Mysqlдёӯзҡ„B-Treeзҙўеј•зҡ„еә•еұӮз»“жһ„д»ҘеҸҠдҪҝз”ЁеҺҹеҲҷе’Ңзү№жҖ§
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңMysqlдёӯзҡ„B-Treeзҙўеј•зҡ„еә•еұӮз»“жһ„д»ҘеҸҠдҪҝз”ЁеҺҹеҲҷе’Ңзү№жҖ§вҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁMysqlдёӯзҡ„B-Treeзҙўеј•зҡ„еә•еұӮз»“жһ„д»ҘеҸҠдҪҝз”ЁеҺҹеҲҷе’Ңзү№жҖ§й—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқMysqlдёӯзҡ„B-Treeзҙўеј•зҡ„еә•еұӮз»“жһ„д»ҘеҸҠдҪҝз”ЁеҺҹеҲҷе’Ңзү№жҖ§вҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
MySQLжҳҜзӣ®еүҚдёҡз•ҢжңҖдёәжөҒиЎҢзҡ„е…ізі»еһӢж•°жҚ®еә“д№ӢдёҖпјҢиҖҢзҙўеј•зҡ„дјҳеҢ–д№ҹжҳҜж•°жҚ®еә“жҖ§иғҪдјҳеҢ–зҡ„е…ій”®д№ӢдёҖгҖӮжүҖд»ҘпјҢе……еҲҶең°дәҶи§ЈMySQLзҙўеј•жңүеҠ©дәҺжҸҗеҚҮејҖеҸ‘дәәе‘ҳеҜ№MySQLж•°жҚ®еә“зҡ„дҪҝз”ЁдјҳеҢ–иғҪеҠӣгҖӮ
MySQLзҡ„зҙўеј•жңүеҫҲеӨҡз§Қзұ»еһӢпјҢеҸҜд»ҘдёәдёҚеҗҢзҡ„еңәжҷҜжҸҗдҫӣжӣҙеҘҪзҡ„жҖ§иғҪгҖӮиҖҢB-Treeзҙўеј•жҳҜжңҖдёәеёёи§Ғзҡ„MySQLзҙўеј•зұ»еһӢпјҢдёҖиҲ¬и°Ҳи®әMySQLзҙўеј•ж—¶пјҢеҰӮжһңжІЎжңүзү№еҲ«иҜҙжҳҺпјҢе°ұжҳҜжҢҮB-Treeзҙўеј•гҖӮжң¬ж–Үе°ұиҜҰз»Ҷи®Іи§ЈдёҖдёӢB-Treeзҙўеј•зҡ„еә•еұӮз»“жһ„пјҢдҪҝз”ЁеҺҹеҲҷе’Ңзү№жҖ§гҖӮ
дёәдәҶиҠӮзәҰдҪ зҡ„ж—¶й—ҙпјҢжң¬ж–Үзҡ„дё»иҰҒеҶ…е®№еҰӮдёӢпјҡ
- B-Treeзҙўеј•зҡ„еә•еұӮз»“жһ„
B-Treeзҙўеј•зҡ„дҪҝ用规еҲҷ
иҒҡз°Үзҙўеј•
InnoDBе’ҢMyISAMеј•ж“Һзҙўеј•зҡ„е·®ејӮ
жқҫж•Јзҙўеј•
иҰҶзӣ–зҙўеј•
B-Treeзҙўеј•
