares.pyпјҡе®ҡд№үDownloader Middlewares(дёӢиҪҪеҷЁдёӯй—ҙ件)е’ҢSpider Middlewares(иңҳиӣӣдёӯй—ҙ件)зҡ„е®һзҺ°
pipelines.py:е®ҡд№үItem Pipelineзҡ„е®һзҺ°пјҢе®һзҺ°ж•°жҚ®зҡ„жё…жҙ—пјҢеӮЁеӯҳпјҢйӘҢиҜҒгҖӮ
settings.pyпјҡе…ЁеұҖй…ҚзҪ®
3гҖҒеҲӣе»әдёҖдёӘspiderпјҲиҮӘе·ұе®ҡд№үзҡ„зҲ¬иҷ«ж–Ү件пјү
дҫӢеҰӮд»ҘзҲ¬еҸ–зҢ«зңјзғӯжҳ еҸЈзў‘жҰңдёәдҫӢеӯҗжқҘдәҶи§ЈдёҖдёӢпјҡ
еңЁspidersж–Ү件еӨ№дёӢеҲӣе»әдёҖдёӘmaoyan.pyж–Ү件пјҢдҪ д№ҹеҸҜд»ҘжҢүдҪҸshift-еҸій”®-еңЁжӯӨеӨ„жү“ејҖе‘Ҫд»ӨзӘ—еҸЈпјҢиҫ“е…Ҙпјҡscrapy genspider ж–Ү件еҗҚ иҰҒзҲ¬еҸ–зҡ„зҪ‘еқҖгҖӮ
иҮӘе·ұеҲӣе»әзҡ„йңҖиҰҒиҮӘе·ұеҶҷпјҢдҪҝз”Ёе‘Ҫд»ӨеҲӣе»әзҡ„еҢ…еҗ«жңҖеҹәжң¬зҡ„дёңиҘҝгҖӮ
жҲ‘们жқҘзңӢдёҖдёӢдҪҝз”Ёе‘Ҫд»ӨеҲӣе»әзҡ„жңүд»Җд№ҲгҖӮ

д»Ӣз»ҚдёҖдёӢиҝҷдәӣжҳҜе№Іеҳӣзҡ„пјҡ
nameпјҡжҳҜйЎ№зӣ®зҡ„еҗҚеӯ—
allowed_domainsпјҡжҳҜе…Ғи®ёзҲ¬еҸ–зҡ„еҹҹеҗҚпјҢжҜ”еҰӮдёҖдәӣзҪ‘з«ҷжңүзӣёе…ій“ҫжҺҘпјҢеҹҹеҗҚе°ұе’Ңжң¬зҪ‘з«ҷдёҚеҗҢпјҢиҝҷдәӣе°ұдјҡеҝҪз•ҘгҖӮ
atart_urlsпјҡжҳҜSpiderзҲ¬еҸ–зҡ„зҪ‘з«ҷпјҢе®ҡд№үеҲқе§Ӣзҡ„иҜ·жұӮurlпјҢеҸҜд»ҘеӨҡдёӘгҖӮ
parseж–№жі•пјҡжҳҜSpiderзҡ„дёҖдёӘж–№жі•пјҢеңЁиҜ·жұӮstart_urlеҗҺпјҢд№ӢеҗҺзҡ„ж–№жі•пјҢиҝҷдёӘж–№жі•жҳҜеҜ№зҪ‘йЎөзҡ„и§ЈжһҗпјҢдёҺжҸҗеҸ–иҮӘе·ұжғіиҰҒзҡ„дёңиҘҝгҖӮ
