前言:
HDFS 是一个能够面向大规模数据使用的,可进行扩展的文件存储与传递系统。是一种允许文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和 存储空间。让实际上是通过网络来访问文件的动作,由程序与用户看来,就像是访问本地的磁盘一般。即使系统中有某些节点脱机,整体来说系统仍然可以持续运作 而不会有数据损失。
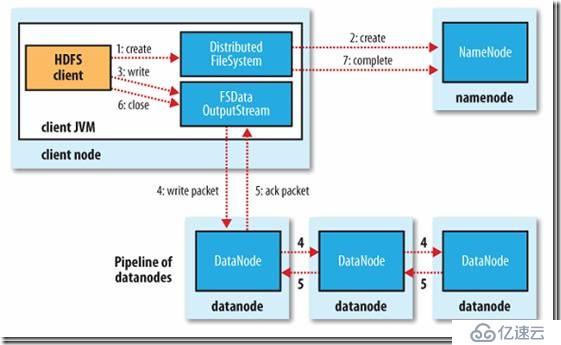

参考:
https://blog.csdn.net/gaijianwei/article/details/45918337
https://www.cnblogs.com/xubiao/p/5579080.html
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