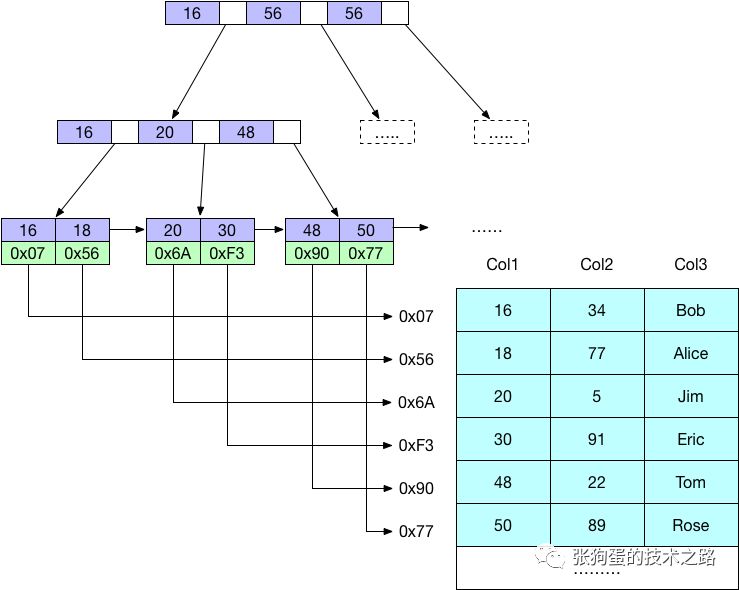
B-Treeзҙўеј•дҪҝз”ЁB-TreeжқҘеӯҳеӮЁж•°жҚ®пјҢеҪ“然дёҚеҗҢеӯҳеӮЁеј•ж“Һзҡ„е®һзҺ°ж–№ејҸдёҚеҗҢгҖӮB-TreeйҖҡеёёж„Ҹе‘ізқҖжүҖжңүзҡ„еҖјйғҪжҳҜжҢүйЎәеәҸеӯҳеӮЁзҡ„пјҢ并且жҜҸдёҖдёӘеҸ¶еӯҗйЎөеҲ°ж №зҡ„и·қзҰ»зӣёеҗҢпјҢдёӢеӣҫеұ•зӨәдәҶB-Treeзҙўеј•зҡ„жҠҪиұЎиЎЁзӨәпјҢз”ұжӯӨеҸҜд»ҘзңӢеҮәMySQLзҡ„B-Treeзҙўеј•зҡ„еӨ§иҮҙе·ҘдҪңжңәеҲ¶гҖӮ
B-Treeзҙўеј•зҡ„еә•еұӮж•°жҚ®з»“жһ„дёҖиҲ¬жҳҜB+ж ‘пјҢе…¶е…·дҪ“ж•°жҚ®з»“жһ„е’ҢдјҳеҠҝиҝҷйҮҢе°ұдёҚдҪңиҜҰз»ҶжҸҸиҝ°пјҢдёӢеӣҫеұ•зӨәдәҶB-ж ‘зҙўеј•зҡ„жҠҪиұЎиЎЁзӨәпјҢеӨ§иҮҙеҸҚеә”дәҶMyISAMзҙўеј•жҳҜеҰӮдҪ•е·ҘдҪңзҡ„пјҢиҖҢInnoDBдҪҝз”Ёзҡ„з»“жһ„жңүжүҖдёҚеҗҢгҖӮ
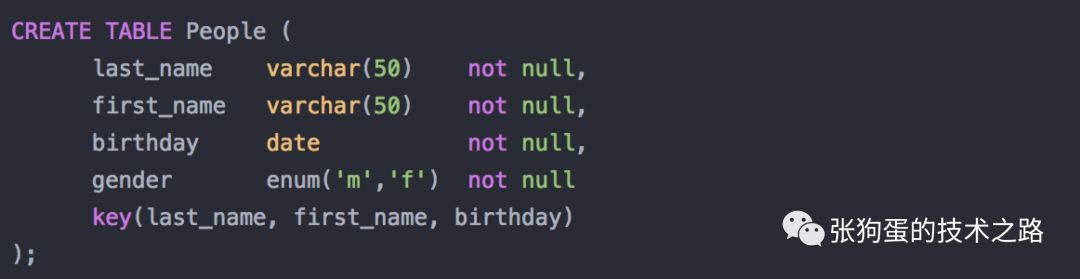
MySQLеҸҜд»ҘеңЁеҚ•зӢ¬дёҖеҲ—дёҠж·»еҠ B-Treeзҙўеј•пјҢд№ҹеҸҜд»ҘеңЁеӨҡеҲ—ж•°жҚ®дёҠж·»еҠ B-Treeзҙўеј•пјҢеӨҡеҲ—зҡ„ж•°жҚ®жҢүз…§ж·»еҠ зҙўеј•еЈ°жҳҺзҡ„йЎәеәҸз»„еҗҲиө·жқҘпјҢеӯҳеӮЁеңЁB-Treeзҡ„йЎөдёӯгҖӮеҒҮи®ҫжңүеҰӮдёӢж•°жҚ®иЎЁпјҡ
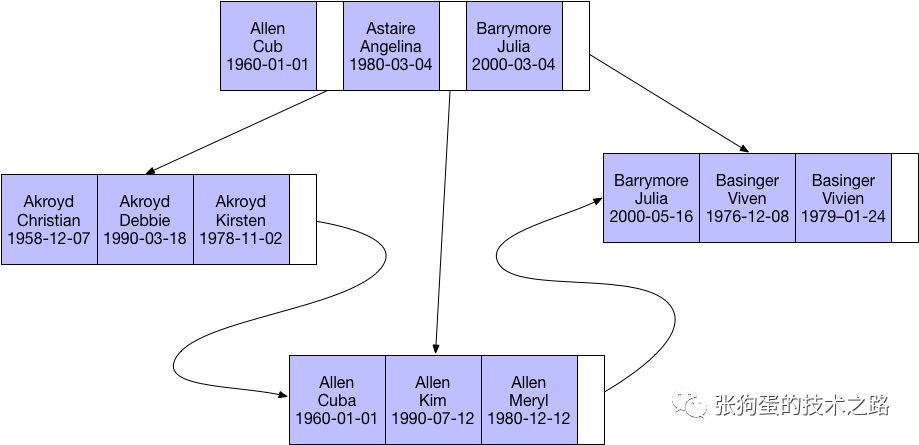
еҜ№дәҺиЎЁдёӯзҡ„жҜҸдёҖиЎҢж•°жҚ®пјҢзҙўеј•дёӯеҢ…еҗ«дәҶlast_nameпјҢfirst_nameе’ҢbirthdayеҲ—зҡ„еҖјпјҢдёӢеӣҫеұ•зӨәдәҶиҜҘзҙўеј•жҳҜеҰӮдҪ•з»„з»Үж•°жҚ®зҡ„еӯҳеӮЁзҡ„гҖӮ
B-Treeзҙўеј•дҪҝз”ЁB-TreeдҪңдёәе…¶еӯҳеӮЁж•°жҚ®зҡ„ж•°жҚ®з»“жһ„пјҢе…¶дҪҝз”Ёзҡ„жҹҘиҜўи§„еҲҷд№ҹз”ұжӯӨеҶіе®ҡгҖӮдёҖиҲ¬жқҘиҜҙпјҢB-Treeзҙўеј•йҖӮз”ЁдәҺе…Ёй”®еҖјгҖҒй”®еҖјиҢғеӣҙе’Ңй”®еүҚзјҖжҹҘжүҫпјҢе…¶дёӯй”®еүҚзјҖжҹҘжүҫеҸӘйҖӮз”ЁдәҺж №жҚ®жңҖе·ҰеүҚзјҖжҹҘжүҫгҖӮB-Treeзҙўеј•ж”ҜжҢҒзҡ„жҹҘиҜўеҺҹеҲҷеҰӮдёӢжүҖзӨәпјҡ