responseеҸӮж•°пјҡжҳҜиҜ·жұӮзҪ‘йЎөеҗҺиҝ”еӣһзҡ„еҶ…е®№пјҢд№ҹе°ұжҳҜдҪ йңҖиҰҒи§Јжһҗзҡ„зҪ‘йЎөгҖӮ
иҝҳжңүе…¶д»–еҸӮж•°жңүе…ҙи¶ЈеҸҜд»ҘеҺ»жҹҘжҹҘгҖӮ
4гҖҒе®ҡд№үItem
itemжҳҜдҝқеӯҳзҲ¬еҸ–ж•°жҚ®зҡ„е®№еҷЁпјҢдҪҝз”Ёзҡ„ж–№жі•е’Ңеӯ—е…ёе·®дёҚеӨҡгҖӮ
жҲ‘们жү“ејҖitems.pyпјҢд№ӢеҗҺжҲ‘们жғіиҰҒжҸҗеҸ–зҡ„дҝЎжҒҜжңүпјҡ
index(жҺ’еҗҚ)гҖҒtitle(з”өеҪұеҗҚ)гҖҒstar(дё»жј”)гҖҒreleasetime(дёҠжҳ ж—¶й—ҙ)гҖҒscore(иҜ„еҲҶ)
дәҺжҳҜжҲ‘们е°Ҷitems.pyж–Ү件дҝ®ж”№жҲҗиҝҷж ·гҖӮ
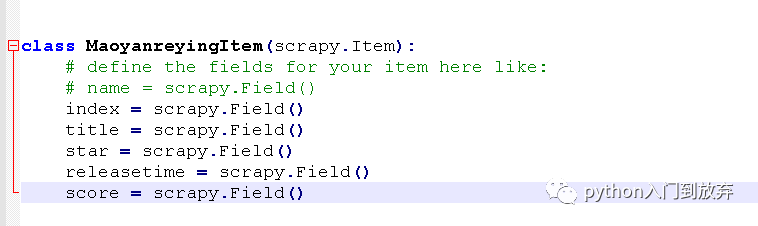
еҚіеҸҜгҖӮ
5гҖҒеҶҚж¬Ўжү“ејҖspiderжқҘжҸҗеҸ–жҲ‘们жғіиҰҒзҡ„дҝЎжҒҜ
дҝ®ж”№жҲҗиҝҷж ·пјҡ

еҘҪдәҶпјҢдёҖдёӘз®ҖеҚ•зҡ„зҲ¬иҷ«е°ұеҶҷе®ҢдәҶгҖӮ
6гҖҒиҝҗиЎҢ
еңЁиҜҘж–Ү件еӨ№дёӢпјҢжҢүдҪҸshift-еҸій”®-еңЁжӯӨеӨ„жү“ејҖе‘Ҫд»ӨзӘ—еҸЈпјҢиҫ“е…Ҙпјҡscrapy crawl maoyan(йЎ№зӣ®зҡ„еҗҚеӯ—)
еҚіеҸҜзңӢеҲ°пјҡ
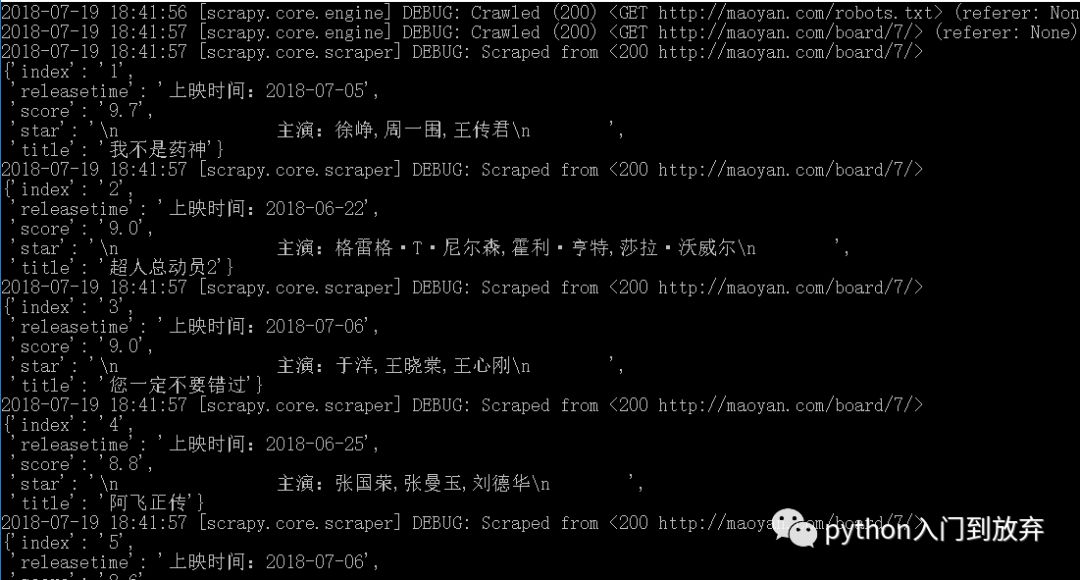
7гҖҒдҝқеӯҳ
жҲ‘们еҸӘиҝҗиЎҢдәҶд»Јз ҒпјҢзңӢзңӢжңүжІЎжңүжҠҘй”ҷпјҢ并没жңүдҝқеӯҳгҖӮ
еҰӮжһңжҲ‘们жғідҝқеӯҳдёәcsvгҖҒxmlгҖҒjsonж јејҸпјҢеҸҜд»ҘзӣҙжҺҘдҪҝз”Ёе‘Ҫд»Өпјҡ
