本篇文章给大家分享的是有关Fluentd事件的生命周期有哪些,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
什么是事件?
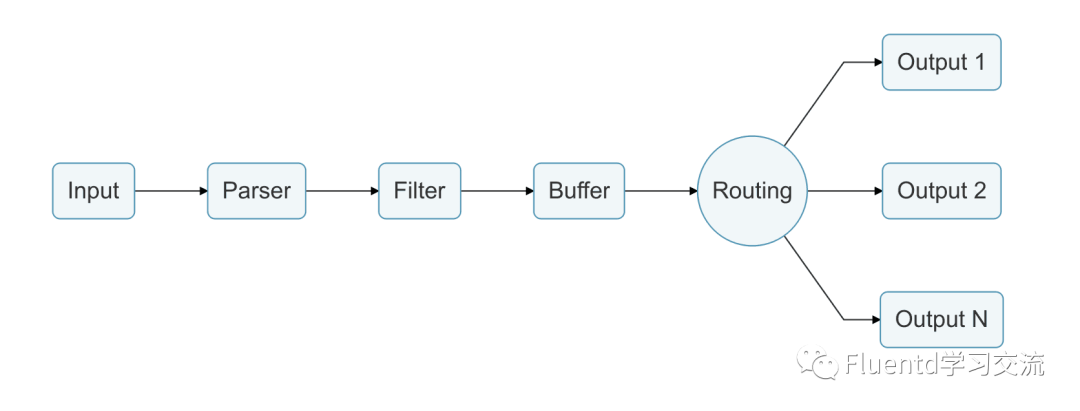
事件(Event)是Fluentd内部处理流程使用的数据结构,日志记录一旦进入Fluentd便被封装成一个event。Event由三部分组成:tag、time、record。
tag标识事件的来源,或者说类型,用于内部消息路由,即后续交由哪个插件处理;
time是事件的发生时间;
record为日志的实际内容,这是一个JSON对象。
Input插件负责将源数据封装为event,比如in_tail插件从文本中生成event。对于下边这行文本:
192.168.0.1 - - [28/Feb/2013:12:00:00 +0900] "GET / HTTP/1.1" 200 777
将会产生下边的event对象:
tag: apache.access #根据插件的tag参数来设置
time: 1362020400 # 28/Feb/2013:12:00:00 +0900
record: {"user":"-","method":"GET","code":200,"size":777,"host":"192.168.0.1","path":"/"} #根据in_tail插件中的parse项来决定如何解析单行日志记录,并生成相应的JSON对象
下边我们通过一个具体的配置来讲解事件的处理过程。
本例使用一个很基础的配置片段来描述各插件是如何关联到一起的,它包括了如何定义输入源(或者说监听器),以及如何设置通用的匹配规则将event路由到输出端。
我们使用in_http和out_stdout这两个插件来描述event的循环过程。
<source> @type http port 8888 bind 0.0.0.0</source>上边的配置使用in_http插件定义了一个HTTP服务器,监听端口为8888。然后我们再定义一个匹配(Match)规则,event路由引擎会根据这个规则将http请求派发到输出端。这里的输出端是stdout,仅仅将http请求打印到屏幕上。
<match test.cycle> @type stdout </match>Match的作用是设置一个匹配规则test.cycle,对于每个进入Fluentd的event,如果其tag值和test.cycle相等(或者说匹配,因为match可以使用通配符。这里的tag是由in_http插件生成的。),那么这个event就会进入此match定义的output插件,本例中的output插件就是out_stdout。
至此,我们定义了三个基本项:Input、Match和Output,虽然仅仅使用两个配置段。这就是一个可以使用的采集配置了,可以通过以下命令进行测试:
curl -i -X POST -d 'json={"action":"login","user":2}' http://localhost:8888/test.cycle你会看到如下输出:
HTTP/1.1 200 OKContent-Type: text/plainConnection: Keep-AliveContent-Length: 0
在/var/log/td-agent.log中会有如下输出:
2020-03-05 14:06:24.144168913 +0800 test.cycle: {"action":"login","user":2}过滤器(Filters)
过滤器用于对事件进行筛选,决定是否接收或者丢弃事件。我们可以在上边的示例中增加一个过滤器。
<source> @type http port 8888 bind 0.0.0.0</source><filter test.cycle> @type grep <exclude> key action pattern ^logout$ </exclude></filter><match test.cycle> @type stdout</match>添加过滤器之后,事件在路由到match之前必须经过过滤器的处理。过滤器根据事件的类型和过滤规则来决定是否接受此事件。
我们示例中使用的是grep过滤器,这个过滤器对test.cycle这类事件进行过滤,会排除http请求中action值为logout的事件。
所以,如果尝试发送下边的请求,在td-agent.log中是看不到任何输出的。
curl -i -X POST -d 'json={"action":"logout","user":2}' http://localhost:8888/test.cycle从示例中可以看到,事件是根据配置顺序自上而下来被处理的。我们可以根据需要配置任意多个过滤器,这样一来,配置文件会变得很长很复杂。Fluentd提供了标签来解决此问题。
标签(Labels)
标签的作用是用来定义一组配置项,这组配置项可以被其他配置项引用,从而实现事件路由跳转。类似编程语言中的goto的功能。
还是上边的示例,我们定义一个标签来看一下效果。
<source> @type http bind 0.0.0.0 port 8888 @label @STAGING</source><filter test.cycle> @type grep <exclude> key action pattern ^login$ </exclude></filter><label @STAGING> <filter test.cycle> @type grep <exclude> key action pattern ^logout$ </exclude> </filter> <match test.cycle> @type stdout </match></label>这个STARTING标签将之前的filter和match封装到了一起,然后在source中进行了引用。如此一来,事件由input插件生成后将会跳过那个独立的filter,直接进入STARTING定义的处理流程中。
缓存(Buffers)
我们看到了事件从input产生,经由filter筛选,最后到达output的过程。在上边的示例中,我们使用的是stdout插件直接输出到控制台,并没有经过缓存。
实际应用中,一般会先把数据进行缓存,达到一定条件后再flush到目标存储中。这样可以提升系统可靠性,对于稳定系统吞吐量也很重要。可在后续文章中共同了解更多关于缓存插件的知识。
以上就是Fluentd事件的生命周期有哪些,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/fluentd/blog/4354335



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