е…ЁеҖјеҢ№й…Қпјҡе…ЁеҖјеҢ№й…ҚжҢҮзҡ„жҳҜе’Ңзҙўеј•дёӯзҡ„жүҖжңүеҲ—иҝӣиЎҢеҢ№й…ҚгҖӮ
еҢ№й…ҚжңҖе·ҰеүҚзјҖпјҡеүҚиҫ№жҸҗеҲ°зҡ„зҙўеј•еҸҜд»Ҙз”ЁдәҺжҹҘжүҫжүҖжңү姓Allenзҡ„дәәпјҢеҚіеҸӘдҪҝз”Ёзҙўеј•дёӯзҡ„第дёҖеҲ—гҖӮ
еҢ№й…ҚеҲ—еүҚзјҖпјҡд№ҹеҸҜд»ҘеҸӘеҢ№й…ҚжҹҗдёҖеҲ—зҡ„еҖјзҡ„ејҖеӨҙйғЁеҲҶгҖӮдҫӢеҰӮеүҚйқўжҸҗеҲ°зҡ„зҙўеј•еҸҜз”ЁдәҺжҹҘжүҫжүҖжңүд»ҘJејҖеӨҙзҡ„姓зҡ„дәәгҖӮиҝҷйҮҢд№ҹеҸӘз”ЁеҲ°дәҶзҙўеј•зҡ„第дёҖеҲ—гҖӮ
еҢ№й…ҚиҢғеӣҙеҖјпјҡдҫӢеҰӮеүҚиҫ№жҸҗеҲ°зҡ„зҙўеј•еҸҜз”ЁдәҺжҹҘжүҫ姓еңЁAllenе’ҢBarrymoreд№Ӣй—ҙзҡ„дәәгҖӮиҝҷйҮҢд№ҹеҸӘдҪҝз”ЁдәҶзҙўеј•зҡ„第дёҖеҲ—гҖӮ
зІҫзЎ®еҢ№й…ҚжҹҗдёҖеҲ—并иҢғеӣҙеҢ№й…ҚеҸҰеӨ–дёҖеҲ—пјҡеүҚиҫ№жҸҗеҲ°зҡ„зҙўеј•д№ҹеҸҜз”ЁдәҺжҹҘжүҫжүҖжңү姓дёәAllenпјҢ并且еҗҚеӯ—жҳҜеӯ—жҜҚKејҖеӨҙ(жҜ”еҰӮKim,Karlзӯү)зҡ„дәәгҖӮеҚіз¬¬дёҖеҲ—last_nameе…ЁеҢ№й…ҚпјҢ第дәҢеҲ—first_nameиҢғеӣҙеҢ№й…ҚгҖӮ
еӣ дёәзҙўеј•ж ‘зҡ„иҠӮзӮ№жҳҜжңүеәҸзҡ„пјҢжүҖд»ҘйҷӨдәҶжҢүеҖјжҹҘжүҫд№ӢеӨ–пјҢзҙўеј•иҝҳеҸҜд»Ҙз”ЁдәҺжҹҘиҜўдёӯзҡ„ORDER BYж“ҚдҪң(жҢүйЎәеәҸжҹҘжүҫ)пјҢеҰӮжһңORDER BYеӯҗеҸҘж»Ўи¶іеүҚйқўеҲ—еҮәзҡ„еҮ з§ҚжҹҘиҜўзұ»еһӢпјҢеҲҷиҝҷдёӘзҙўеј•д№ҹеҸҜд»Ҙж»Ўи¶іеҜ№еә”зҡ„жҺ’еәҸйңҖжұӮгҖӮ
дёӢйқўжҳҜдёҖдәӣе…ідәҺB-Treeзҙўеј•зҡ„йҷҗеҲ¶пјҡ