еңЁиҜҘж–Ү件еӨ№дёӢпјҢжҢүдҪҸshift-еҸій”®-еңЁжӯӨеӨ„жү“ејҖе‘Ҫд»ӨзӘ—еҸЈпјҢиҫ“е…Ҙпјҡ
scrapy crawl maoyan -o maoyan.csv
scrapy crawl maoyan -o maoyan.xml
scrapy crawl maoyan -o maoyan.json
йҖүжӢ©е…¶дёӯдёҖдёӘеҚіеҸҜгҖӮеҪ“然еҰӮжһңжғіиҰҒдҝқеӯҳдёәе…¶д»–ж јејҸд№ҹжҳҜеҸҜд»Ҙзҡ„пјҢиҝҷйҮҢеҸӘиҜҙеёёи§Ғзҡ„гҖӮиҝҷйҮҢйҖүжӢ©jsonж јејҸпјҢиҝҗиЎҢеҗҺдјҡеҸ‘зҺ°пјҢеңЁж–Ү件еӨ№дёӢеӨҡеҮәжқҘдёҖдёӘmaoyan.jsonзҡ„ж–Ү件гҖӮжү“ејҖд№ӢеҗҺеҸ‘зҺ°пјҢдёӯж–ҮйғҪжҳҜдёҖдёІд№ұз ҒпјҢиҝҷйҮҢйңҖиҰҒдҝ®ж”№зј–з Ғж–№ејҸпјҢеҪ“然д№ҹеҸҜд»ҘеңЁй…ҚзҪ®йҮҢдҝ®ж”№
пјҲеңЁsettings.pyж–Ү件дёӯж·»еҠ FEED_EXPORT_ENCODING='UTF8'еҚіеҸҜпјүпјҢ
еҰӮжһңжғізӣҙжҺҘеңЁе‘Ҫд»ӨиЎҢдёӯдҝ®ж”№пјҡ
scrapy crawl maoyan -o maoyan.json -s FEED_EXPORT_ENCODING=UTF8
еҚіеҸҜгҖӮ
иҝҷйҮҢиҮӘе·ұиҜ•иҜ•ж•Ҳжһңеҗ§гҖӮ
еҪ“然жҲ‘们дҝқеӯҳд№ҹеҸҜд»ҘеңЁиҝҗиЎҢзҡ„ж—¶еҖҷиҮӘеҠЁдҝқеӯҳпјҢдёҚйңҖиҰҒиҮӘе·ұеҶҷе‘Ҫд»ӨгҖӮеҗҺйқўд»Ӣз»ҚпјҲжҲ‘们иҝҳжңүиҝҳеӨҡж–Ү件没жңүз”ЁеҲ°е‘ҰпјүгҖӮ
дәҢгҖҒscrapyеҰӮдҪ•и§Јжһҗпјҹ
д№ӢеүҚеҶҷиҝҮдёҖзҜҮж–Үз« пјҡдёүеӨ§и§Јжһҗеә“зҡ„дҪҝз”Ё
дҪҶжҳҜscrapyд№ҹжҸҗдҫӣдәҶиҮӘе·ұзҡ„и§Јжһҗж–№ејҸпјҲSelectorпјүпјҢе’ҢдёҠйқўзҡ„д№ҹеҫҲзӣёдјјпјҢжҲ‘们жқҘзңӢдёҖдёӢпјҡ
