本篇内容介绍了“怎么用Python处理上百个表格”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
随意模拟出来两张表为大家解读一下。
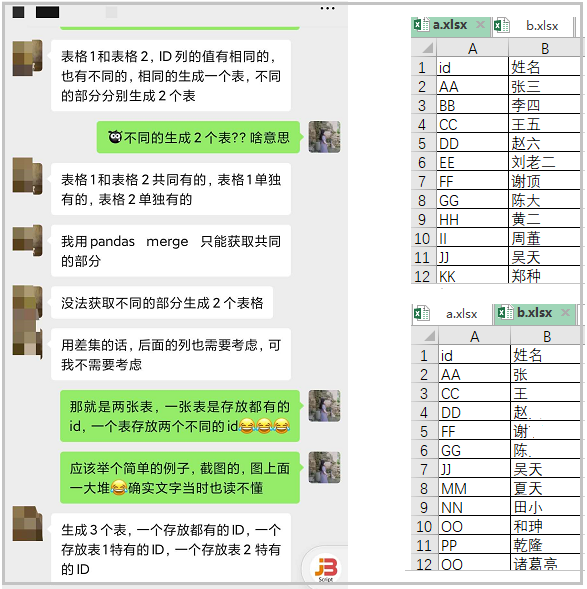
对于上述的a表和b表,我们最终的目的就是:
将a,b表中id相同的数据,写入一个sheet;a表中独有的id行写入一个sheet;b表中独有的id行写入一个sheet。
需要注意以下两点:
① 最终目的是创建一个工作簿,存放三个sheet表;
② 对于id相同的a,b两表,他们的姓名也是不同的,因此存放id相同的那张表,应该是3列。
为了解决这个问题,我们需要先讲述几个知识点,只有掌握了这几个知识点,解决这个问题将会变得灰常简单。
这是Pandas中用于多表连接的函数,相当于Excel中的vlookup()函数,而且又相当于MySQL中的a join b on a.id = b.id内连接。
import pandas as pddf1 = pd.read_excel("a.xlsx")df2 = pd.read_excel("b.xlsx")pd.merge(df1,df2,on="id")结果如下:

ExcelWriter是pandas下面的一个类,里面有两个参数,一个是路径参数Path,一个是时间格式化参数datetime_format。
ExcelWriter的两个作用
① 设置datetime的输出格式;
② 在一个工作簿中写入多个sheet表;
如何使用ExcelWriter
① 构造数据
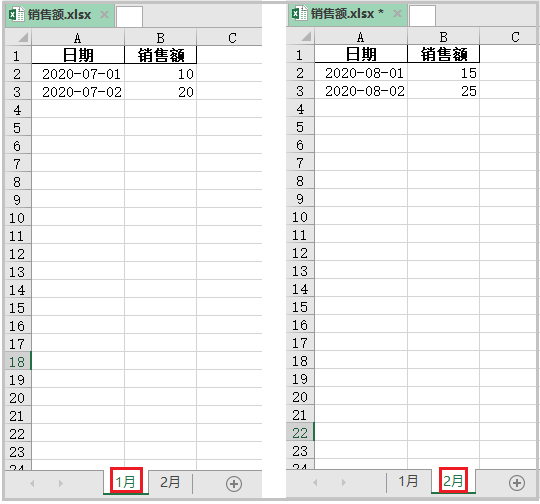
import pandas as pdfrom datetime import datetimedf1 = pd.DataFrame( { "日期":[datetime(2020,7,1),datetime(2020,7,2)], "销售额":[10,20] })df2 = pd.DataFrame( { "日期":[datetime(2020,8,1),datetime(2020,8,2)], "销售额":[15,25] })结果如下:

② ExcelWriter用法如下
# 如果不指定datetime_format参数,你可以试试最终效果。with pd.ExcelWriter("销售额.xlsx",datetime_format="YYYY-MM-DD") as writer: df1.to_excel(excel_writer=writer,sheet_name="1月",index=None) df2.to_excel(excel_writer=writer,sheet_name="2月",index=None)结果如下:
有了上述的基础以后,我这里直接给出本文的代码,估计你看了就能学会的。
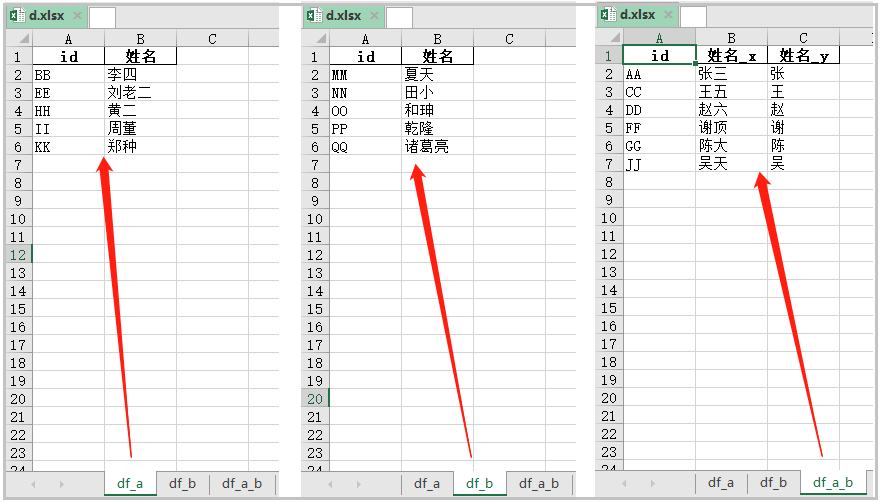
import pandas as pdimport os# 指定路径excel_name = os.getcwd() + "\\d.xlsx"# 读取数据df1 = pd.read_excel("a.xlsx")df2 = pd.read_excel("b.xlsx")# a,b表中共有的df_a_b = pd.merge(df1,df2,on="id")# a表独有的df_a = df1[~df1["id"].isin(df2["id"])]# b表独有的df_b = df2[~df2["id"].isin(df1["id"])]with pd.ExcelWriter(excel_name) as writer: df_a.to_excel(excel_writer=writer,sheet_name="df_a",index=None) df_b.to_excel(excel_writer=writer,sheet_name="df_b",index=None) df_a_b.to_excel(excel_writer=writer,sheet_name="df_a_b",index=None)结果如下:
“怎么用Python处理上百个表格”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4579597/blog/4493482



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