еҰӮжһңдёҚжҳҜжҢүз…§зҙўеј•зҡ„жңҖе·ҰеҲ—ејҖе§ӢжҹҘжүҫпјҢеҲҷж— жі•дҪҝз”Ёзҙўеј•гҖӮдҫӢеҰӮдёҠйқўдҫӢеӯҗдёӯзҡ„зҙўеј•ж— жі•жҹҘжүҫеҗҚеӯ—дёәBillзҡ„дәәпјҢд№ҹж— жі•жҹҘжүҫжҹҗдёӘзү№е®ҡз”ҹж—Ҙзҡ„ж—ҘпјҢеӣ дёәиҝҷдёӨеҲ—йғҪдёҚжҳҜжңҖе·Ұж•°жҚ®еҲ—гҖӮ
еҰӮжһңжҹҘиҜўдёӯжңүжҹҗдёӘеҲ—зҡ„иҢғеӣҙжҹҘиҜўпјҢеҲҷе…¶еҸідҫ§жүҖжңүеҲ—йғҪж— жі•дҪҝз”Ёзҙўеј•дјҳеҢ–жҹҘжүҫгҖӮ
иҒҡз°Үзҙўеј•
иҒҡз°Үзҙўеј•е№¶дёҚжҳҜдёҖз§ҚеҚ•зӢ¬зҡ„зҙўеј•зұ»еһӢпјҢиҖҢжҳҜдёҖз§Қж•°жҚ®еӯҳеӮЁж–№ејҸгҖӮе…·дҪ“зҡ„з»ҶиҠӮдҫқиө–дәҺе…¶е®һзҺ°ж–№ејҸпјҢдҪҶжҳҜInnoDBзҡ„иҒҡз°Үзҙўеј•е®һйҷ…дёҠеңЁеҗҢдёҖдёӘз»“жһ„дёӯдҝқеӯҳдәҶB-Treeзҙўеј•е’Ңж•°жҚ®иЎҢгҖӮ
еҪ“иЎЁжңүиҒҡз°Үзҙўеј•ж—¶пјҢе®ғзҡ„ж•°жҚ®иЎҢе®һйҷ…дёҠеӯҳж”ҫеңЁзҙўеј•зҡ„еҸ¶еӯҗйЎөдёӯпјҢиҝҷд№ҹе°ұжҳҜиҜҙж•°жҚ®иЎҢе’ҢзӣёйӮ»зҡ„й”®еҖјзҙ§еҮ‘ең°еӯҳеӮЁеңЁдёҖиө·гҖӮ
дёӢеӣҫеұ•зӨәдәҶиҒҡз°Үзҙўеј•дёӯзҡ„и®°еҪ•жҳҜеҰӮдҪ•еӯҳж”ҫзҡ„гҖӮжіЁж„ҸеҲ°пјҢеҸ¶еӯҗйЎөеҢ…еҗ«дәҶиЎҢзҡ„е…ЁйғЁж•°жҚ®иЎҢпјҢдҪҶжҳҜиҠӮзӮ№йЎөеҸӘеҢ…еҗ«дәҶзҙўеј•еҲ—гҖӮ
иҒҡз°Үзҙўеј•еҸҜиғҪеҜ№жҖ§иғҪжңүеё®еҠ©пјҢдҪҶд№ҹеҸҜиғҪеҜјиҮҙдёҘйҮҚзҡ„жҖ§иғҪй—®йўҳгҖӮиҒҡз°Үзҡ„ж•°жҚ®жҳҜжңүдёҖдәӣйҮҚиҰҒзҡ„дјҳзӮ№пјҡ
ж•°жҚ®и®ҝй—®жӣҙеҝ«пјҢиҒҡз°Үзҙўеј•е°Ҷзҙўеј•е’Ңж•°жҚ®дҝқеӯҳеңЁеҗҢдёҖдёӘB-TreeдёӯпјҢеӣ жӯӨд»ҺиҒҡз°Үзҙўеј•дёӯиҺ·еҸ–ж•°жҚ®йҖҡеёёжҜ”еңЁйқһиҒҡз°Үзҙўеј•дёӯжҹҘжүҫиҰҒеҝ«гҖӮ
дҪҝз”ЁиҰҶзӣ–зҙўеј•жү«жҸҸзҡ„жҹҘиҜўеҸҜд»ҘзӣҙжҺҘдҪҝз”ЁйЎөиҠӮзӮ№дёӯзҡ„дё»й”®еҖјгҖӮ