1гҖҒcss
йҰ–е…ҲйңҖиҰҒеҜје…ҘжЁЎеқ—пјҡfrom scrapy import Selector
дҫӢеҰӮжңүиҝҷж ·дёҖж®өhtmlд»Јз Ғпјҡ
html='<html><head><title>Demo</title><body>
<div class='cla'>This is Demo</div></body></head></html>'
1.1гҖҒйҰ–е…ҲйңҖиҰҒжһ„е»әдёҖдёӘSelectorеҜ№иұЎ
sel = Selector(html)
text = sel.css('.cla::text').extract_first()
.claиЎЁзӨәйҖүдёӯдёҠйқўзҡ„divиҠӮзӮ№пјҢ::textиЎЁзӨәиҺ·еҸ–ж–Үжң¬пјҢиҝҷйҮҢе’Ңд»ҘеүҚзҡ„жңүжүҖдёҚеҗҢгҖӮ
extract_first()иЎЁзӨәиҝ”еӣһ第дёҖдёӘе…ғзҙ пјҢеӣ дёәдёҠиҝ° sel.css('.cla::text')иҝ”еӣһзҡ„жҳҜдёҖдёӘеҲ—иЎЁпјҢдҪ д№ҹеҸҜд»ҘеҶҷжҲҗsel.css('.cla::text')[0]жқҘиҺ·еҸ–第дёҖдёӘе…ғзҙ пјҢдҪҶжҳҜеҰӮжһңдёәз©әпјҢе°ұдјҡжҠҘеҮәи¶…еҮәжңҖеӨ§зҙўеј•зҡ„й”ҷиҜҜпјҢдёҚе»әи®®иҝҷж ·еҶҷпјҢиҖҢдҪҝз”Ёextract_first()е°ұдёҚдјҡжҠҘй”ҷпјҢеҗҢж—¶еҰӮжһңеҶҷжҲҗextract_first('123')иҝҷж ·пјҢеҰӮжһңдёәз©әе°ұиҝ”еӣһ123
1.2гҖҒжңүдәҶйҖүеҸ–第дёҖдёӘпјҢе°ұжңүйҖүеҸ–жүҖжңүпјҡextract()иЎЁзӨәйҖүеҸ–жүҖжңүпјҢеҰӮжһңиҝ”еӣһзҡ„жҳҜеӨҡдёӘеҖјпјҢе°ұеҸҜд»ҘжҳҜиҝҷж ·еҶҷгҖӮ
