这篇文章将为大家详细讲解有关Tensorflow中FocalLoss函数如何使用,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
1、FocalLoss介绍
FocalLoss是在交叉熵函数的基础上进行的改进,改进的地方主要在两个地方
(1)、改进第一点如下公式所示。
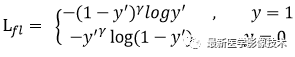
首先在原有交叉熵函数基础上加了一个权重因子,其中gamma>0,使得更关注于困难的、错分的样本。比如:若 gamma = 2,对于正类样本来说,如果预测结果为0.97,那么肯定是易分类的样本,权重值为0.0009,损失函数值就会很小了;对于正类样本来说,如果预测结果为0.3,那么肯定是难分类的样本,权重值为0.49,其损失函数值相对就会很大;对于负类样本来说,如果预测结果为0.8,那么肯定是难分类的样本,权重值为0.64,其损失函数值相对就会很大;对于负类样本来说,如果预测结果为0.1,那么肯定是易分类的样本,权重值为0.01,其损失函数值就会很小。而对于预测概率为0.5时,损失函数值只减少了0.25倍,所以FocalLoss减少了简单样本的影响从而更加关注于难以区分的样本。
(2)、改进第二点如下公式所示。
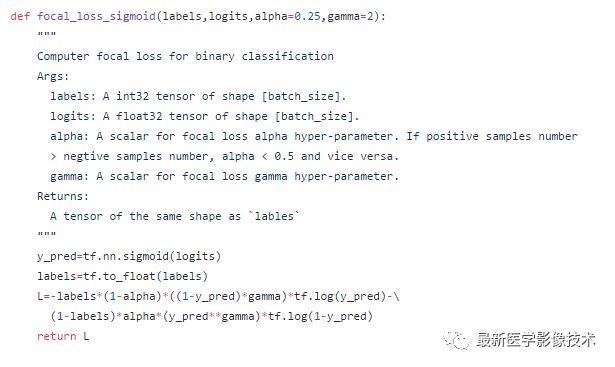
下面将简单推导一下FocalLoss函数在二分类时的函数表达式。
FocalLoss函数可以表示如下公式所示:
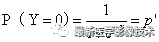
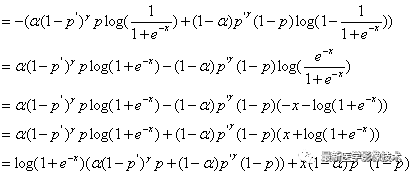
3、FocalLoss代码实现
按照上面导出的表达式FocalLoss的伪代码可以表示为:
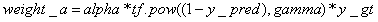

从这里可以看到1-y_pred项可能为0或1,这会导致log函数值出现NAN现象,所以好需要对y_pred项进行固定范围值的截断操作。最后在TensorFlow1.8下实现了该函数。
import tensorflow as tfdef focal_loss(y_true, y_pred, alpha=0.25, gamma=2): epsilon = 1e-5 y_pred = tf.clip_by_value(y_pred, epsilon, 1 - epsilon) logits = tf.log(y_pred / (1 - y_pred)) weight_a = alpha * tf.pow((1 - y_pred), gamma) * y_true weight_b = (1 - alpha) * tf.pow(y_pred, gamma) * (1 - y_true) loss = tf.log1p(tf.exp(-logits)) * (weight_a + weight_b) + logits * weight_b return tf.reduce_mean(loss)关于Tensorflow中FocalLoss函数如何使用就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
亿速云「云服务器」,即开即用、新一代英特尔至强铂金CPU、三副本存储NVMe SSD云盘,价格低至29元/月。点击查看>>
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。
原文链接:https://my.oschina.net/u/4579165/blog/4343991



 计算
计算 安全
安全 数据库
数据库 网络和加速
网络和加速 企业服务
企业服务