еҰӮжһңеңЁи®ҫи®ЎиЎЁе’ҢжҹҘиҜўж—¶иғҪе……еҲҶеҲ©з”ЁдёҠйқўзҡ„дјҳзӮ№пјҢйӮЈд№Ҳе°ұиғҪжһҒеӨ§ең°жҸҗеҚҮжҖ§иғҪгҖӮеҗҢж—¶пјҢиҒҡз°Үзҙўеј•д№ҹжңүдёҖдәӣзјәзӮ№пјҡ
жҸ’е…ҘйЎәеәҸдёҘйҮҚдҫқиө–жҸ’е…ҘйЎәеәҸгҖӮжҢүз…§дё»й”®зҡ„йЎәеәҸжҸ’е…ҘжҳҜеҗ‘InnoDBиЎЁдёӯжҸ’е…Ҙж•°жҚ®йҖҹеәҰжңҖеҝ«зҡ„ж–№ејҸпјҢйңҖиҰҒйҒҝе…Қдё»й”®й”®еҖјйҡҸжңәзҡ„(дёҚиҝһз»ӯдё”еҖјеҫ—еҲҶеёғиҢғеӣҙйқһеёёеӨ§)иҒҡз°Үзҙўеј•пјҢжҜ”еҰӮдҪҝз”ЁUUIDдҪңдёәдё»й”®пјҢиҖҢеә”иҜҘдҪҝз”Ёзұ»дјјAUTO_INCREMENTзҡ„иҮӘеўһеҲ—гҖӮ
жӣҙж–°иҒҡз°Үзҙўеј•еҲ—зҡ„д»Јд»·еҫҲй«ҳпјҢеӣ дёәдјҡејәеҲ¶InnoDBе°ҶжҜҸдёӘиў«жӣҙж–°зҡ„иЎҢ移еҠЁдҪҚзҪ®еҲ°ж–°зҡ„дҪҚзҪ®гҖӮ
еҹәдәҺиҒҡз°Үзҙўеј•зҡ„иЎЁеңЁжҸ’е…Ҙж–°иЎҢпјҢжҲ–иҖ…дё»й”®иў«жӣҙж–°еҜјиҮҙйңҖиҰҒ移еҠЁиЎҢж—¶пјҢеҸҜиғҪйқўдёҙвҖңйЎөеҲҶиЈӮвҖқзҡ„й—®йўҳгҖӮеҪ“иЎҢзҡ„дё»й”®еҖјиҰҒжұӮеҝ…йЎ»е°ҶиҝҷиЎҢжҸ’е…ҘеҲ°жҹҗдёӘе·Іж»Ўзҡ„йЎөдёӯж—¶пјҢеӯҳеӮЁеј•ж“Һдјҡе°ҶиҜҘйЎөеҲҶиЈӮжҲҗдёӨдёӘйЎөйқўжқҘе®№зәіиҜҘиЎҢпјҢиҝҷе°ұжҳҜдёҖж¬ЎйЎөеҲҶиЈӮж“ҚдҪңгҖӮйЎөеҲҶиЈӮдјҡеҜјиҮҙиЎЁеҚ з”ЁжӣҙеӨҡзҡ„зЈҒзӣҳз©әй—ҙгҖӮ
дәҢзә§зҙўеј•еҸҜиғҪжҜ”жғіиұЎзҡ„жӣҙеӨ§пјҢеӣ дёәеңЁдәҢзә§зҙўеј•дёӯзҡ„еҸ¶иҠӮзӮ№еҢ…еҗ«дәҶеј•з”ЁиЎҢзҡ„дё»й”®еҲ—гҖӮ
дәҢзә§зҙўеј•и®ҝй—®йңҖиҰҒдёӨж¬Ўзҙўеј•жҹҘжүҫпјҢиҖҢдёҚжҳҜдёҖж¬ЎгҖӮ
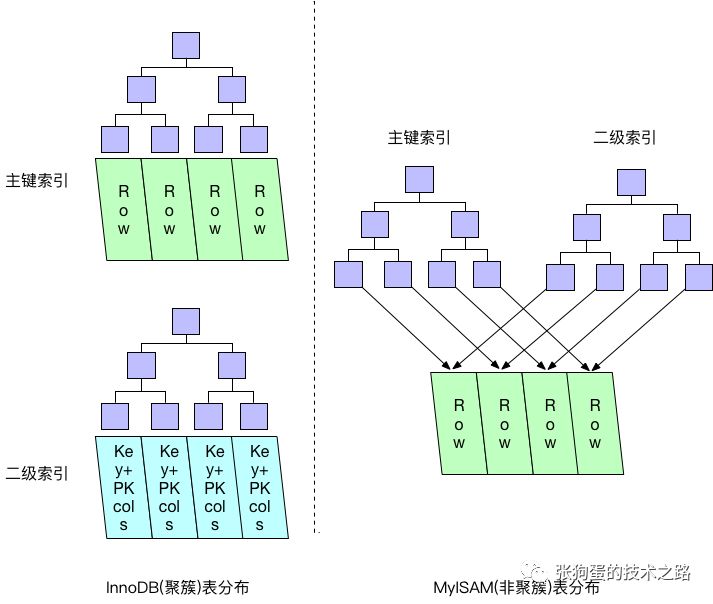
InnoDBе’ҢMyISAMзҡ„зҙўеј•еҢәеҲ«
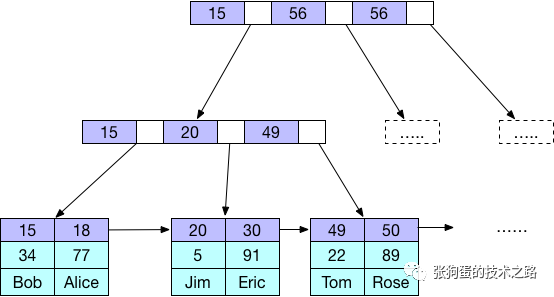