1.3гҖҒиҺ·еҸ–еұһжҖ§е°ұжҳҜsel.css('.cla::attr('class')').extract_first()иЎЁзӨәиҺ·еҸ–class
1.4гҖҒиҺ·еҸ–жҢҮе®ҡеұһжҖ§зҡ„ж–Үжң¬пјҡsel.css('div[class="cla"]::text')
1.5гҖҒе…¶д»–еҶҷжі•е’Ңcssзҡ„еҶҷжі•еҰӮеҮәдёҖиҫҷгҖӮ
1.6гҖҒеңЁscrapyдёӯдёәжҲ‘们жҸҗдҫӣдәҶдёҖдёӘз®Җдҫҝзҡ„еҶҷжі•пјҢеңЁдёҠиҝ°зҡ„з®ҖеҚ•е®һдҫӢдёӯпјҢжҲ‘们зҹҘйҒ“дәҶresponseдёәиҜ·жұӮзҪ‘йЎөзҡ„иҝ”еӣһеҖјгҖӮ
жҲ‘们еҸҜд»ҘзӣҙжҺҘеҶҷжҲҗпјҡresponse.css()жқҘи§ЈжһҗпјҢжҸҗеҸ–жҲ‘们жғіиҰҒзҡ„дҝЎжҒҜгҖӮеҗҢж ·пјҢдёӢйқўиҰҒиҜҙзҡ„XPathд№ҹеҸҜд»ҘзӣҙжҺҘеҶҷжҲҗпјҡ
response.xpath()жқҘи§ЈжһҗгҖӮ
2гҖҒXpath
Xpathзҡ„дҪҝз”ЁеҸҜд»ҘзңӢдёҠйқўзҡ„ж–Үз« пјҡдёүеӨ§и§Јжһҗеә“зҡ„дҪҝз”Ё
жіЁж„ҸпјҡиҺ·еҸ–зҡ„иҝҳжҳҜеҲ—иЎЁпјҢжүҖд»ҘиҝҳжҳҜиҰҒеҠ дёҠextract_first()жҲ–иҖ…extract()
3гҖҒжӯЈеҲҷеҢ№й…Қ(иҝҷйҮҢз”Ёresponseж“ҚдҪң)
дҫӢеҰӮпјҡresponse.css('a::text').re('еҶҷжӯЈеҲҷ')
иҝҷйҮҢеҰӮжһңresponse.css('a::text')еҢ№й…Қзҡ„жҳҜеӨҡдёӘеҜ№иұЎпјҢйӮЈд№ҲеҠ дёҠжӯЈеҲҷд№ҹжҳҜеҢ№й…Қз¬ҰеҗҲиҰҒжұӮзҡ„еӨҡдёӘеҜ№иұЎгҖӮ
иҝҷйҮҢеҰӮжһңжғіиҰҒеҢ№й…Қ第дёҖдёӘеҜ№иұЎпјҢеҸҜд»ҘжҠҠre()дҝ®ж”№жҲҗre_first()еҚіеҸҜгҖӮ