иҒҡз°Үзҙўеј•е’ҢйқһиҒҡз°Үзҙўеј•зҡ„ж•°жҚ®еҲҶеёғжңүеҢәеҲ«пјҢд»ҘеҸҠеҜ№еә”зҡ„дё»й”®зҙўеј•е’ҢдәҢзә§зҙўеј•зҡ„ж•°жҚ®еҲҶеёғд№ҹжңүеҢәеҲ«пјҢйҖҡеёёдјҡи®©дәәж„ҹеҲ°еӣ°жғ‘е’Ңж„ҸеӨ–гҖӮдёӢеӣҫеұ•зӨәдәҶMyISAMе’ҢInnoDBзҡ„дёҚеҗҢзҙўеј•е’Ңж•°жҚ®еӯҳеӮЁж–№ејҸгҖӮ
MyISAMзҡ„ж•°жҚ®еҲҶеёғйқһеёёз®ҖеҚ•пјҢжҢүз…§ж•°жҚ®жҸ’е…Ҙзҡ„йЎәеәҸеӯҳеӮЁеңЁзЈҒзӣҳдёҠпјҢдё»й”®зҙўеј•е’ҢдәҢзә§зҙўеј•зҡ„еҸ¶иҠӮзӮ№еӯҳеӮЁзқҖжҢҮй’ҲпјҢжҢҮеҗ‘еҜ№еә”зҡ„ж•°жҚ®иЎҢгҖӮ
 InnoDBдёӯпјҢиҒҡз°Үзҙўеј•вҖңе°ұжҳҜвҖқиЎЁпјҢжүҖд»ҘдёҚдјҡеғҸMyISAMйӮЈж ·йңҖиҰҒзӢ¬з«Ӣзҡ„иЎҢеӯҳеӮЁгҖӮиҒҡз°Үзҙўеј•зҡ„жҜҸдёӘеҸ¶иҠӮзӮ№йғҪеҢ…еҗ«дәҶдё»й”®еҖје’ҢжүҖжңүзҡ„еү©дҪҷеҲ—(еңЁжӯӨдҫӢдёӯжҳҜcol2)гҖӮ
InnoDBзҡ„дәҢзә§зҙўеј•е’ҢиҒҡз°Үзҙўеј•еҫҲдёҚеҗҢгҖӮInnoDBдәҢзә§зҙўеј•зҡ„еҸ¶иҠӮзӮ№дёӯеӯҳеӮЁзҡ„дёҚжҳҜвҖңиЎҢжҢҮй’ҲвҖқпјҢиҖҢжҳҜдё»й”®еҖјпјҢ并д»ҘжӯӨдҪңдёәжҢҮеҗ‘иЎҢзҡ„вҖңжҢҮй’ҲвҖқгҖӮ
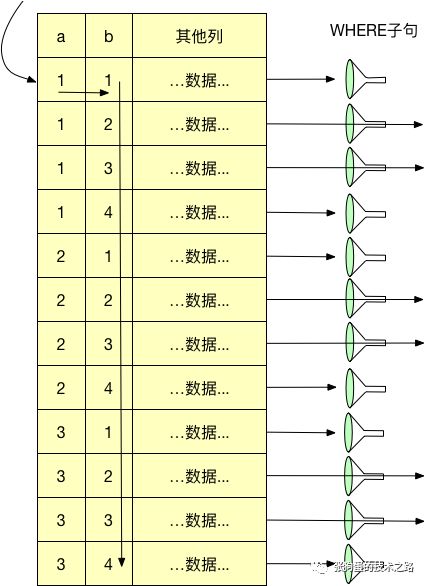
жқҫж•Јзҙўеј•жү«жҸҸ
MySQL并дёҚж”ҜжҢҒжқҫж•Јзҙўеј•жү«жҸҸпјҢд№ҹе°ұжҳҜж— жі•жҢүз…§дёҚиҝһз»ӯзҡ„ж–№ејҸжү«жҸҸдёҖдёӘзҙўеј•гҖӮйҖҡеёёпјҢMySQLзҡ„зҙўеј•жү«жҸҸйңҖиҰҒе…Ҳе®ҡд№үдёҖдёӘиө·зӮ№е’Ңз»ҲзӮ№пјҢеҚідҪҝйңҖиҰҒзҡ„ж•°жҚ®еҸӘжҳҜиҝҷж®өзҙўеј•дёӯеҫҲе°‘ж•°зҡ„еҮ дёӘпјҢMySQLд»Қ然йңҖиҰҒжү«жҸҸиҝҷж®өзҙўеј•дёӯзҡ„жҜҸдёӘжқЎзӣ®гҖӮ
дёӢйқўпјҢжҲ‘们йҖҡиҝҮдёҖдёӘзӨәдҫӢиҜҙжҳҺиҝҷзӮ№пјҢеҒҮи®ҫжҲ‘们жңүеҰӮдёӢзҙўеј•(a,b)пјҢжңүдёӢйқўзҡ„жҹҘиҜўпјҡ