жіЁж„ҸпјҡresponseдёҚеҸҜд»ҘзӣҙжҺҘи°ғз”Ёre(),response.xpath('.').re()еҸҜд»ҘзӣёеҪ“дәҺиҫҫеҲ°зӣҙжҺҘдҪҝз”ЁжӯЈеҲҷзҡ„ж•ҲжһңгҖӮ
жӯЈеҲҷзҡ„дҪҝз”ЁпјҡдёҮиғҪзҡ„жӯЈеҲҷиЎЁиҫҫејҸ
дёүгҖҒDowmloader Middlewareзҡ„дҪҝз”Ё
жң¬иә«scrapyе°ұжҸҗдҫӣдәҶеҫҲеӨҡDowmloader MiddlewareпјҢдҪҶжҳҜжңүж—¶еҖҷжҲ‘们иҰҒдҝ®ж”№пјҢ
жҜ”еҰӮдҝ®ж”№User-AgentпјҢдҪҝз”Ёд»ЈзҗҶipзӯүгҖӮ
д»Ҙдҝ®ж”№User-AgentдёәдҫӢпјҲи®ҫзҪ®д»ЈзҗҶipеӨ§еҗҢе°ҸејӮпјүпјҡ
第дёҖз§Қж–№жі•пјҢеҸҜд»ҘеңЁsettings.pyдёӯзӣҙжҺҘж·»еҠ USER-AGENT='xxx'
дҪҶжҳҜжҲ‘们жғіиҰҒж·»еҠ еӨҡдёӘUser-AgentпјҢжҜҸж¬ЎйҡҸжңәиҺ·еҸ–дёҖдёӘеҸҜд»ҘеҲ©з”ЁDowmloader MiddlewareжқҘи®ҫзҪ®гҖӮ
第дёҖжӯҘе°Ҷsettingsдёӯзҡ„USER-AGENT='xxx'дҝ®ж”№жҲҗUSER-AGENT=["xxx","xxxxx","xxxxxxx"]
第дәҢжӯҘеңЁmiddlewares.pyдёӯж·»еҠ пјҡ

from_crawler():йҖҡиҝҮеҸӮж•°crawlerеҸҜд»ҘжӢҝеҲ°й…ҚзҪ®зҡ„дҝЎжҒҜпјҢжҲ‘们зҡ„User-AgentеңЁй…ҚзҪ®ж–Ү件йҮҢпјҢжүҖд»ҘжҲ‘们йңҖиҰҒиҺ·еҸ–еҲ°гҖӮ
ж–№жі•еҗҚдёҚеҸҜд»Ҙдҝ®ж”№гҖӮ
第дёүжӯҘеңЁsettings.pyдёӯж·»еҠ пјҡ

е°ҶscrapyиҮӘеёҰзҡ„UserAgentmiddlewareзҡ„й”®еҖји®ҫзҪ®дёәNone,
иҮӘе®ҡд№үзҡ„и®ҫзҪ®дёә400пјҢиҝҷдёӘй”®еҖји¶Ҡе°ҸиЎЁзӨәдјҳе…Ҳи°ғз”Ёзҡ„ж„ҸжҖқгҖӮ
еӣӣгҖҒItem Pipelineзҡ„дҪҝз”ЁгҖӮ
1гҖҒиҝӣиЎҢж•°жҚ®зҡ„жё…жҙ—
еңЁдёҖзҡ„е®һдҫӢдёӯжҲ‘们жҠҠиҜ„еҲҶе°ҸдәҺзӯүдәҺ8.5еҲҶзҡ„scoreдҝ®ж”№дёәпјҲдёҚеҘҪзңӢпјҒпјүпјҢжҲ‘们и®ӨдёәжҳҜдёҚеҘҪзңӢзҡ„з”өеҪұпјҢжҲ‘们е°Ҷpipeline.pyдҝ®ж”№жҲҗиҝҷж ·пјҡ

еңЁsetting.pyдёӯж·»еҠ пјҡ

жҲ‘们жү§иЎҢдёҖдёӢпјҡ

2гҖҒеӮЁеӯҳ
2.1еӮЁеӯҳдёәjsonж јејҸ
жҲ‘们е°Ҷpipeline.pyдҝ®ж”№жҲҗиҝҷж ·пјҡ
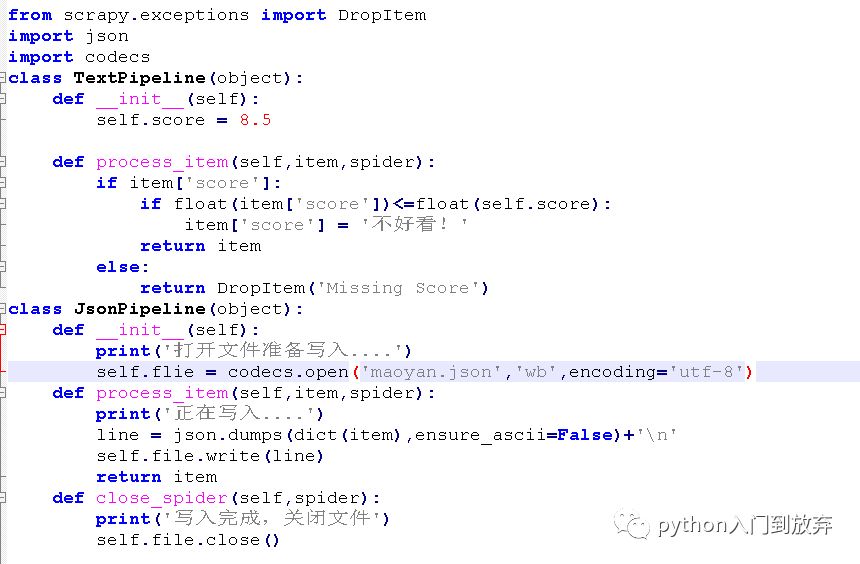
еңЁsetting.pyдёӯж·»еҠ пјҡ

иЎЁзӨәе…Ҳжү§иЎҢTextPipelineж–№жі•пјҢеҶҚжү§иЎҢJsonPipelineж–№жі•пјҢе…Ҳжё…жҙ—пјҢеҶҚеӮЁеӯҳгҖӮ
2.2еӮЁеӯҳеңЁmysqlж•°жҚ®еә“
йҰ–е…ҲеңЁmysqlж•°жҚ®еә“дёӯеҲӣе»әдёҖдёӘж•°жҚ®еә“maoyanreyingпјҢеҲӣе»әдёҖдёӘиЎЁmaoyanгҖӮ
жҲ‘们е°Ҷpipeline.pyдҝ®ж”№жҲҗиҝҷж ·пјҡ
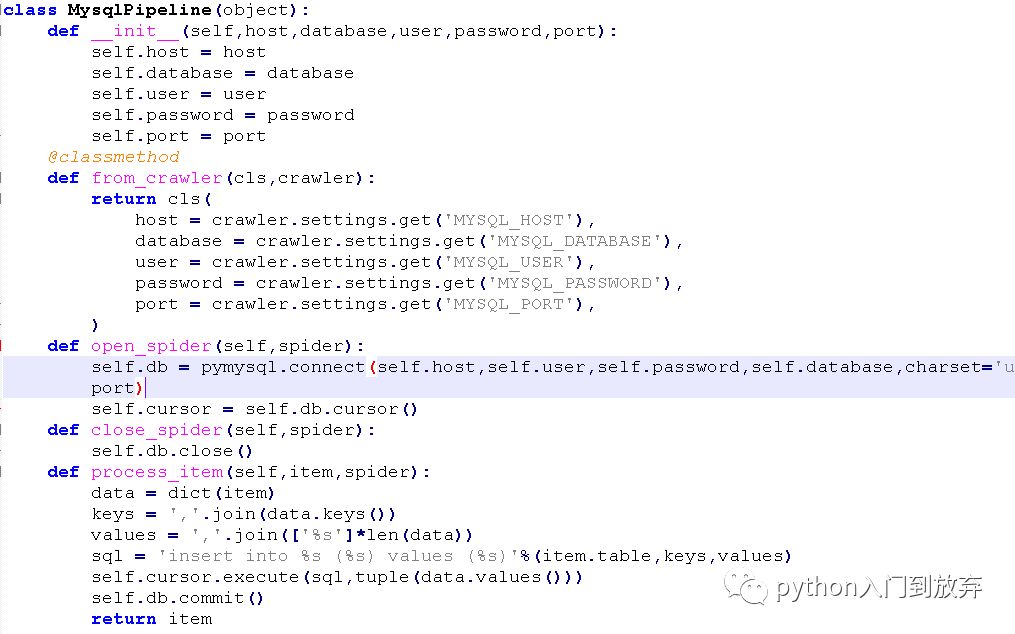
еңЁsetting.pyдёӯж·»еҠ пјҡ
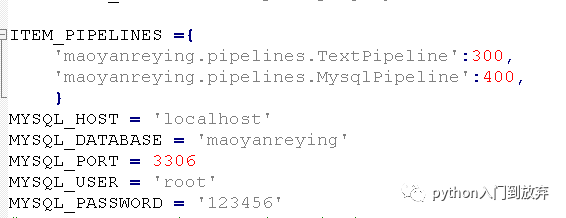
еҚіеҸҜ
е®ҢгҖӮ
е…ідәҺеҰӮдҪ•иҝӣиЎҢScrapyзҡ„е®үиЈ…дёҺеҹәжң¬дҪҝз”Ёй—®йўҳзҡ„и§Јзӯ”е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҰӮжһңдҪ иҝҳжңүеҫҲеӨҡз–‘жғ‘жІЎжңүи§ЈејҖпјҢеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“дәҶи§ЈжӣҙеӨҡзӣёе…ізҹҘиҜҶгҖӮ