еӣ дёәзҙўеј•зҡ„еүҚеҜјеӯ—ж®өжҳҜеҲ—aпјҢдҪҶжҳҜеңЁжҹҘиҜўдёӯеҸӘжҢҮе®ҡдәҶеӯ—ж®өbпјҢMySQLж— жі•дҪҝз”ЁиҝҷдёӘзҙўеј•пјҢд»ҺиҖҢеҸӘиғҪйҖҡиҝҮе…ЁиЎЁжү«жҸҸжүҫеҲ°еҢ№й…Қзҡ„иЎҢпјҢеҰӮдёӢеӣҫжүҖзӨәгҖӮ
дәҶи§Јзҙўеј•зҡ„зү©зҗҶз»“жһ„зҡ„иҜқпјҢдёҚйҡҫеҸ‘зҺ°иҝҳеҸҜд»ҘжңүдёҖдёӘжӣҙеҝ«зҡ„еҠһжі•жү§иЎҢдёҠйқўзҡ„жҹҘиҜўгҖӮзҙўеј•зҡ„зү©зҗҶз»“жһ„(дёҚжҳҜеӯҳеӮЁеј•ж“Һзҡ„API)жҳҜзҡ„еҸҜд»Ҙе…Ҳжү«жҸҸaеҲ—第дёҖдёӘеҖјеҜ№еә”зҡ„bеҲ—зҡ„иҢғеӣҙпјҢ然еҗҺеҶҚи·іеҲ°aеҲ—第дәҢдёӘдёҚдёҚеҗҢеҖјжү«жҸҸеҜ№еә”зҡ„bеҲ—зҡ„иҢғеӣҙгҖӮдёӢеӣҫеұ•зӨәдәҶеҰӮжһңз”ұMySQLжқҘе®һзҺ°иҝҷдёӘиҝҮзЁӢдјҡжҖҺж ·гҖӮ
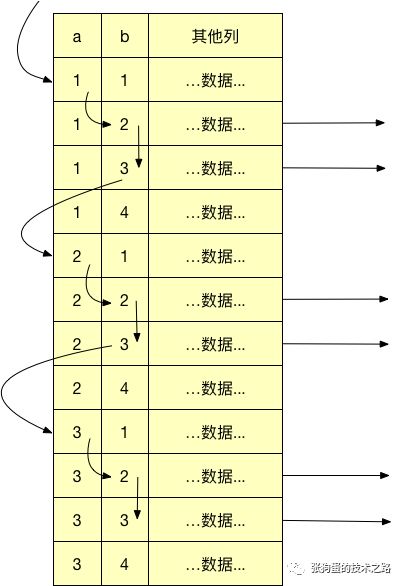
жіЁж„ҸеҲ°пјҢиҝҷж—¶е°ұж— йЎ»еҶҚдҪҝз”ЁWHEREеӯҗеҸҘиҝҮж»ӨпјҢеӣ дёәжқҫж•Јзҙўеј•жү«жҸҸе·Із»Ҹи·іиҝҮдәҶжүҖжңүдёҚйңҖиҰҒзҡ„и®°еҪ•гҖӮ
MySQL 5.0д№ӢеҗҺзҡ„зүҲжң¬пјҢеңЁжҹҗдәӣзү№ж®Ҡзҡ„еңәжҷҜдёӢжҳҜеҸҜд»ҘдҪҝз”Ёжқҫж•Јзҙўеј•жү«жҸҸзҡ„пјҢдҫӢеҰӮпјҢеңЁдёҖдёӘеҲҶз»„жҹҘиҜўдёӯйңҖиҰҒжүҫеҲ°еҲҶз»„зҡ„жңҖеӨ§еҖје’ҢжңҖе°ҸеҖјпјҡ
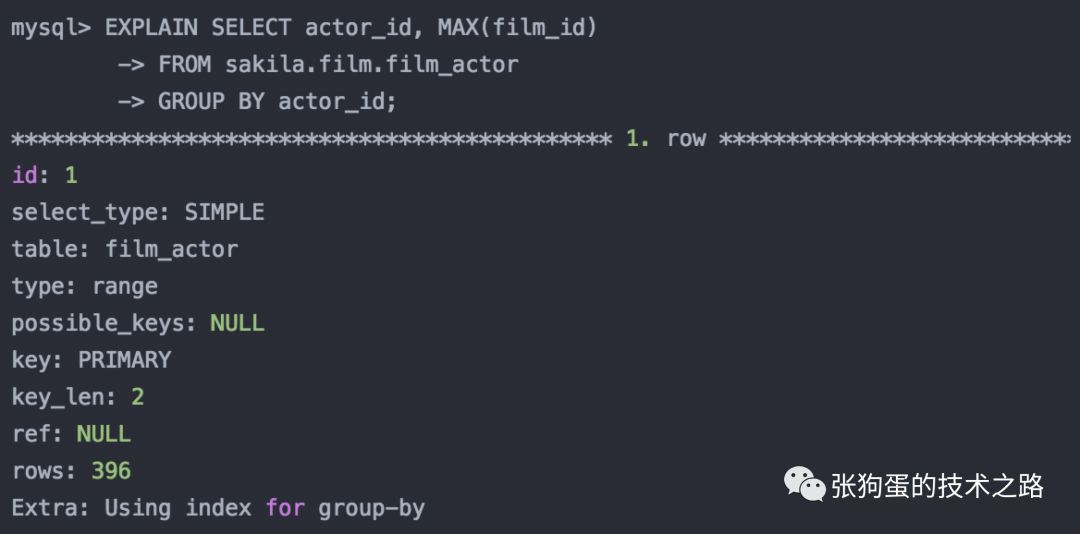
еңЁEXPLAINдёӯзҡ„Extraеӯ—ж®өжҳҫзӨә"Using index for group-by"пјҢиЎЁзӨәиҝҷйҮҢе°ҶдҪҝз”Ёжқҫж•Јзҙўеј•жү«жҸҸгҖӮ
иҰҶзӣ–зҙўеј•
зҙўеј•йҷӨдәҶжҳҜдёҖз§ҚжҹҘжүҫж•°жҚ®зҡ„й«ҳж•Ҳж–№ејҸд№ӢеӨ–пјҢд№ҹжҳҜдёҖз§ҚеҲ—ж•°жҚ®зҡ„зӣҙжҺҘиҺ·еҸ–ж–№ејҸгҖӮMySQLеҸҜд»ҘдҪҝз”Ёзҙўеј•жқҘзӣҙжҺҘиҺ·еҸ–еҲ—зҡ„ж•°жҚ®пјҢиҝҷж ·е°ұдёҚйңҖиҰҒиҜ»еҸ–ж•°жҚ®иЎҢгҖӮеҰӮжһңдёҖдёӘзҙўеј•еҢ…еҗ«жүҖжңүйңҖиҰҒжҹҘиҜўзҡ„еӯ—ж®өзҡ„еҖјпјҢжҲ‘们е°ұз§°д№ӢдёәвҖңиҰҶзӣ–зҙўеј•вҖқгҖӮ
иҰҶзӣ–зҙўеј•жҳҜйқһеёёжңүз”Ёзҡ„е·Ҙе…·пјҢиғҪеӨҹжһҒеӨ§ең°жҸҗй«ҳжҖ§иғҪгҖӮSQLжҹҘиҜўеҸӘйңҖиҰҒжү«жҸҸзҙўеј•иҖҢж— йңҖеӣһиЎЁпјҢдјҡеёҰжқҘеҫҲеӨҡеҘҪеӨ„пјҡ
зҙўеј•жқЎзӣ®ж•°йҮҸе’ҢеӨ§е°ҸйҖҡеёёиҝңе°ҸдәҺж•°жҚ®иЎҢзҡ„жқЎзӣ®е’ҢеӨ§е°ҸпјҢжүҖд»ҘеҰӮжһңеҸӘйңҖиҰҒиҜ»еҸ–зҙўеј•пјҢйӮЈд№ҲMySQLе°ұдјҡжһҒеӨ§ең°еҮҸе°‘ж•°жҚ®и®ҝй—®йҮҸгҖӮ
еӣ дёәзҙўеј•жҳҜжҢүз…§еҲ—йЎәеәҸеӯҳеӮЁзҡ„пјҢжүҖд»ҘеҜ№дәҺI/OеҜҶйӣҶеһӢзҡ„иҢғеӣҙжҹҘжүҫдјҡжҜ”йҡҸжңәд»ҺзЈҒзӣҳиҜ»еҸ–жҜҸдёҖиЎҢж•°жҚ®зҡ„I/OиҰҒе°‘зҡ„еӨҡгҖӮ
з”ұдәҺInnoDBзҡ„иҒҡз°Үзҙўеј•пјҢиҰҶзӣ–зҙўеј•еҜ№InnoDBиЎЁзү№еҲ«жңүз”ЁгҖӮInnoDBзҡ„дәҢзә§зҙўеј•еңЁеҸ¶еӯҗиҠӮзӮ№дёӯдҝқеӯҳдәҶиЎҢзҡ„дё»й”®пјҢзҙўеј•еҰӮжһңдәҢзә§дё»й”®иғҪеӨҹиҰҶзӣ–жҹҘиҜўпјҢеҲҷйҒҝе…ҚеҜ№дё»й”®зҙўеј•зҡ„第дәҢж¬ЎжҹҘиҜўгҖӮ
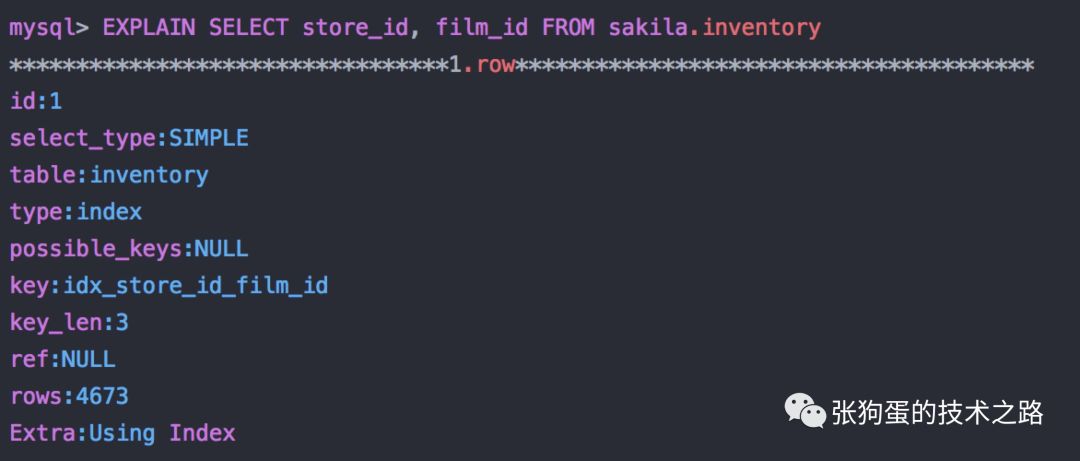
еҪ“еҸ‘иө·дёҖдёӘиў«иҰҶзӣ–зҙўеј•зҡ„жҹҘиҜў(д№ҹеҸ«зҙўеј•иҰҶзӣ–жҹҘиҜў)ж—¶пјҢеңЁEXPLAINзҡ„ExtraеҲ—еҸҜд»ҘзңӢеҲ°"Using Index"зҡ„дҝЎжҒҜгҖӮдҫӢеҰӮпјҢиЎЁsakila.inventoryжңүдёҖдёӘеӨҡеҲ—зҙўеј•(store_id, film_id)гҖӮMySQLеҰӮжһңеҸӘйңҖиҰҒи®ҝй—®иҝҷдёӨеҲ—пјҢе°ұеҸҜд»ҘдҪҝз”ЁиҝҷдёӘзҙўеј•еҒҡиҰҶзӣ–зҙўеј•пјҢеҰӮдёӢжүҖзӨәпјҡ
еҲ°жӯӨпјҢе…ідәҺвҖңMysqlдёӯзҡ„B-Treeзҙўеј•зҡ„еә•еұӮз»“жһ„д»ҘеҸҠдҪҝз”ЁеҺҹеҲҷе’Ңзү№жҖ§вҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ





